Virtual Memory — 부분 적재부터 페이지 교체·TLB·계층적 페이지 테이블까지
지금까지 메모리 관리는 프로세스 전체가 메모리에 올라가 있다고 가정했다. 하지만 프로그램의 모든 코드와 데이터가 동시에 필요한 경우는 거의 없다. 에러 처리 루틴이나 드물게 호출되는 함수까지 전부 메모리를 차지할 이유가 없다는 뜻이다. 그렇다면 필요한 부분만 메모리에 올리고 나머지는 디스크에 둔 채 실행하면 어떨까. 이 아이디어가 가상 메모리(virtual memory)다.
동기와 근거
프로세스를 부분만 적재해도 실행이 가능한 근거는 지역성(locality)이다. 코드와 데이터 참조는 시간적·공간적으로 한곳에 뭉치는 경향이 있다. 어떤 시점에 실제로 필요한 페이지는 프로세스 전체 중 극히 일부다. Knuth의 추정에 따르면 실행 시간의 90%가 코드의 10%에서 소비된다.
즉, 전체를 올릴 필요 없이 “지금 참조되는 영역”만 메모리에 있으면 대부분의 시간 동안 문제없이 돌아간다. 이 관찰이 가상 메모리가 실제로 동작하는 이유다. 오늘날 거의 모든 OS는 페이징(paging) 또는 페이징 + 세그먼테이션에 기반한 가상 메모리를 핵심 구성요소로 쓴다.
가상 메모리란
가상 메모리는 프로세스가 물리 메모리에 일부만 상주(partially resident)하도록 허용하는 메모리 관리 기법이다. 정확히는 두 가지 개념을 합친다.
- 분산 적재: 프로세스의 페이지들이 물리 메모리 곳곳에 흩어져 배치된다.
- 부분 적재: 프로세스의 일부 페이지만 메모리에 올라가고, 나머지는 보조 저장장치(디스크)에 남는다.
핵심은 보조 저장장치를 마치 주기억장치의 일부인 것처럼 주소 지정할 수 있다는 점이다. 이로부터 세 가지가 따라온다.
- 더 많은 프로세스를 동시에 메모리에 유지할 수 있다.
- 프로세스 크기가 물리 메모리 크기를 초과해도 된다.
- 프로그램 입장에서는 거의 무한한 메모리가 있는 듯한 착각(illusion)을 갖는다.
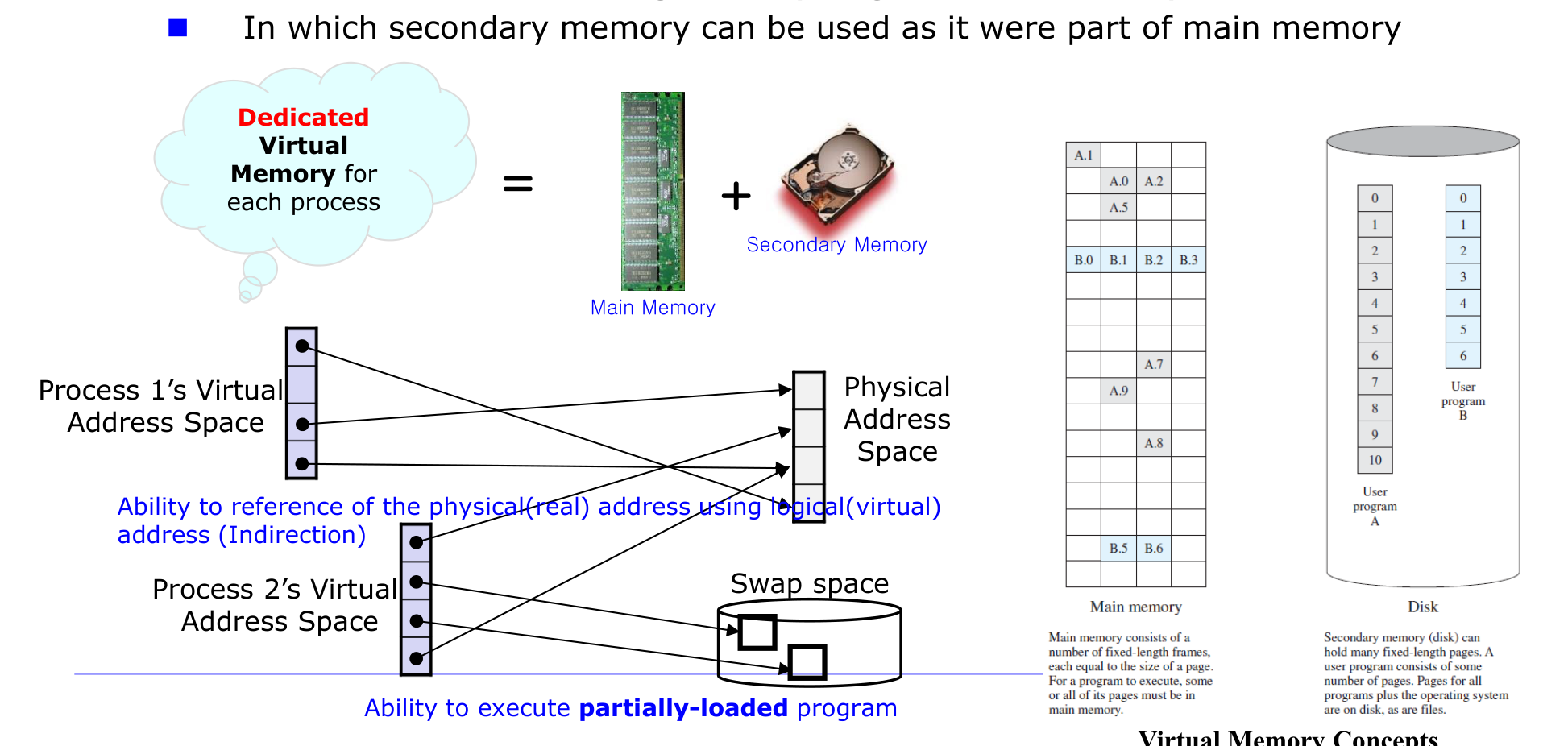
각 프로세스는 자신만의 가상 주소 공간(virtual address space)을 가진다. 이 논리 주소는 간접 참조(indirection)를 거쳐 물리(실제) 주소로 변환되며, 메모리에 없는 페이지는 swap 공간(디스크)에 위치한다. 가상 주소 공간 = 주기억장치 + 보조기억장치인 셈이다.
가상 메모리가 주는 이점
- 더 많은 프로세스 상주: 각 프로그램이 실행 중 더 적은 메모리를 쓰므로 동시 실행 가능한 프로그램 수가 늘어난다.
- 물리 메모리보다 큰 프로세스: 논리 주소 공간이 물리 주소 공간보다 훨씬 클 수 있다.
