Internet Protocol (1) — 네트워크 계층, IP 헤더, 단편화, 주소 체계
전송 계층은 두 프로세스 사이의 통신을 책임진다. 그런데 그 세그먼트를 실제로 출발지 호스트에서 목적지 호스트까지 옮기는 일은 누가 하는가. 네트워크 계층이다. IP(Internet Protocol)는 그 핵심 프로토콜이고, 인터넷에 연결된 모든 장비가 IP를 구현한다.
네트워크 계층의 역할
네트워크 계층의 임무는 단순하다. 송신 호스트에서 수신 호스트로 세그먼트를 전달한다.
- 송신 측: 전송 계층 세그먼트를 데이터그램(datagram)으로 캡슐화해 링크 계층으로 내려보낸다.
- 수신 측: 데이터그램에서 세그먼트를 꺼내 전송 계층으로 올려보낸다.
여기서 중요한 점은 네트워크 계층 프로토콜이 호스트뿐 아니라 라우터를 포함한 모든 인터넷 장비에 존재한다는 것이다. 라우터는 지나가는 모든 IP 데이터그램의 헤더 필드를 검사하고, 입력 포트에서 출력 포트로 데이터그램을 옮긴다.
Forwarding와 Routing
네트워크 계층의 기능은 두 가지로 나뉜다. 이름이 비슷해 헷갈리기 쉽지만 역할이 다르다.
- 포워딩(forwarding): 패킷을 라우터의 입력 링크에서 적절한 출력 링크로 옮기는 것. 하나의 라우터 내부에서 일어나는 지역적(local) 동작이다.
- 라우팅(routing): 출발지에서 목적지까지 패킷이 거칠 경로 전체를 결정하는 것. 라우팅 알고리즘이 담당한다.
여행에 비유하면 포워딩은 하나의 나들목(interchange)을 통과하는 과정이고, 라우팅은 출발지부터 목적지까지 여정 전체를 계획하는 과정이다.
Data Plane과 Control Plane
같은 구분을 다른 관점에서 보면 데이터 평면(data plane)과 제어 평면(control plane)으로 나뉜다.
| 구분 | Data Plane | Control Plane |
|---|---|---|
| 범위 | 지역적(local), 라우터별 기능 | 네트워크 전체(network-wide) 로직 |
| 역할 | 입력 포트로 들어온 데이터그램을 출력 포트로 포워딩 | 데이터그램이 라우터들을 거쳐 어떤 경로로 라우팅될지 결정 |
제어 평면을 구현하는 방식은 두 가지다. 전통적인 방식은 각 라우터마다(per-router) 라우팅 알고리즘을 두고 서로 상호작용하게 한다. 다른 방식은 SDN(Software-Defined Networking)으로, 원격 컨트롤러가 포워딩 테이블을 계산해 각 라우터에 설치한다. 제어 로직을 라우터에서 분리해 별도의 서버로 옮긴 구조다.
네트워크 서비스 모델
네트워크 계층이 “송신자에서 수신자로 데이터그램을 나르는 채널”이라면, 그 채널은 어떤 품질을 보장할 수 있는가. 이론적으로는 보장된 전달, 40ms 이하 지연 보장, 순서 보장(in-order delivery), 최소 대역폭 보장 같은 서비스를 생각할 수 있다.
그러나 인터넷이 실제로 채택한 모델은 best-effort다. 말 그대로 “최선을 다하지만 아무것도 보장하지 않는다”.
| 네트워크 구조 | 서비스 모델 | 대역폭 | 손실 | 순서 | 타이밍 |
|---|---|---|---|---|---|
| Internet | best effort | 없음 | 보장 안 함 | 보장 안 함 | 보장 안 함 |
| ATM | Constant Bit Rate | 고정 | 보장 | 보장 | 보장 |
| ATM | Available Bit Rate | 최소 보장 | 보장 안 함 | 보장 | 보장 안 함 |
| Internet | Intserv Guaranteed (RFC 1633) | 보장 | 보장 | 보장 | 보장 |
| Internet | Diffserv (RFC 2475) | 가능 | 가능 | 가능 | 보장 안 함 |
best-effort는 성공적 전달, 타이밍, 순서, 대역폭 그 무엇도 보장하지 않는다. 그런데도 인터넷이 이 모델로 성공한 이유가 있다.
- 메커니즘이 단순해 인터넷이 폭넓게 보급될 수 있었다.
- 충분한 대역폭 공급으로 실시간 애플리케이션도 “대체로 충분히” 동작한다.
