TCP Congestion Control — AIMD, Slow Start, Tahoe vs Reno
흐름 제어(flow control)는 수신자 하나가 송신자를 따라가지 못해 발생하는 문제를 해결한다. 그러나 인터넷에서는 송신자가 많아질수록 라우터 큐가 차오르고 패킷이 버려진다. 송신자가 직접 막아야 할 다른 문제, 곧 혼잡(congestion)이 존재한다는 뜻이다.
혼잡의 정의와 징후
비공식적인 정의는 단순하다. 너무 많은 소스가 너무 많은 데이터를 너무 빠르게 보내는 상태다. 네트워크 입장에서 이는 두 가지 형태로 드러난다.
- 긴 지연: 라우터 버퍼에 패킷이 쌓이며 큐잉 지연이 폭발한다.
- 패킷 손실: 버퍼가 넘치면 라우터가 패킷을 버린다.
흐름 제어와의 구분이 중요하다. 흐름 제어는 단일 송수신자 쌍의 속도 차이를 다루고, 혼잡 제어는 다수 송신자가 만들어내는 네트워크 내부 압력을 다룬다.
Scenario 1 — 무한 버퍼, 손실 없음
가장 단순한 모델이다. 라우터 하나, 양쪽 링크 용량 $R$, 두 플로우, 재전송 없음.
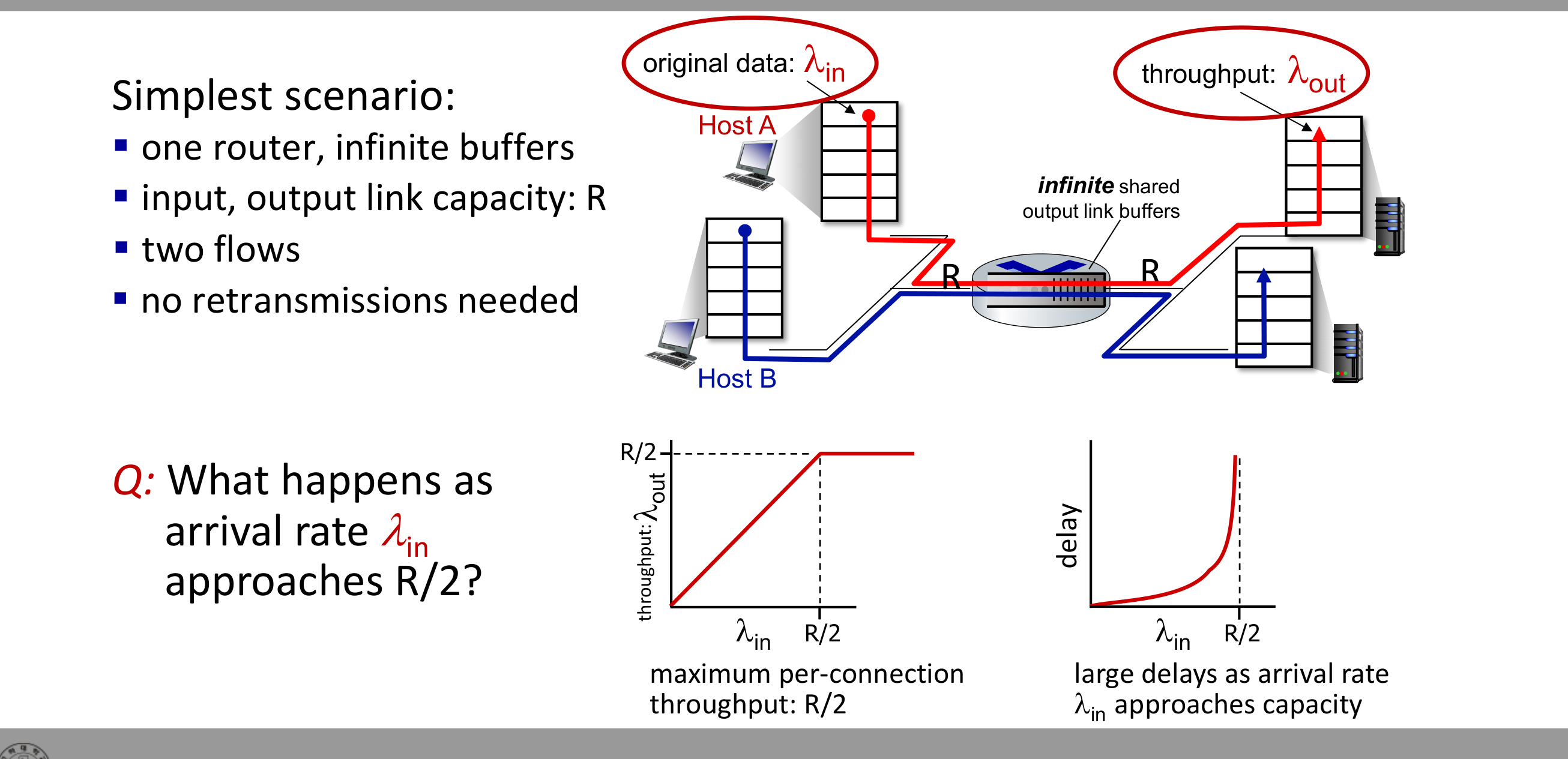
송신 속도 $\lambda_{in}$이 $R/2$까지는 처리량 $\lambda_{out} = \lambda_{in}$으로 따라온다. $R/2$를 넘는 순간 출력은 $R/2$에서 멈추고 지연은 무한대로 발산한다. 직관은 단순하다. 연결당 최대 처리량은 $R/2$를 넘을 수 없다.
Scenario 2 — 유한 버퍼, 재전송 포함
현실에서는 버퍼가 유한하고 손실된 패킷은 재전송된다. 송신자가 트랜스포트 계층으로 밀어 넣는 속도를 $\lambda’{in}$이라 하면, 재전송 때문에 $\lambda’{in} \geq \lambda_{in}$이 된다.
- 이상화 1 (완전 지식): 송신자가 버퍼가 빌 때만 보낸다면 $\lambda_{out} = \lambda_{in}$.