- 보호와 격리(protection & isolation): 프로그래머가 보는 메모리 관점과 시스템이 보는 관점을 분리한다.
- 효율적인 공유 메모리와 IPC: 동적 라이브러리 같은 공유가 쉬워진다.
- 적재 I/O 감소: 쓰지 않는 부분은 swap-in 하지 않으므로 시간이 절약된다.
가상 메모리를 위한 OS 정책
부분 적재된 페이지 집합을 OS가 어떻게 관리하느냐가 가상 메모리의 성능을 좌우한다. 관리 정책은 다섯 가지 축으로 나뉜다.
| 정책 | 결정하는 것 |
|---|---|
| Fetch Policy (반입 정책) | 페이지를 언제 메모리로 가져올지 |
| Placement Policy (배치 정책) | 페이지를 메모리의 어디에 둘지 |
| Replacement Policy (교체 정책) | 빈 프레임이 없을 때 어떤 페이지를 내보낼지 |
| Resident Set Management (상주 집합 관리) | 프로세스마다 몇 개의 프레임을 줄지 |
| Cleaning Policy (클리닝 정책) | 수정된 페이지를 언제 디스크에 쓸지 |
아래에서 하나씩 본다.
Fetch Policy — 반입 정책
페이지를 언제 메모리로 가져올지 결정한다.
- 요구 페이징(demand paging): 페이지가 실제로 참조될 때만 가져온다. 프로세스 시작 직후에는 페이지 폴트(page fault)가 자주 발생하지만, 시간이 지나면 시스템이 안정화되어 폴트 빈도가 매우 낮은 수준으로 떨어진다.
- 선반입(pre-paging): 예측에 기반해 필요해지기 전에 미리 가져온다. 가져온 페이지가 쓰이지 않으면 I/O 오버헤드와 비효율만 남는다. 보통 다음 페이지들이 순차적으로 접근될 가능성이 높을 때만 쓴다.
현대 OS는 기본적으로 요구 페이징을 쓰되, 상황에 따라 선반입을 결합한다.
Placement Policy — 배치 정책
페이지를 메모리의 어디에 둘지 결정한다.
- 순수 세그먼테이션 시스템에서는 first-fit, next-fit, best-fit 같은 알고리즘이 의미를 갖는다.
- 순수 페이징(또는 페이징 + 세그먼테이션)에서는 배치 정책이 일반적으로 덜 중요하다. 모든 페이지 크기가 같으므로 어떤 페이지든 어떤 프레임에든 들어갈 수 있어, 배치가 성능에 거의 영향을 주지 않는다.
- 단, 이종 메모리(heterogeneous memory)에서는 배치가 다시 관심사가 된다. 대표적으로 NUMA(Non-Uniform Memory Access) 구조가 그렇다.
Replacement Policy — 교체 정책
빈 프레임이 없거나 가용 메모리가 OS가 정한 워터마크(watermark) 아래로 떨어지면, 메모리의 어떤 페이지를 내보낼지(reclaim) 결정해야 한다.
교체 정책의 목표는 가까운 미래에 참조될 가능성이 가장 낮은 페이지를 쫓아내는 것이다. 이는 다음 가정에 기댄다.
- 최근에 사용된 페이지는 곧 다시 사용될 가능성이 높다.
- 최근 사용 이력과 미래 접근 사이에 높은 상관관계가 있다.
- 즉, 과거 행동(past behavior)을 근거로 미래 행동(future behavior)을 예측한다.
그래서 대부분의 정책은 현재 상주 중인 페이지 중 가장 오랫동안 참조되지 않은(least recently used) 페이지를 고르려 한다.
한 가지 제약이 있다. 프레임 잠금(frame locking)이다. 일부 프레임은 잠겨서 교체 대상에서 제외된다. OS는 물리 프레임을 명시적으로 잠그고 푸는 메커니즘을 제공하며, OS 커널의 상당 부분과 핵심 제어 구조는 잠긴 프레임에 보관된다.
Hotness — 페이지의 뜨거움
Hotness는 페이지가 얼마나 최근에(혹은 자주) 접근되었는지를 가리킨다.
- Hot page: 최근에 또는 자주 접근된 페이지. UMA에서는 메모리에 유지하고, NUMA에서는 가까운(로컬) 메모리에 두는 것이 바람직하다.
- Cold page: 최근에 또는 자주 접근되지 않은 페이지. UMA에서는 교체 후보이고, NUMA에서는 먼(원격) 메모리로 보낼 후보다.
여기서 두 가지 관점이 갈린다. LRU는 recency(얼마나 최근)를, LFU는 frequency(얼마나 자주)를 본다.
뜨거운 페이지를 빠른 메모리에 두는 동작은 환경에 따라 이름이 다르다.
- UMA(Uniform Memory Access): cold 페이지는 보조 저장장치로 교체하고 hot 페이지는 주기억장치에 유지한다. 이를 replacement라 한다.
- NUMA: cold 페이지를 원격 메모리로 강등(demote)하고 hot 페이지를 로컬 메모리로 승격(promote)한다. 이를 memory tiering이라 한다.
평가 기준
교체 정책은 성능에 막대한 영향을 준다. 잘못된 선택은 페이지 폴트를 빈번하게 만들고, 이는 곧 디스크 I/O로 이어진다. (페이지 폴트는 프로그램이 현재 메모리에 없는 페이지를 접근할 때 발생하는 예외다.)
두 가지로 평가한다.
- 정확도(accuracy): 총 페이지 폴트 수
- 오버헤드(overhead): 시간 복잡도 또는 평균 실행 시간
아래에서 Optimal, FIFO, LRU, Clock, Enhanced Second-Chance를 차례로 본다.
페이지 폴트 카운팅 규약
알고리즘을 비교하기 전에 셈하는 규칙을 정한다. 이 프로세스에 고정 4 프레임이 할당되었다고 가정한다. 요구 페이징에서 메모리에 없는 페이지를 참조하면 페이지 폴트다.
참조 문자열(reference string)은 프로세스가 참조하는 페이지 번호의 순서다. 예를 들어 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5. 비어 있는 프레임을 채우는 초기 페이지 폴트(프레임 수만큼 발생)는 세지 않는다. 정책 간 차이를 보려는 것이기 때문이다.
Optimal — 최적 교체
가장 오랫동안 사용되지 않을 페이지를 교체한다. 이를 위해서는 미래의 모든 참조를 알아야 하므로 구현이 불가능하다. 하지만 페이지 폴트를 최소(minimum)로 만들기 때문에, 다른 알고리즘을 비교하는 기준선(baseline)이자 하한(lower bound)으로 쓴다. 오프라인 분석 기법으로는 사용 가능하다.
참조 문자열 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5, 4 프레임에서 초기 폴트 이후 추가 폴트 2회가 발생한다.