- CDN처럼 애플리케이션 계층의 분산 서비스가 사용자 가까이에서 콘텐츠를 제공한다.
- “elastic” 서비스의 혼잡 제어가 보조한다.
결국 best-effort 모델의 성공을 반박하기는 어렵다.
Internet Protocol 기초
IPv4는 [RFC 791]에 정의되어 있고, 세 가지 성질로 요약된다. unreliable, connectionless, datagram delivery 서비스다.
- unreliable(비신뢰성): IP 데이터그램이 목적지에 도착한다는 보장이 없다. 불필요하게 전부 버리지는 않지만 패킷의 운명을 보장하지 않으므로 best-effort라 부른다. 신뢰성이 필요하면 상위 계층이 책임져야 한다.
- connectionless(비연결성): IP는 네트워크 요소(라우터) 안에서 관련 데이터그램에 대한 연결 상태(connection state)를 유지하지 않는다.
- datagram(데이터그램): 각 데이터그램은 다른 모든 데이터그램과 독립적으로 처리된다.
위 세 성질로 인한 문제(손실, 순서 뒤바뀜 등)는 오류 없는 전달이 필요한 상위 계층이 직접 해결해야 한다.
IP Datagram vs IP Packet: 둘은 사실상 같은 말이다. 엄밀히는 “IP 패킷”이 프레임 안의 데이터그램 부분을 가리킬 때 더 자주 쓰이지만, 많은 엔지니어가 둘을 구분하지 않는다. 같은 단어로 생각해도 무방하다.
IPv4 헤더
IP 데이터그램은 헤더와 데이터로 구성된다. 기본 헤더는 20바이트이고, 옵션을 포함하면 최대 60바이트까지 늘어난다. 전체 데이터그램은 최대 65,535바이트다.
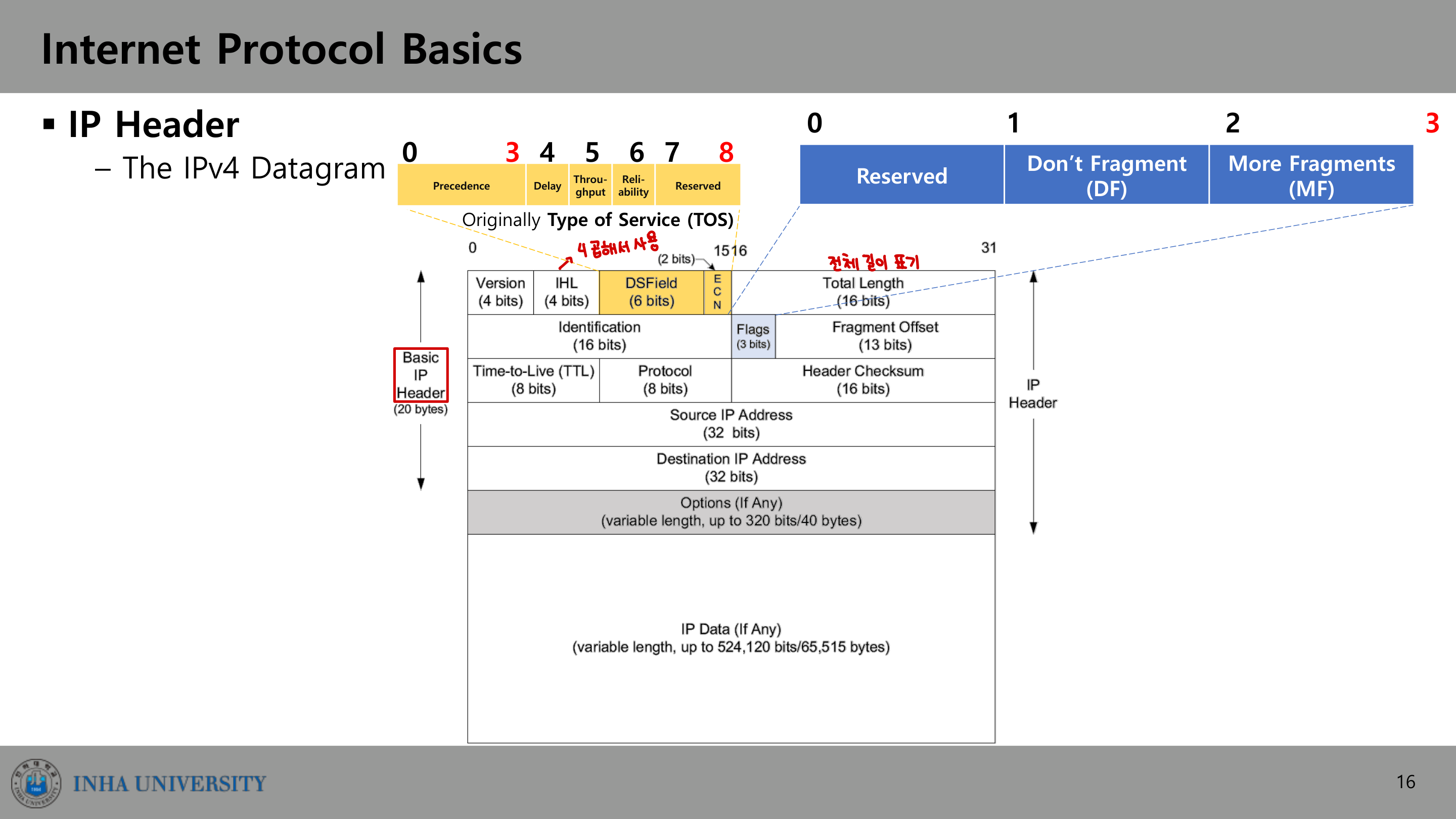
주요 필드를 순서대로 살펴본다.