- 이상화 2 (손실만 파악): 손실된 패킷만 재전송하면, 일부 용량은 재전송에 소모된다.
- 현실: 타임아웃이 조기에 터지면서 불필요한 중복 전송까지 발생한다. 같은 패킷의 사본 두 개가 모두 도착하는 일이 잦다.
여기서 혼잡의 비용이 드러난다.
- 주어진 수신 처리량을 위해 송신자가 더 많은 일을 한다(재전송).
- 불필요한 중복이 링크 용량을 깎아 먹는다.
Scenario 3 — 멀티홉, 다른 플로우와의 충돌
네 송신자, 멀티홉 경로, 타임아웃 재전송. 빨간 플로우의 $\lambda’_{in}$이 커질수록 상위 큐에서 파란 플로우의 패킷이 전부 떨어진다. 한 플로우의 폭주가 다른 플로우의 처리량을 0으로 만든다.
이로부터 또 다른 비용이 보인다. 하류에서 떨어진 패킷을 위해 상류에서 사용한 전송 용량과 버퍼는 전부 낭비된다. 멀리 갈수록 손실의 파괴력은 커진다.
종합 인사이트
- 처리량은 절대 용량을 넘을 수 없다.
- 용량에 가까워질수록 지연이 폭발한다.
- 손실과 재전송은 유효 처리량을 깎는다.
- 불필요한 중복 전송은 유효 처리량을 더 깎는다.
- 하류 손실은 상류 자원까지 낭비시킨다.
혼잡 제어의 두 접근
크게 두 갈래로 나뉜다.
| 구분 | End-end | Network-assisted |
|---|---|---|
| 피드백 | 없음 — 손실/지연으로 추정 | 라우터가 명시적 신호 |
| 사용 예 | 일반 인터넷 TCP | 데이터센터 등 통제 환경 (TCP ECN, ATM, DECbit) |
TCP는 기본적으로 end-end 접근을 따른다. 라우터는 도와주지 않는다는 가정하에 송신자가 손실과 지연을 관찰해 혼잡을 추정한다.
TCP의 송신 속도 모델
본격적인 혼잡 제어 알고리즘을 보기 전에, TCP가 어떻게 송신 속도를 조절하는지 짚어야 한다. 흐름 제어에서 본 rwnd와 별도로, 송신자는 혼잡 윈도우(congestion window, cwnd)를 유지한다. 가정: 수신 버퍼는 충분히 커서 rwnd 제약은 무시한다.
송신자는 다음 조건을 지킨다.
\[\text{LastByteSent} - \text{LastByteAcked} \leq \text{cwnd}\]대략적으로 송신 속도는 다음과 같다.
\[\text{TCP rate} \approx \frac{\text{cwnd}}{\text{RTT}} \ \ \text{bytes/sec}\]cwnd는 네트워크 혼잡에 따라 동적으로 조정된다. 이 조정 정책이 곧 혼잡 제어 알고리즘이다.
AIMD — Additive Increase, Multiplicative Decrease
핵심 아이디어는 한 줄로 요약된다. 손실이 보일 때까지 늘리고, 손실이 보이면 줄인다. 늘리는 방식과 줄이는 방식이 비대칭이다.
- Additive Increase: 매 RTT마다
cwnd를 1 MSS씩 더한다. - Multiplicative Decrease: 손실이 감지되면
cwnd를 절반으로 자른다.
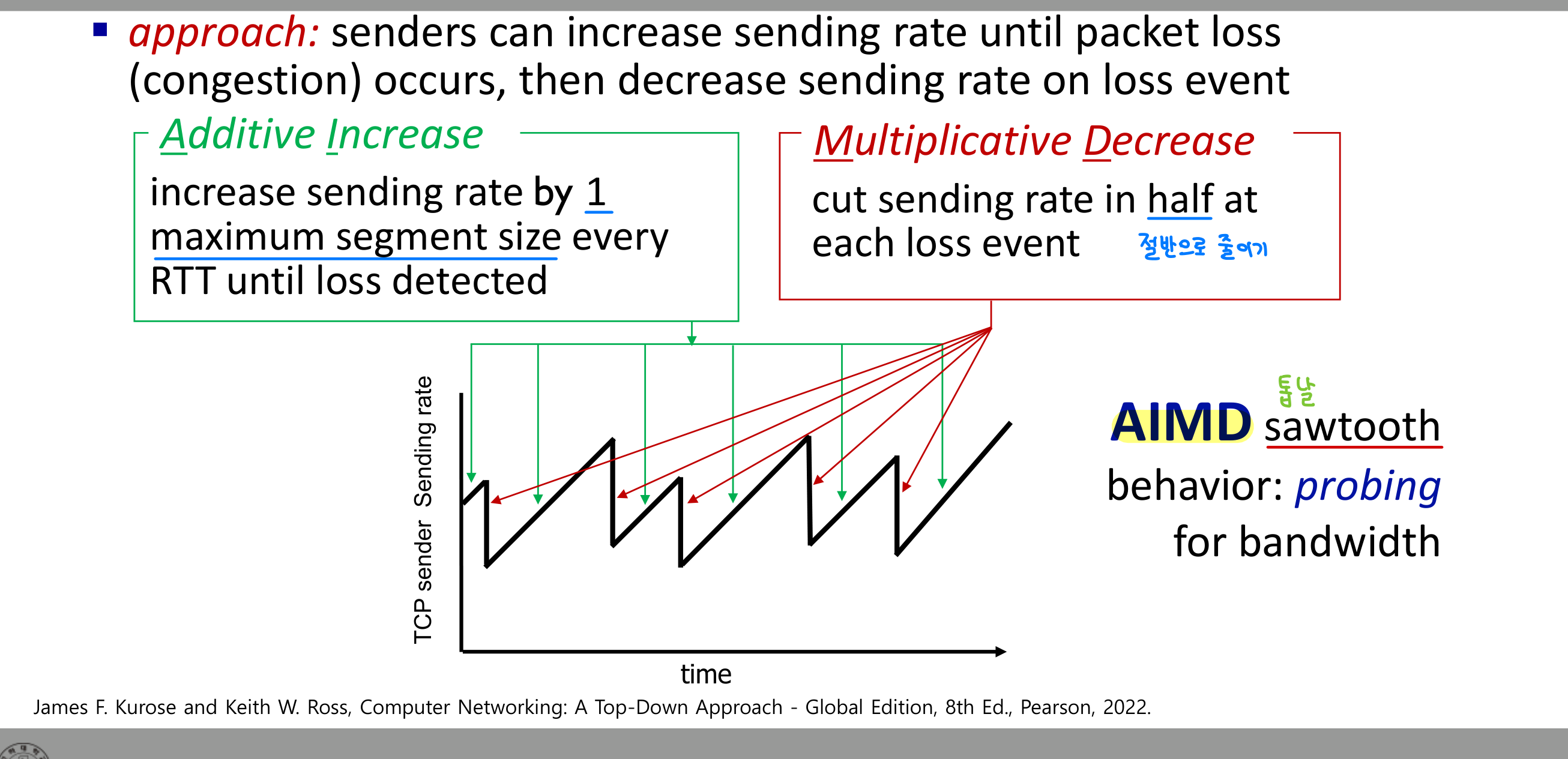
송신 속도 그래프는 톱니파(sawtooth) 형태를 그린다. 천천히 올라가다가 손실에서 급격히 떨어지는 패턴이 반복된다. 이를 사용 가능 대역폭을 탐색(probing)하는 동작으로 본다.