FIFO — First-In First-Out
버퍼가 꽉 차면 가장 오래된 페이지를 교체한다.
- 장점: 구현이 단순하다.
- 단점: 자주 쓰이는 페이지가 가장 오래된 페이지일 수 있다(가장 나쁜 성능으로 이어짐). 그리고 Belady의 이상 현상(Belady’s anomaly)이 있다.
Belady의 이상 현상은 프레임 수를 늘렸는데 오히려 페이지 폴트가 더 많아지는 현상이다. 직관적으로는 프레임이 많을수록 폴트가 줄어야 하지만, FIFO는 그렇지 않은 경우가 종종 있다.
같은 참조 문자열 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5에서:
| 프레임 수 | 페이지 폴트 |
|---|---|
| 3 프레임 | 3 + 6 |
| 4 프레임 | 4 + 6 |
프레임을 3개에서 4개로 늘렸는데 폴트(초기 제외분)가 줄지 않는다. 이것이 Belady의 이상 현상이다.
LRU — Least Recently Used
가장 오랫동안 참조되지 않은 페이지를 교체한다. 과거를 보고 미래를 근사하는, optimal 정책에 대한 근사다. 다만 구현이 복잡하다.
같은 참조 문자열에서 LRU는 추가 폴트 4회가 발생한다(Optimal 2회, FIFO 6회와 비교).
구현 방식은 두 가지가 대표적이다.
- 비트 시프팅(bit-shifting): 참조될 때마다 페이지에 타임스탬프를 찍는다. 페이지 테이블 엔트리에 참조 시점을 태깅한다.
-
스택(stack): 페이지가 참조될 때마다 스택의 맨 위로 옮긴다.
- 장점: Belady의 이상 현상이 없다. Optimal의 근사다.
- 단점: 모든 참조마다 갱신해야 해서 비싸다.
Clock — Second Chance
LRU의 비용 문제 때문에 등장한 단순화된 근사다. 프레임 집합을 순환 버퍼(circular buffer)로 다룬다.
- 각 프레임에 사용 비트(use bit, reference bit)가 있다. 페이지가 접근되거나 처음 적재될 때 1로 세팅된다.
- 이동 프레임 포인터(moving frame pointer)가 프레임을 원형으로 스캔한다.
빈 프레임이 없을 때 교체 동작은 이렇다.
- 포인터가 현재 프레임의 사용 비트를 확인한다.
- use bit == 1이면 비트를 0으로 지우고(두 번째 기회) 다음 프레임으로 이동한다.
- use bit == 0이면 그 프레임을 교체 대상으로 선택한다.
- 새 페이지가 들어오면 use bit를 1로 초기화한다.
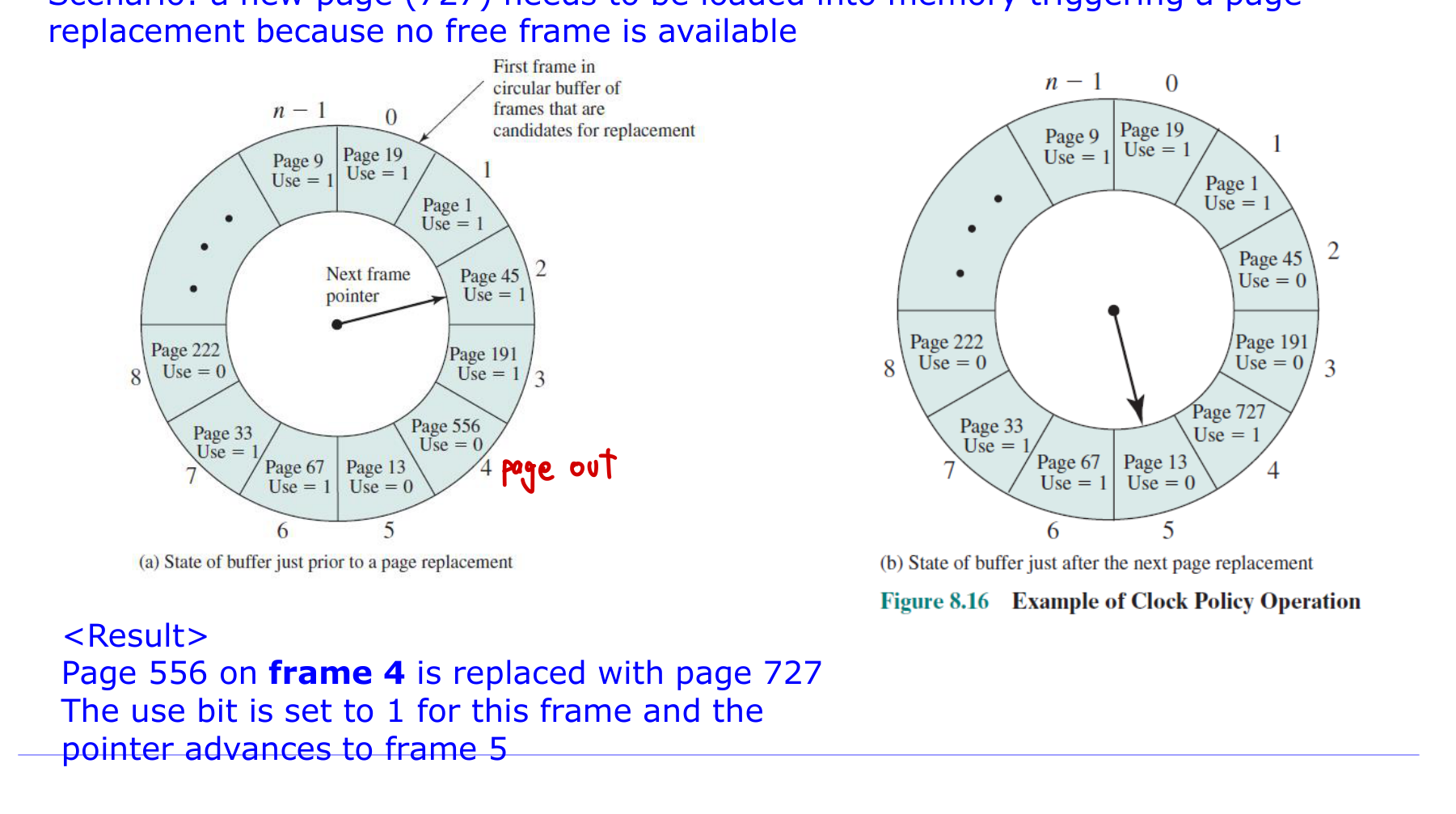
위 예시에서 새 페이지 727을 적재할 때, 포인터가 돌면서 use=1인 페이지들에 두 번째 기회를 주며 비트를 0으로 지운다. 최종적으로 use=0이었던 프레임 4의 페이지 556이 727로 교체되고, 새 프레임의 use 비트는 1이 되며 포인터는 프레임 5로 전진한다.
Enhanced Second-Chance
사용 비트(use)와 수정 비트(modify)를 한 쌍으로 고려한다. 2비트 (use, modify) 조합으로 우선순위를 매긴다.
| (use, modify) | 의미 | 비고 |
|---|---|---|
| (0, 0) | 최근 미사용 + clean | 교체에 가장 적합 |
| (0, 1) | 최근 미사용 + modified | write-out 필요(dirty) → 추가 I/O |
| (1, 0) | 최근 사용 + clean | 곧 다시 쓰일 가능성 |
| (1, 1) | 최근 사용 + modified | 곧 쓰이고 write-out도 필요 |
2단계 스캔(two-step scan)으로 동작한다.
- 1차 스캔: (0,0) 페이지를 찾되 use 비트는 건드리지 않는다.
- 2차 스캔: (0,1) 페이지를 찾으면서 지나친 use 비트를 0으로 지운다.
- 교체 가능한 페이지를 찾을 때까지 반복한다(use=1인 페이지는 수정됨).
수정된(dirty) 페이지를 우선적으로 남겨두어 필요한 I/O 횟수를 줄이는 것이 핵심이다.
알고리즘 비교
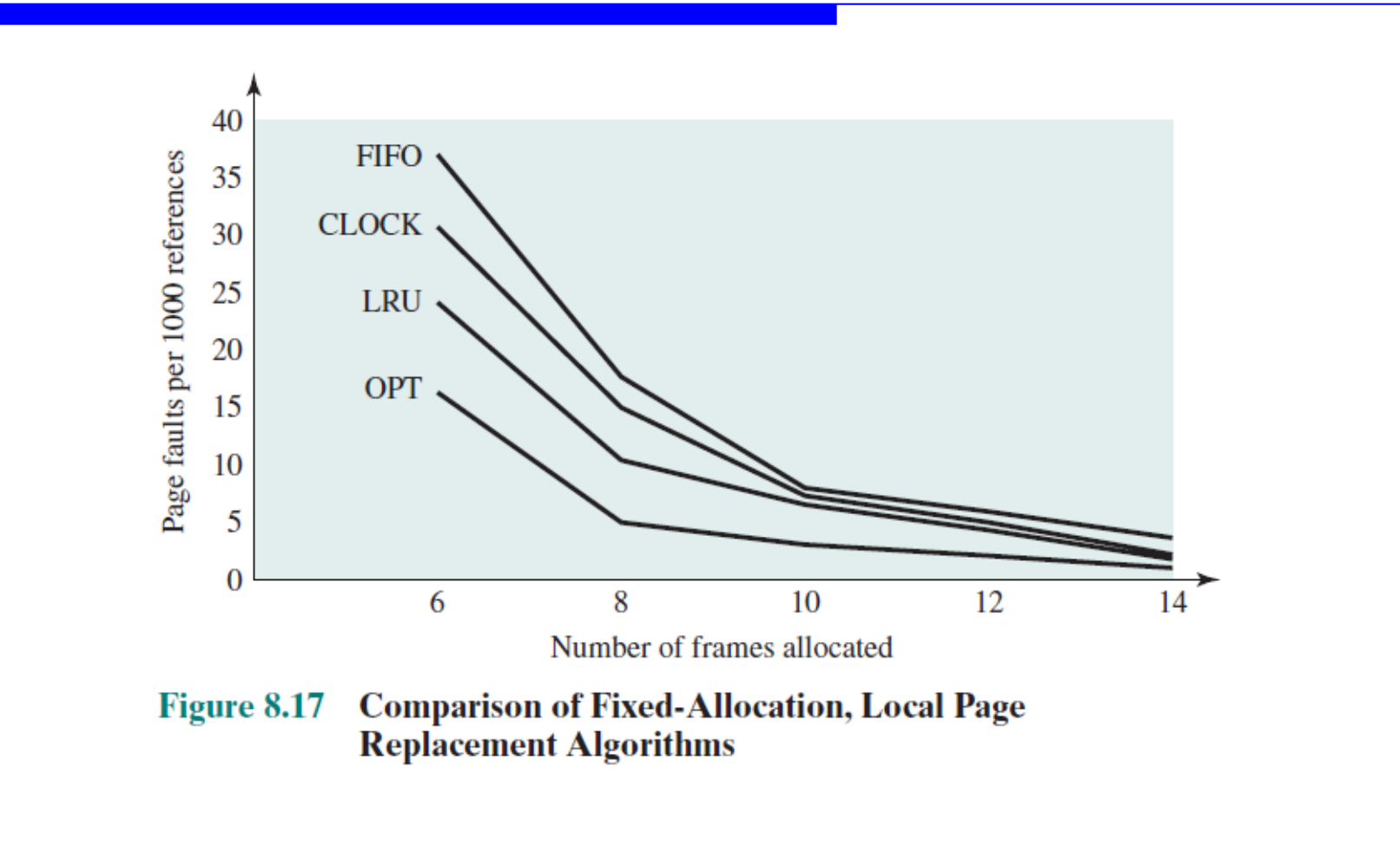
같은 프레임 수에서 페이지 폴트는 대체로 OPT < LRU < CLOCK < FIFO 순으로 적다. 프레임 수가 충분히 커지면 차이는 줄어든다.
옛 OS들의 LRU 근사
정확한 LRU는 모든 메모리 접근을 추적해야 하므로 사실상 불가능하다. 그래서 대부분의 OS는 진짜 LRU 대신 근사 알고리즘을 썼다.
- BSD 4.3: 타이머 인터럽트로 주기적으로 각 페이지의 ACCESSED 비트를 스캔하고 지운다. 다음 스캔에서 ACCESSED=1이면 최근 사용되었으므로 age=0, ACCESSED=0이면 age를 증가시킨다. age가 가장 큰 페이지가 reclaim 대상이 된다.
- System V: 가용 메모리가 부족할 때만 동작한다. 이동하는 clock hand로 순환 큐를 스캔해, ACCESSED=1이면 비트를 지우고 건너뛰며(두 번째 기회), ACCESSED=0이면 즉시 reclaim한다.
Linux 5.x의 2Q LRU
단일 큐 LRU에는 문제가 있다.
- 딱 한 번 접근된 페이지가 오래 메모리에 남을 수 있다.
- 순차 스캔이 일시적으로 쓰인 페이지로 캐시를 오염시킨다.
- 단일 LRU 큐는 일시적 접근과 자주 재사용되는 페이지를 구분하지 못한다.
2Q LRU는 큐를 둘로 나눠 이 문제를 푼다.
- 새로 폴트된 페이지는 먼저 inactive 큐로 들어간다(reclaim 후보).
- 다시 접근되면 active 큐로 승격된다(자주 재사용되는 페이지).