손실 감지 방식에 따라 줄이는 정도가 다르다.
- 3 duplicate ACK 감지 → 절반으로 (TCP Reno): 네트워크가 어느 정도 살아 있다는 신호.
- 타임아웃 감지 → 1 MSS로 (TCP Tahoe): 더 심각한 상황으로 보고 완전히 리셋한다.
왜 AIMD인가
분산되고 비동기적인 알고리즘인데도 AIMD는 두 가지 성질을 가진다.
- 네트워크 전체에서 혼잡 플로우 속도를 최적화한다.
- 안정성(stability)을 확보한다.
Slow Start
AIMD만 쓰면 시작이 너무 느리다. 연결 시작 직후에는 네트워크의 가용 대역폭이 얼마인지 모르므로, 지수적으로 올린다.
- 초기
cwnd = 1 MSS - 매 RTT마다
cwnd를 두 배로 - 구현상으로는 ACK가 올 때마다
cwnd += 1
이름은 “Slow”지만 실제 동작은 빠르게 차오른다. 다만 시작점이 1이라 첫 RTT는 느리다.
Slow Start → Congestion Avoidance
언제까지 지수 증가를 할 것인가. 손실 직전 cwnd 값의 절반에서 멈춘다. 이 임계값을 ssthresh라 한다.
손실이 발생하면 ssthresh를 손실 직전 cwnd의 절반으로 설정하고, 이후 cwnd가 ssthresh에 도달하면 지수 증가에서 선형 증가(AIMD의 Additive Increase 구간)로 전환된다.
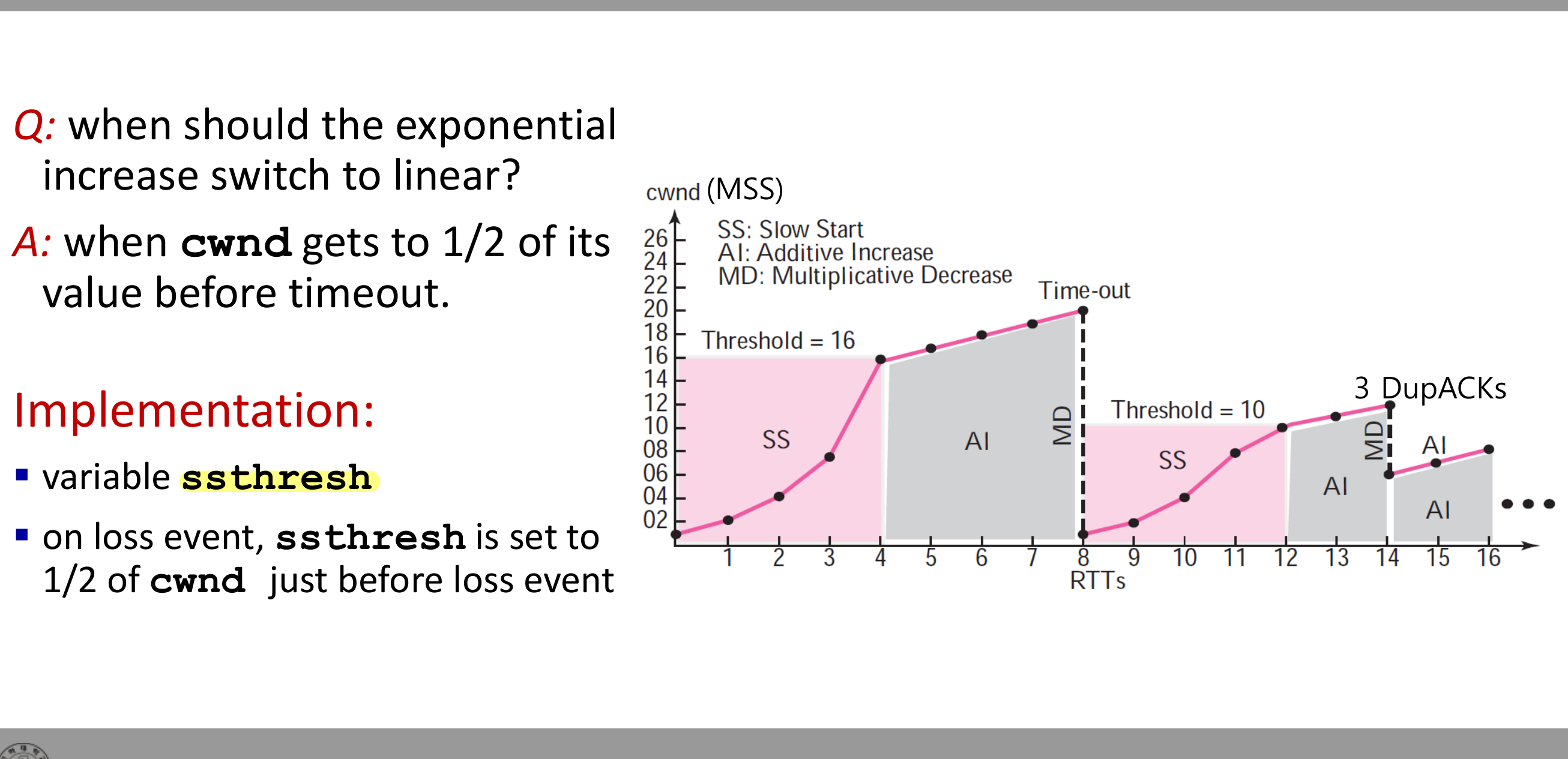
분홍 영역이 Slow Start(SS), 회색 영역이 Congestion Avoidance(AI)다. 손실(MD) 후 다시 cwnd = 1에서 시작하는 패턴이 반복된다.