이렇게 일회성 접근 페이지와 빈번히 재사용되는 페이지를 분리한다.
File-backed vs Anonymous
Linux는 페이지를 성격에 따라 구분한다.
- File-backed 페이지: 실행 코드·데이터처럼 일반 파일시스템 파일이 뒷받침하는 페이지(clean). clean하면 디스크 I/O 거의 없이 내보낼 수 있고, 필요하면 원본 파일에서 다시 읽으면 된다.
- Anonymous 페이지: 파일이 뒷받침하지 않고 swap을 쓰는 페이지(힙, 스택 등). reclaim하려면 보통 swap-out I/O가 필요하다. anonymous 페이지는 보통 file-backed보다 강한 시간 지역성을 보이므로 처음부터 active 리스트에 넣는다.
- Unevictable 페이지: 정상적인 reclaim에서 제외되는 페이지.
여기서 swappiness가 등장한다. swappiness는 file-backed 페이지를 reclaim할지 anonymous 페이지를 swap할지의 균형을 조절하는 커널 파라미터다. swappiness가 낮으면 Linux는 anonymous보다 file-backed 페이지 reclaim을 선호한다.
Promotion과 Demotion
2Q LRU에서 inactive/active 리스트는 다음 규칙으로 관리된다.
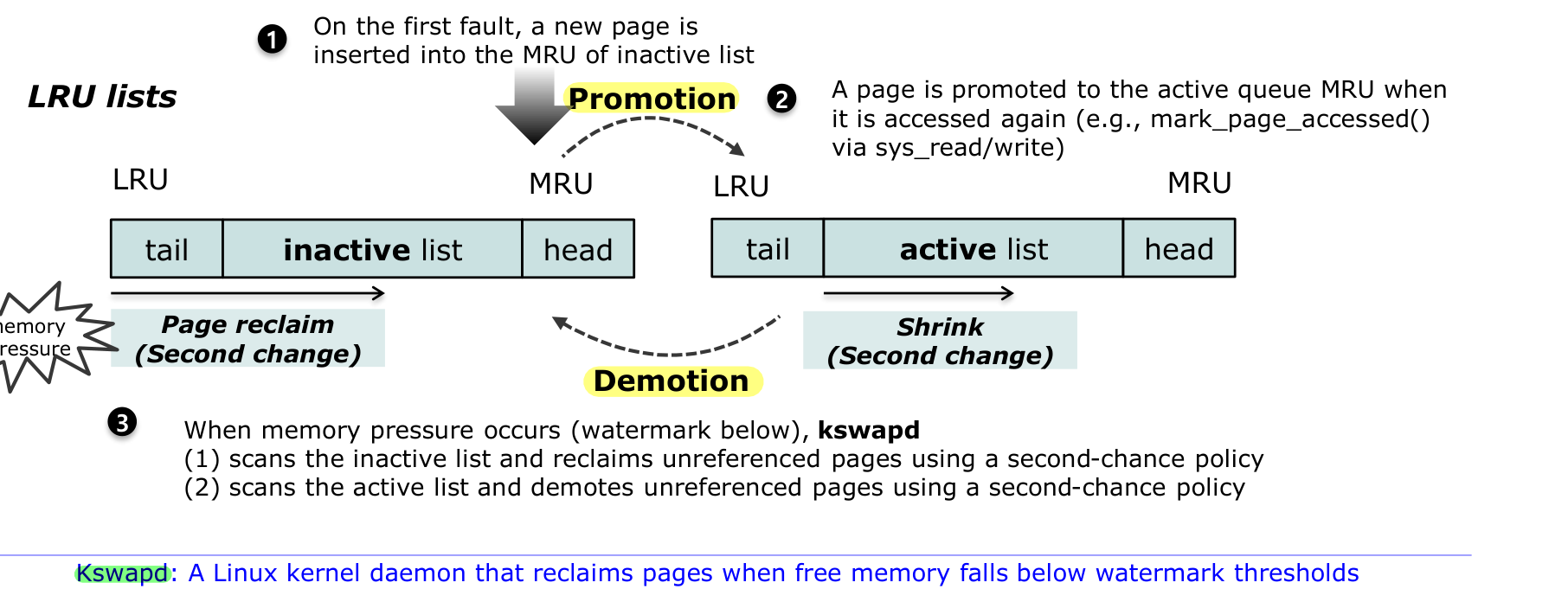
- 새 페이지는 inactive 리스트의 MRU 쪽으로 삽입된다.
- 다시 접근된 페이지는 inactive → active로 승격(promotion)된다.
- 메모리 압박이 생기면 Linux는 active 페이지를 줄이고(shrink) cold inactive 페이지를 second-chance 정책으로 reclaim한다.
메모리 압박(워터마크 아래)이 발생하면 kswapd가 동작한다. kswapd는 가용 메모리가 워터마크 임계값 아래로 떨어질 때 페이지를 reclaim하는 Linux 커널 데몬이다. kswapd는 (1) inactive 리스트를 스캔해 참조되지 않은 페이지를 reclaim하고, (2) active 리스트를 스캔해 참조되지 않은 페이지를 demote한다.
Refault distance
새로 폴트된 페이지는 inactive 리스트로 들어간다. 그런데 한 번 쫓겨났다가 다시 폴트된(refault) 페이지도 inactive에서 시작해야 할까. Linux는 그 eviction이 옳았는지 추정해서 판단한다.
판단 척도가 refault distance다.
\[\text{Refault distance} = (R - E) + nr\_inactive(t_r)\]- refault distance가 작으면 페이지가 빨리 재사용된 것이고, 원래 active 리스트에 속했어야 했다는 뜻이다.
- refault distance가 크면 오랫동안 안 쓰였으므로 좋은 eviction 후보였다는 뜻이다.
조건 $\text{Refault distance} < nr_active(t_r) + nr_inactive(t_r)$ 를 만족하면, 즉 큐 전체 길이 안에 들어오면 곧바로 active 리스트로 보낼 수 있다. eviction 시점의 페이지 활동 정보는 shadow(xarray 키-값 엔트리)에 저장해 둔다.
Cleaning Policy — 클리닝 정책
페이지 교체는 원래 두 번의 I/O가 필요하다. 내보낼 페이지를 디스크에 쓰는 page-out, 새 페이지를 읽어오는 page-in이다. 그런데 내보낼 페이지가 수정되지 않았다면(clean) 디스크에 다시 쓸 필요가 없어 I/O 한 번으로 끝난다.
그래서 페이지가 수정되었는지 추적하는 것이 중요하다. 수정 비트(modify/dirty bit)가 그 역할을 한다. 클리닝 정책은 수정된 페이지를 언제 디스크에 쓸지 결정한다.
- 선청소(pre-cleaning): 페이지를 미리 디스크에 써둔다.
- 장점: 교체 시점의 지연을 줄인다(I/O 한 번).
- 단점: 자주 쓰기 접근되는 페이지는 clean하게 만들어도 곧 다시 dirty가 되어 I/O를 낭비한다.
- 요구 청소(demand cleaning): 교체 대상으로 선택될 때만 디스크에 쓴다.
- 장점: 불필요한 쓰기를 줄이고 구현이 단순하다.
- 단점: 교체 시점에 높은 지연이 생길 수 있다.
- 페이지 버퍼링(page buffering): 즉시 디스크에 쓰지 않고 페이지 버퍼에 둔다. 곧 재사용되는 경우 불필요한 디스크 I/O를 줄일 수 있다.
Resident Set Policy — 상주 집합 관리
상주 집합(resident set)은 어떤 시점에 실제로 주기억장치에 올라가 있는 프로세스의 페이지들이다. 상주 집합 정책은 프로세스마다 몇 개의 프레임을 할당할지 정한다.
- 고정 할당(fixed-allocation): 프로세스에 고정된 수의 프레임을 준다. 새 페이지가 필요하면 그 프로세스의 페이지 중 하나를 반드시 교체한다.
- 가변 할당(variable-allocation): 프로세스에 할당하는 프레임 수를 시간에 따라 변동시킨다.
여기에 교체 범위(replacement scope)가 결합된다.
| Local Replacement | Global Replacement | |
|---|---|---|
| Fixed Allocation | 프레임 수 고정, 교체 페이지는 그 프로세스 프레임 중에서 선택 | 불가능 |
| Variable Allocation | working set 유지를 위해 프레임 수를 조정, 교체는 그 프로세스 내에서 | 교체 페이지를 메모리 전체에서 선택, 프로세스별 상주 집합 크기가 변동 |
Thrashing — 스래싱
주기억장치에 상주시킬 프로세스 수를 정하는 문제와 직결된다. 멀티프로그래밍 수준(동시 실행 프로세스 수)이 올라가면 처음에는 CPU 이용률이 오른다. 하지만 너무 많은 프로세스가 상주하면, 평균적으로 각 프로세스의 상주 집합이 부족해져 페이지 폴트가 빈번해진다.
스래싱(thrashing)은 프로세스가 실행보다 페이징에 더 많은 시간을 쓰는 상태다. 멀티프로그래밍 수준이 어느 지점을 넘으면 CPU 이용률이 급격히 떨어진다.
스래싱을 막으려면 프로세스에 필요한 만큼의 프레임을 줘야 한다. 문제는 “얼마가 필요한지”를 어떻게 아느냐다.
Working Set Model
Peter Denning의 working set 모델은 지역성 가정에 기반한다. 시점 $t$에서 윈도우 크기 $\Delta$ 동안 참조된 페이지 집합을 working set으로 정의한다.
\[W_i(t, \Delta) = \text{직전 } \Delta \text{ 동안 참조된 페이지 집합}\]- $\Delta$는 시간 윈도우 크기다($t$는 참조 횟수로 측정).
-
$1 \le W_i(t, \Delta) \le \min(N, \Delta)$ - $W(t, \Delta) \subseteq W(t, \Delta + 1)$ — 윈도우가 커지면 집합도 커진다(혹은 같다).
정책은 이렇다. working set에 속하지 않는 페이지를 상주 집합에서 주기적으로 제거한다. 더 이상 쓰이지 않는 페이지는 마지막 참조 후 $\Delta$ 시간이 지나면 working set에서 빠진다. 본질적으로 LRU 정책이며, 프로세스마다 시간 순서 큐를 유지해야 한다.
현실적 문제가 있다.
- 프로세스마다 working set을 실제로 측정하는 것은 비현실적이다.
- 최적의 $\Delta$ 값을 알 수 없다. $\Delta$가 너무 작으면 지역성을 다 담지 못하고, 너무 크면 여러 지역성이 겹친다. 극단적으로 $\Delta$가 무한하면 working set은 프로세스 실행 중 접근한 모든 페이지가 된다.
Page-Fault Frequency (PFF)
working set 전략을 근사하는 또 다른 방법으로, 페이지 폴트 빈도(PFF) 자체에 초점을 맞춘다. 두 개의 임계값(상한·하한)으로 “허용 가능한” 폴트율을 유지한다.
- 실제 폴트율이 상한보다 높으면: 프로세스에 프레임을 더 준다.
- 실제 폴트율이 하한보다 낮으면: 프로세스에서 프레임을 회수한다.
가상 메모리를 위한 하드웨어·제어 구조
가상 메모리는 하드웨어 지원 없이는 동작하지 않는다.
페이지 테이블 베이스 레지스터와 PTE
- 페이지 테이블 베이스 레지스터(PTBR): 예를 들어 x86의
cr3. 페이지 테이블 전체를 레지스터에 담을 수는 없으므로, 페이지 테이블은 주기억장치에 두고 PTBR이 현재 프로세스의 페이지 테이블 주소를 가리킨다. - 페이지 테이블 엔트리(PTE): 프로세스의 일부 페이지만 메모리에 있을 수 있으므로 상태 비트가 필요하다.
- 존재 비트(present/valid bit, P): 해당 페이지가 메모리에 있는지 여부. P=0이면 메모리에 없으므로 페이지 폴트 처리가 필요하다.
- 수정 비트(modified/dirty bit, M): 마지막 적재 이후 페이지 내용이 변경되었는지 여부. M=0이면 메모리에서 변경되지 않았으므로 교체 시 디스크에 다시 쓸 필요가 없다.
TLB — Translation Lookaside Buffer
페이지 테이블이 메모리에 있다는 것은, 주소 변환마다 메모리 접근이 추가된다는 뜻이다. 즉 MMU가 메모리를 두 번 접근할 수 있다(페이지 테이블 한 번 + 실제 데이터 한 번). 이 성능 저하를 막기 위해 PTE를 캐싱하는 작은 하드웨어 캐시가 TLB다.