TCP 상태 전이
단순화된 형태로 보면 두 상태다.
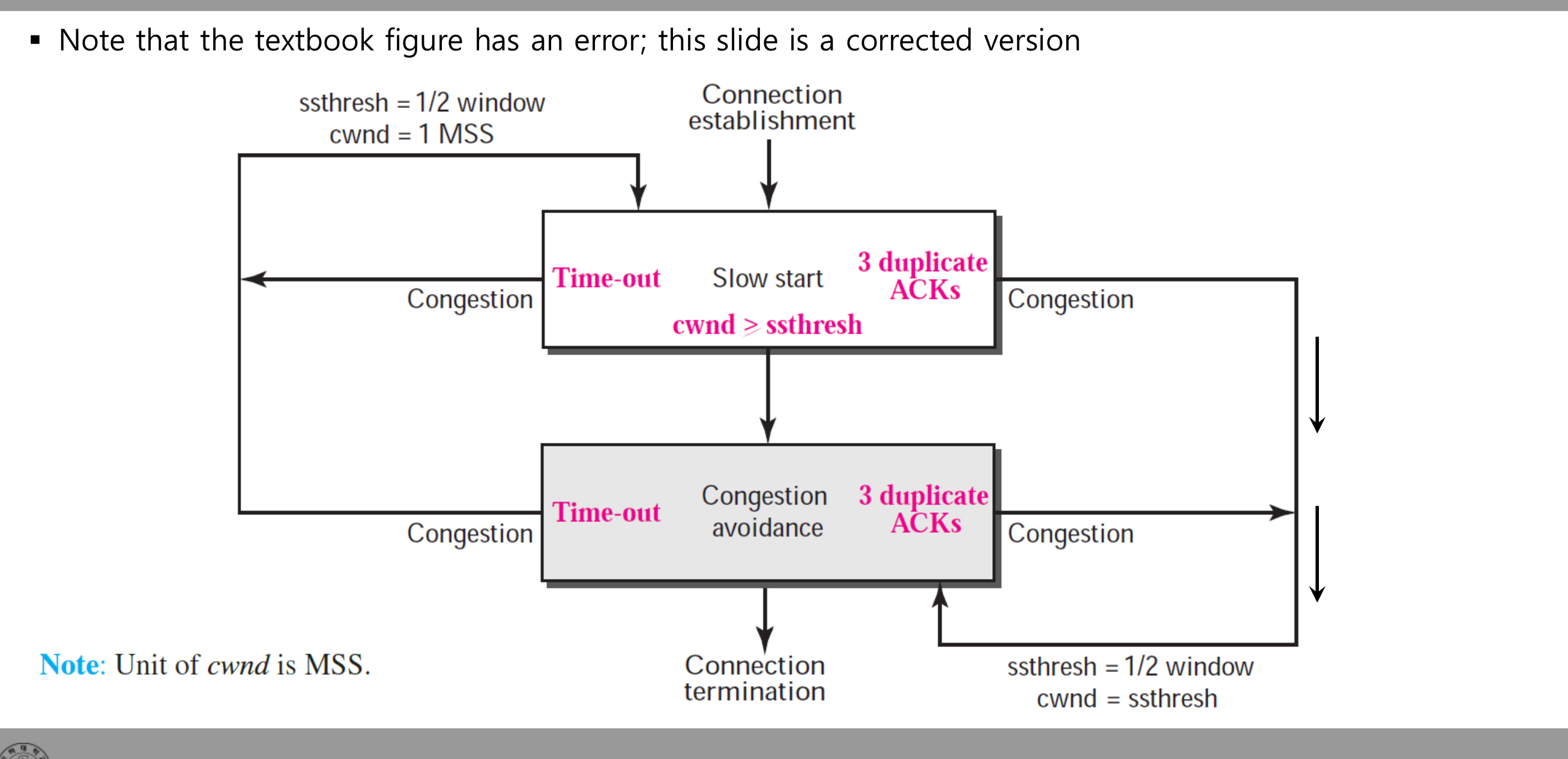
- Slow Start:
cwnd < ssthresh. 지수 증가. - Congestion Avoidance:
cwnd ≥ ssthresh. 선형 증가. - 손실 신호(타임아웃 또는 3 dupACK)가 오면 Slow Start로 복귀.
여기까지가 공통이고, 구체적인 알고리즘에 따라 손실 처리 방식이 갈린다.
TCP Tahoe
가장 단순한 변형. 타임아웃이든 3 dupACK이든 모두 동일하게 처리한다. ssthresh = cwnd/2, cwnd = 1로 리셋하고 Slow Start부터 다시 시작한다.