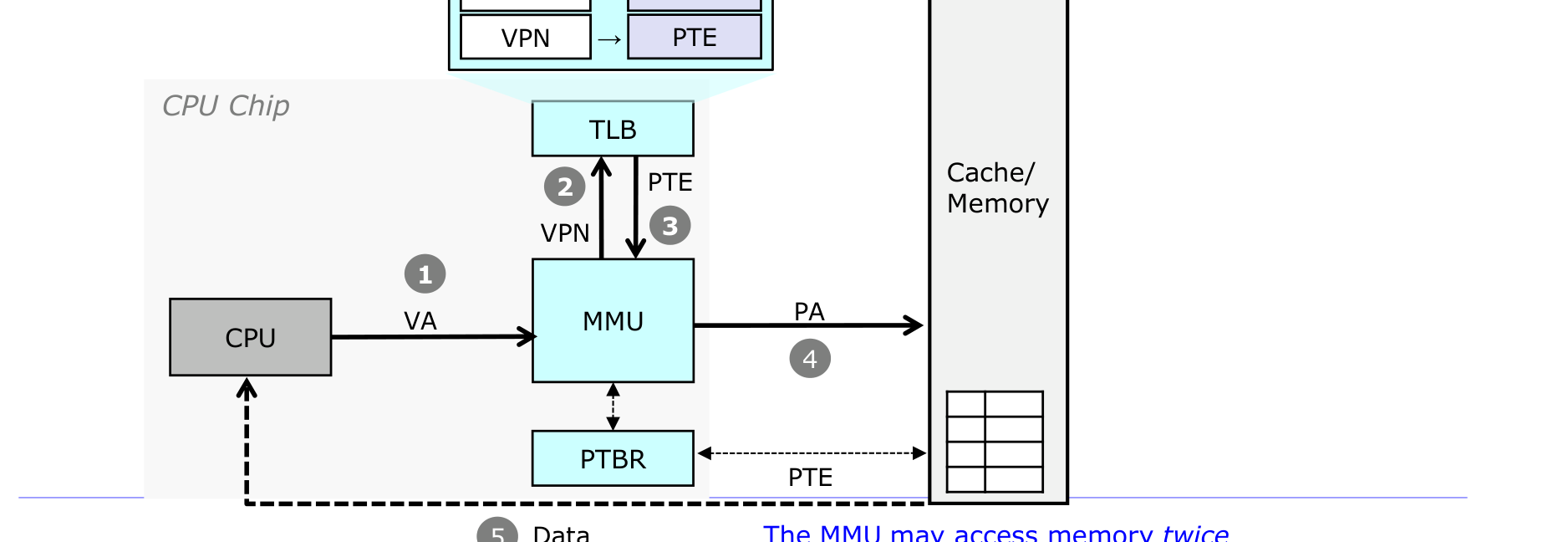
- TLB는 PTE를 캐싱하는 작은 하드웨어 캐시다(현대 Intel 프로세서는 128~256 엔트리).
- 메모리에서 페이지 테이블을 조회하는 것보다 훨씬 빠르다.
변환 과정은 이렇다. 입력은 페이지 번호, 출력은 프레임 번호다.
- TLB Hit: 변환을 가져와 프레임 번호를 반환한다.
- TLB Miss: 메모리의 페이지 테이블을 확인한다.
- present 비트 = 1: 페이지 테이블 엔트리를 TLB에 적재하고 프레임 번호를 반환한다.
- present 비트 = 0: 페이지 폴트 예외가 발생한다.
주소 변환 흐름
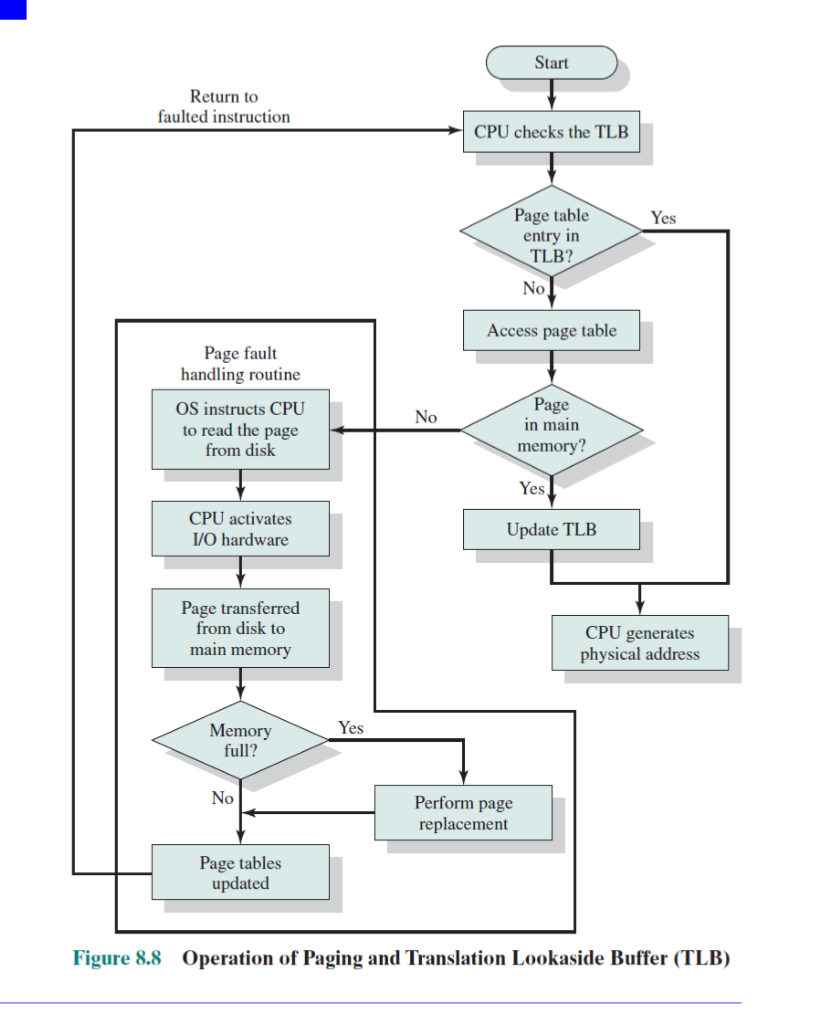
MMU가 페이지 폴트 예외를 일으키면 다음 순서로 처리된다.
- CPU가 I/O 요청을 시작한다.
- 디스크에서 메모리로 페이지를 옮긴다(메모리가 꽉 찼으면 페이지 교체 수행).
- 해당 페이지 테이블 엔트리를 갱신한다.
- 엔트리를 TLB에 적재한다.
Context Switch와 ASID
TLB에는 컨텍스트 스위치 문제가 있다. 프로세스마다 페이지 테이블이 다르므로, 컨텍스트 스위치가 일어나면 직전 프로세스의 TLB 변환 정보는 의미가 없어진다. 같은 가상 페이지 번호(VPN 10)가 프로세스마다 다른 물리 프레임을 가리키기 때문이다.
두 가지 해법이 있다.
- Solution 1 — Flush: 모든 valid 비트를 0으로 만든다. 단순하지만 컨텍스트 스위치마다 TLB miss가 발생해 비용이 크다.
- Solution 2 — ASID(Address Space Identifier): 프로세스 식별자(PID)처럼 생각할 수 있다. TLB가 서로 다른 프로세스의 변환을 동시에 보유할 수 있게 해, flush 없이 구분한다.
가상 메모리 이슈
페이지 크기
페이지 크기를 키우면 어떻게 될까.
- 페이지 테이블 엔트리 수가 줄어든다(예: 1M 엔트리 → 256K 엔트리).