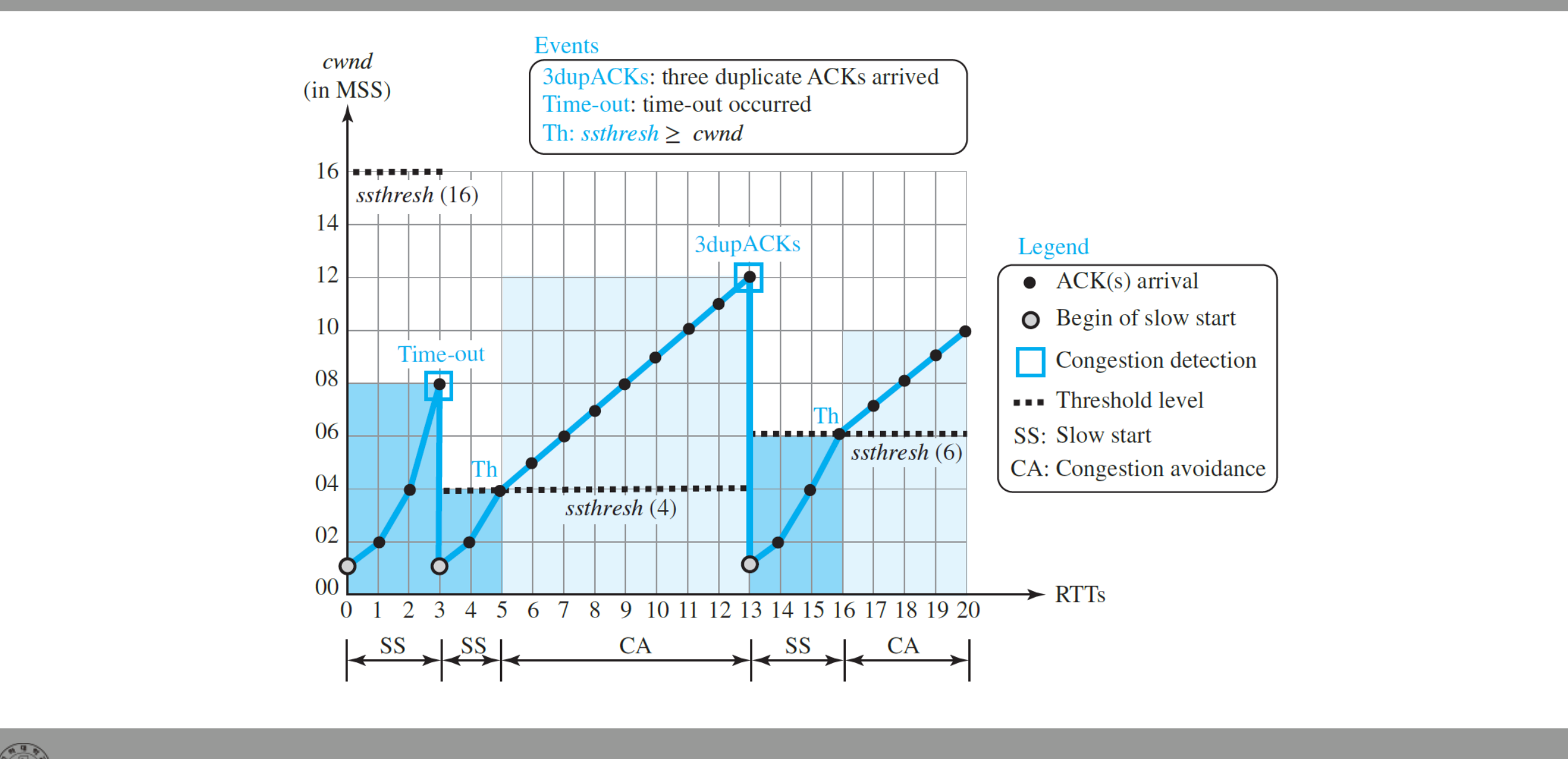
- RTT 3에서 Time-out:
ssthresh = 4,cwnd = 1. SS 재시작. - RTT 5에서
cwnd가ssthresh = 4에 도달: Congestion Avoidance 진입. - RTT 13에서 3 dupACK:
ssthresh = 6,cwnd = 1. 다시 SS.
3 dupACK 상황도 타임아웃과 똑같이 처리하므로 cwnd가 한 번에 1까지 떨어진다.
TCP Reno — Fast Recovery 도입
Reno는 3 dupACK 손실은 네트워크가 여전히 패킷을 전달하고 있다는 증거로 본다. 즉 타임아웃보다 덜 심각한 신호라는 가정이다. 그래서 별도의 상태 Fast Recovery를 둔다.
- 3 dupACK 발생:
ssthresh = cwnd/2,cwnd = ssthresh + 3. Fast Recovery 진입. - Fast Recovery 중 추가 dupACK이 올 때마다
cwnd += 1. - 새 ACK가 오면
cwnd = ssthresh로 맞추고 Congestion Avoidance로 진입. - 타임아웃은 Tahoe처럼 처리(
cwnd = 1, Slow Start).
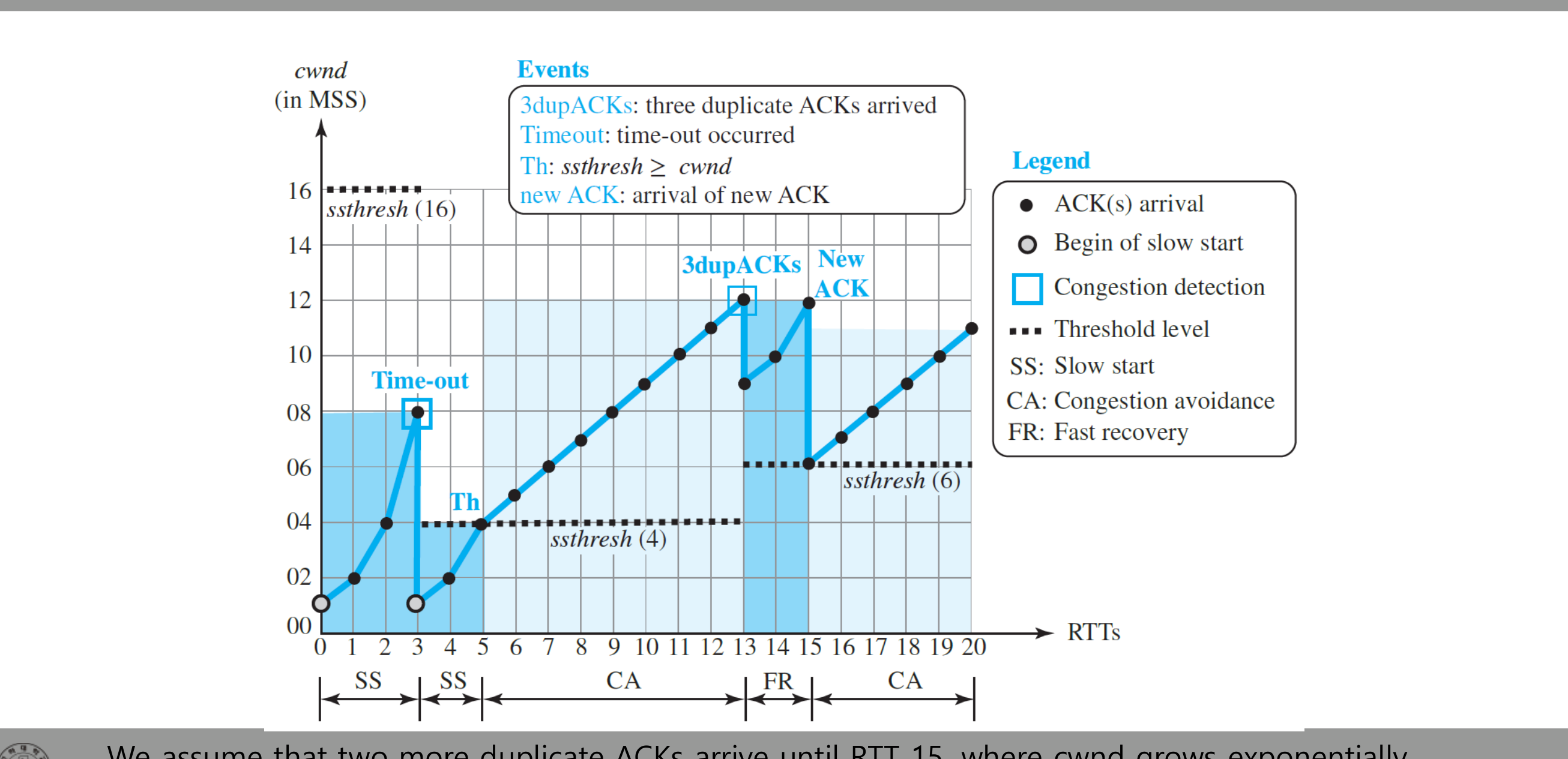
타임아웃이 일어난 RTT 3에서는 cwnd = 1로 떨어지지만, 3 dupACK이 일어난 RTT 13에서는 cwnd가 절반 수준에서 회복한다. 이 절차를 Fast Retransmit + Fast Recovery라 부른다.
TCP Fairness
목표 자체는 명확하다. $K$개의 TCP 세션이 같은 병목 링크($R$)를 공유하면 각 세션은 평균 $R/K$의 속도를 가져야 한다.
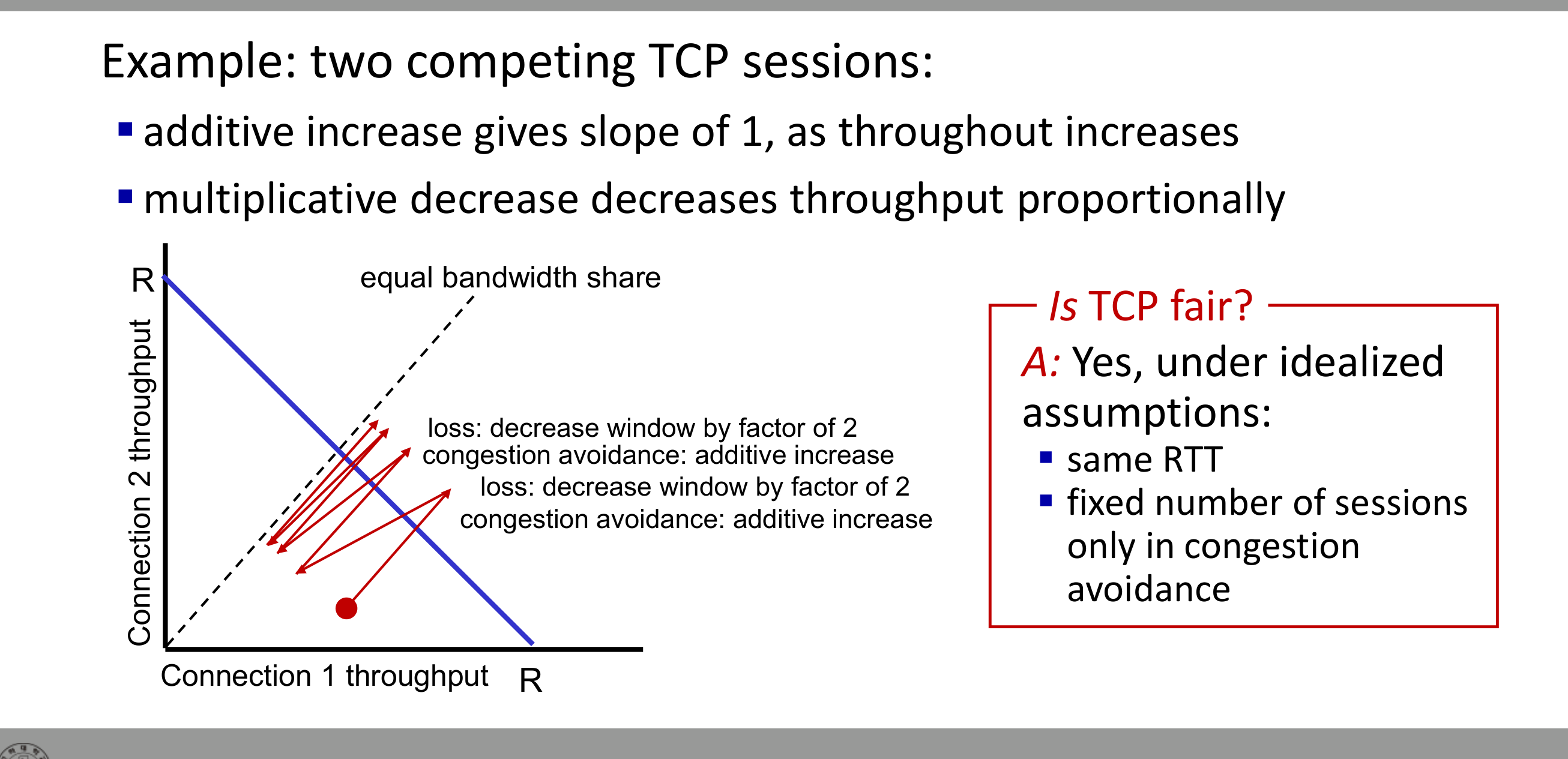
두 연결의 처리량 평면에서 보면 AIMD는 항상 공정한 분배선(equal bandwidth share)을 향해 수렴한다.