- 페이지 테이블 크기가 작아진다.
하지만 문제도 생긴다.
- 페이지 내부 낭비, 즉 내부 단편화(internal fragmentation)가 커진다.
- 큰 페이지로 메모리가 빨리 채워진다.
실제 페이지 크기는 아키텍처마다 다르다. 4 KB(IBM 370, Pentium, POWER)가 흔하고, MIPS·Itanium처럼 4 KB ~ 수십·수백 MB 범위를 지원하는 경우도 있다.
더 빠른 변환
페이지 테이블 접근에 따른 추가 메모리 접근이 성능을 떨어뜨린다는 문제는 앞서 본 TLB로 PTE를 캐싱해서 해결한다. 컨텍스트 스위치 시 TLB 처리는 ASID로 해결한다(위 참조).
더 작은 테이블
페이지 테이블 자체가 메모리를 너무 많이 쓰는 문제가 있다.
32비트 컴퓨터에 4 KB 페이지면 $2^{20}$개의 엔트리가 필요하다. PTE가 4 B라면 페이지 테이블은 $2^{20} \times 4 = 4\text{ MB}$가 된다. 프로세스마다 자기 페이지 테이블이 있어야 하므로, 프로세스가 100개면 400 MB다.
64비트로 가면 상황은 훨씬 심각하다. 해법은 세 가지다.
결합 세그먼테이션 + 페이징
각 사용자 주소 공간을 여러 세그먼트로 나누고, 각 세그먼트를 다시 고정 크기 페이지로 나눈다.
- 세그먼트 테이블: Base(해당 세그먼트의 페이지 테이블 위치), Bound(페이지 테이블 엔트리 수), 그리고 공유·보호용 제어 비트를 담는다.
- PTE는 순수 페이징과 본질적으로 같다.
- 장점: 페이지 테이블의 메모리 오버헤드를 줄이고, 메모리 할당을 단순화하며, 외부 단편화가 없다(내부 단편화는 존재).
- 단점: 순수 페이징보다 복잡도가 훨씬 높다(MMU 지원 필요).
계층적 페이징(Hierarchical Paging)
페이지 테이블을 페이지 크기 단위의 작은 청크들로 나눈다. 어떤 PTE 페이지 전체가 invalid라면 그 청크는 아예 할당하지 않는다.
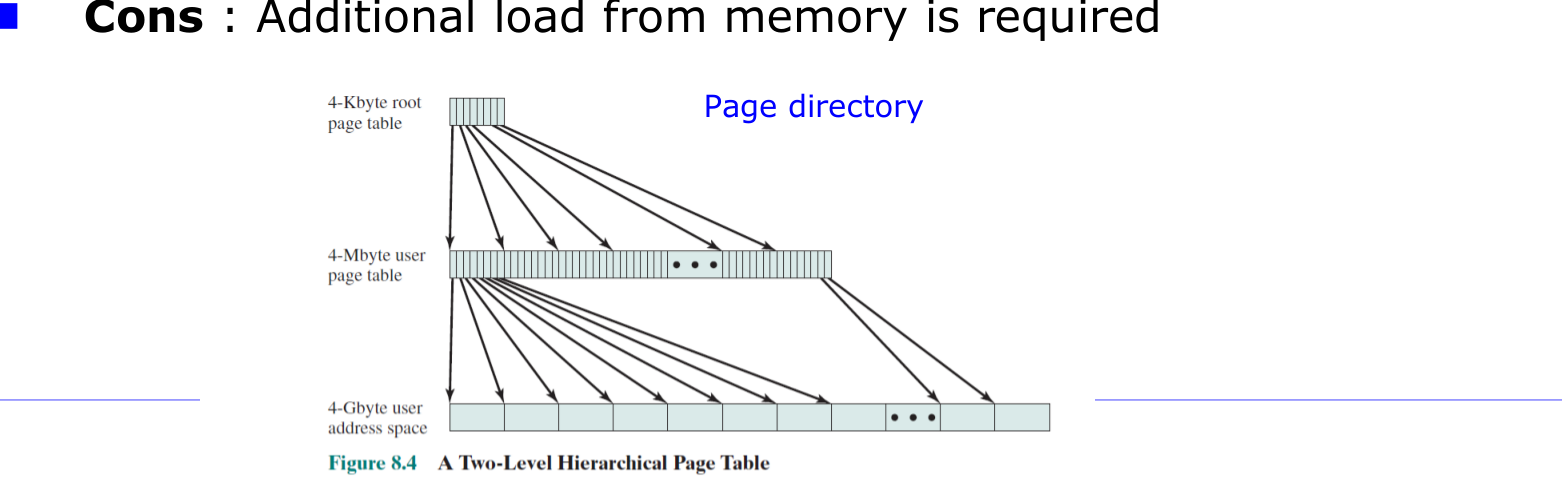
- 2단계 페이지 테이블(64비트 CPU에서는 4단계)을 쓴다.
- 페이지 테이블 자체도 페이징된다.
- 장점: 낭비가 적다(할당 공간이 실제 사용하는 주소 공간 크기에 비례). 페이지 테이블이 물리 메모리에서 연속일 필요가 없다.
- 단점: 메모리에서 추가 적재(상위 테이블 조회)가 필요하다.
역 페이지 테이블(Inverted Page Tables)
메모리 프레임마다 하나의 엔트리를 둔다.
- PTE 수 == PFN 수. 가상 페이지마다가 아니라 실제 메모리 프레임마다 엔트리가 하나씩 있다.
- 프레임 번호를 인덱스로 쓴다. 시스템 전체에 페이지 테이블이 하나뿐이다.
- 각 엔트리는 페이지 번호와 그 페이지를 소유한 PID를 담는다.
- 장점: 페이지 테이블 저장에 필요한 메모리가 줄어든다.
- 단점: 페이지 참조 시 테이블을 검색하는 시간이 늘어난다. 이를 한 번으로 제한하기 위해 해시 테이블을 사용한다.
정리
가상 메모리의 출발점은 “프로세스를 통째로 올리지 않아도 된다”는 지역성 관찰이다. 부분 적재된 페이지 집합을 OS는 반입·배치·교체·상주 집합·클리닝의 다섯 정책으로 관리한다. 교체 알고리즘은 Optimal을 하한 기준으로 FIFO·LRU·Clock·Enhanced Second-Chance가 트레이드오프를 달리하며, Linux는 2Q LRU와 refault distance로 일회성 접근과 재사용을 구분한다. 상주 집합이 부족하면 스래싱이 발생하므로 working set과 PFF로 프레임 수를 조절한다. 이 모든 것은 PTBR·PTE·TLB라는 하드웨어 위에서 동작하며, 페이지 테이블의 메모리 부담은 계층적 페이징과 역 페이지 테이블로 덜어낸다.