- Additive Increase: 두 연결의 처리량이 동일한 양만큼 증가 → 기울기 1로 우상향.
- Multiplicative Decrease: 두 연결 모두 절반으로 → 원점 방향으로 비례 축소.
이 과정이 반복되면 결국 공정선 위에서 진동한다. 단, 이상적인 가정(같은 RTT, 고정된 세션 수, Congestion Avoidance 구간에 머무름) 아래서만 보장된다. 실제로는 RTT가 짧은 연결이 더 빨리 cwnd를 늘리므로 더 많은 대역폭을 가져간다.
모든 앱이 공정해야 하는가
그렇지 않다. 실제로는 다음 두 경로로 공정성 가정이 쉽게 깨진다.
- UDP: 멀티미디어 앱은 혼잡 제어로 속도가 깎이는 것을 원치 않아 UDP를 쓰고 일정 속도로 보낸다. 인터넷에는 이를 단속하는 “경찰”이 없다.
- 병렬 TCP 연결: 한 앱이 여러 연결을 동시에 연다. 9개의 기존 연결이 있는 링크에서, 새 앱이 1개를 열면 $R/10$, 11개를 열면 $R/2$를 가져간다. 웹 브라우저가 정확히 이 방식을 쓴다.
TCP CUBIC — Loss-based의 개량
[Optional] 시험 범위는 아니지만, 현대 인터넷에서 가장 널리 쓰이는 알고리즘이라 짚고 간다.
AIMD보다 더 나은 대역폭 탐색 방식이 있을까. CUBIC의 직관은 단순하다. 손실 직전 도달했던 윈도우 $W_{max}$ 근처가 여전히 안전선일 가능성이 높다는 것이다. 절반으로 줄인 뒤 $W_{max}$ 근처까지는 빠르게 복귀하고, $W_{max}$ 근처에서는 조심스럽게 접근한다.
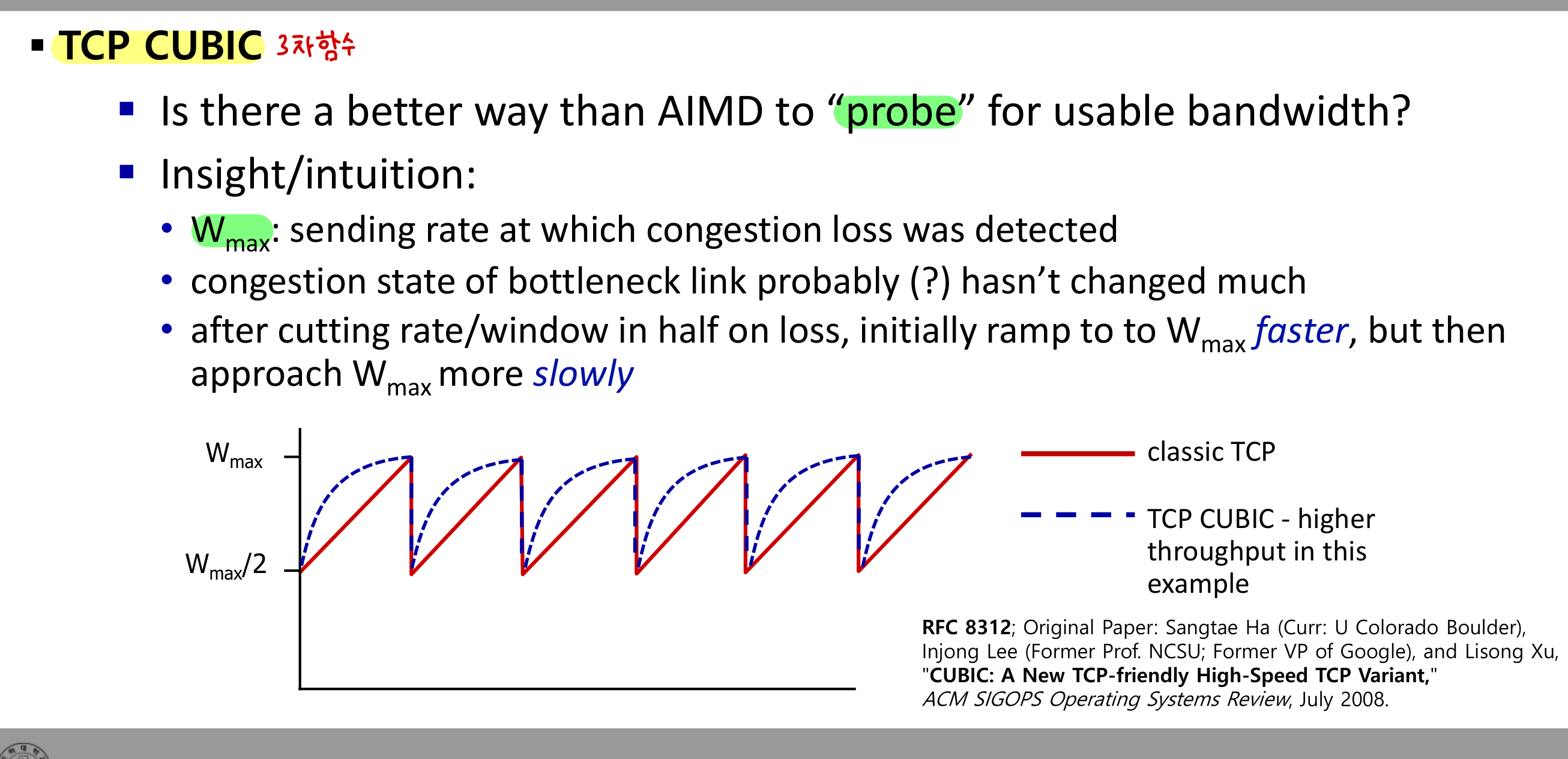
윈도우 증가량을 현재 시각과 $W_{max}$ 도달 예정 시점 $K$ 사이 거리의 3차 함수(cube)로 정의한다.
- $K$에서 멀수록 빠르게 증가.
- $K$에 가까울수록 조심스럽게 증가.
리눅스 기본 TCP가 CUBIC이며, 대중적인 웹 서버 대부분이 사용한다.
Delay-based TCP와 BBR
[Optional] 손실을 강제로 일으켜야만 혼잡을 알 수 있다는 것 자체가 비효율이다. 손실 없이도 혼잡을 추정할 수 있다면 더 좋다.
핵심 직관 두 개를 짚는다.
- 병목 링크에서 큐가 차오르면 RTT가 증가한다.
- 병목이 이미 꽉 차 있으면 송신 속도를 더 올려도 종단 처리량은 오르지 않는다.
이를 이용해 다음을 정의한다.
- $\text{RTT}_{min}$: 관측된 최소 RTT (비혼잡 경로의 RTT).
- 비혼잡 처리량 추정치: $\text{cwnd} / \text{RTT}_{min}$.
- 측정 처리량: 최근 RTT 동안 보낸 바이트 수 / 측정 RTT.
측정 처리량이 비혼잡 추정치에 가까우면 cwnd를 늘리고, 훨씬 작으면 줄인다. 손실을 만들지 않고 큐를 비워두면서 병목을 가득 쓴다는 의미다. 구글의 BBR이 백본에서 사용한다.
ECN — 명시적 혼잡 알림
[Optional] Network-assisted 접근의 대표 사례다. 라우터가 IP 헤더의 ToS 필드 두 비트를 마킹해 혼잡 발생을 알린다.
- 라우터가 혼잡 시 IP 헤더의 ECN 비트를 set.
- 수신측이 ACK 세그먼트의 TCP 헤더 ECE 비트를 set해 송신자에게 알린다.
- IP(헤더 ECN 비트)와 TCP(헤더 C, E 비트)가 함께 관여한다.
손실 없이 혼잡 신호를 받을 수 있다는 점에서 데이터센터처럼 통제된 환경에서 활용된다.
TCP Timers
TCP는 혼잡 제어 외에도 여러 타이머를 운영한다. 각 타이머는 서로 다른 비정상 상황을 처리한다.
| 타이머 | 목적 |
|---|---|
| Retransmission | 손실 감지 및 재전송 (RTO 기반) |
| Persistence | Zero window 교착 해소 |
| Keepalive | 죽은 연결 정리 |
| TIME-WAIT | 종료 시 마지막 ACK 보장 |
Retransmission Timer
오류 제어 파트에서 다룬 그 RTO 타이머다. 일정 시간 안에 ACK이 오지 않으면 재전송한다.
Persistence Timer — Zero Window 교착
수신자가 광고한 rwnd가 0이면 송신자는 더 이상 보낼 수 없다. 이후 수신자가 버퍼를 비우고 nonzero window를 광고하는 ACK을 보냈는데, 그 ACK가 손실되면 어떻게 되는가.
데이터 없는 ACK은 재전송 메커니즘이 없다. 송신자는 0인 줄 알고 대기, 수신자는 ACK 보냈다고 생각하고 대기. dead lock이다.
이를 풀기 위해 송신자는 zero-rwnd ACK을 받는 순간 Persistence Timer를 시작한다. 타이머가 만료되면 송신자는 probe 세그먼트를 보낸다.
- 1바이트 데이터만 포함.
- 시퀀스 번호는 가지지만 결코 ACK되지 않는다.
- 나머지 데이터의 시퀀스 번호 계산에서도 무시된다.
- 수신자가 ACK을 재전송하게 만드는 것이 유일한 목적.
응답이 없으면 타이머 값을 두 배로 늘려 다시 보낸다. 보통 임계값 60초에 도달하면 그 뒤로는 60초 간격으로 윈도우가 다시 열릴 때까지 probe를 계속 보낸다.
Keepalive Timer
오래 유휴 상태인 연결은 시스템 자원만 잡아먹는다. 서버가 클라이언트로부터 2시간 동안 아무 세그먼트도 받지 못하면 probe를 보낸다. 75초 간격으로 10번 보내도 응답이 없으면 연결을 종료한다.
TIME-WAIT Timer (2MSL Timer)
능동 종료(active close)를 수행한 쪽은 상대의 FIN에 대한 ACK을 보낸 뒤 2 × MSL(Maximum Segment Lifetime) 동안 TIME_WAIT 상태를 유지한다. 보낸 마지막 ACK이 손실될 경우, 상대가 FIN을 재전송할 때 다시 ACK을 보낼 수 있어야 하기 때문이다.
핵심 요약
- 혼잡은 너무 많은 송신자가 만들어내는 네트워크 내부 압력이다. 손실과 지연으로 드러난다.
- TCP는 end-end 추정 기반으로
cwnd를 조절한다. 송신 속도는 대략 $\text{cwnd}/\text{RTT}$. - AIMD가 골격이다. 매 RTT마다 +1 MSS, 손실 시 절반.
- Slow Start가 초기 부팅을 담당한다.
ssthresh에 도달하면 Congestion Avoidance로 전환. - Tahoe는 모든 손실을 동일하게 처리. Reno는 3 dupACK을 덜 심각한 신호로 보고 Fast Recovery로 회복.
- 같은 RTT 가정하에 AIMD는 공정한 분배에 수렴한다.
- CUBIC, BBR, ECN은 loss-based AIMD의 한계를 다른 방식으로 보완한다.
- TCP 타이머는 네 가지: Retransmission, Persistence, Keepalive, TIME-WAIT.