Version (4비트): 헤더 첫 4비트. 버전 번호(4 또는 6)가 들어간다. IPv4와 IPv6는 호환되지 않는다(not interoperable).
IHL, Internet Header Length (4비트): 헤더 크기를 32비트 워드 단위로 나타낸다. 4비트이므로 최대 15워드, 즉 60바이트까지 표현한다.
ToS, Type of Service (8비트): 원래는 데이터그램의 특수 처리를 위해 설계됐으나 널리 쓰이지 않았다. 그래서 6비트 DS(Differentiated Services) Codepoint 필드 + 2비트 ECN(Explicit Congestion Notification) 필드로 재정의됐다.
- 오른쪽 3비트가 모두 0이면, 왼쪽 3비트는 호환성을 위해 기존 ToS의 precedence 비트로 해석된다.
- 오른쪽 3비트가 0이 아니면, 6비트가 인터넷 또는 지역 권한에 따라 $64 - 8 = 56$개의 서비스를 정의한다 (RFC 2474, RFC 8436).
Total Length (16비트): 헤더를 포함한 IPv4 데이터그램 전체 크기. 16비트이므로 최대 65,535바이트다. 이 필드가 중요한 이유는 하위 계층이 정확한 데이터그램 크기를 전달하지 못할 수 있기 때문이다. 예를 들어 이더넷 최소 페이로드는 46바이트인데 IPv4 데이터그램은 20바이트까지 작아질 수 있으므로, 46바이트를 채우는 패딩을 무시할 근거가 필요하다.
여기서 흥미로운 제약이 있다. 최대 크기는 65,535바이트지만, 호스트는 576바이트보다 큰 IPv4 데이터그램을 받을 수 있어야 할 의무가 없다 [RFC 791]. 왜인가. 1980년대에 흔하던 16비트 CPU가 세그먼테이션 없이 직접 접근 가능한 메모리가 64KB였기 때문이다. 그래서 UDP 위에서 동작하는 많은 IETF 프로토콜은 576바이트 한계를 피하려 데이터 크기를 512바이트로 제한한다.
또한 IPv4 데이터그램이 단편화되면 각 조각은 독립적인 IP 데이터그램으로 취급되므로, Total Length는 곧 그 조각의 크기를 의미한다. IPv4에는 별도의 payload length 필드가 없어 다음과 같이 계산한다.
\[\text{Payload Length} = \text{Total Length} - \text{Header Length}\]참고로 IPv6는 헤더 길이가 40바이트로 고정이고 payload length 필드만 존재한다.
Identification (16비트): 원래 호스트가 보내는 각 데이터그램을 식별하는 용도로, 데이터그램을 보낼 때마다 1씩 증가한다. [RFC 6864]는 이 필드를 (flags, fragment offset과 함께) 단편화와 재조립 외의 목적으로 사용해서는 안 된다(MUST NOT)고 규정한다. IPv6에는 단편화가 없다.
TTL, Time-to-Live (8비트): 데이터그램이 통과할 수 있는 라우터 수의 상한이다. [RFC 1122]는 64를 권장하지만 128이나 255를 쓰기도 한다. 데이터그램을 포워딩하는 라우터마다 1씩 감소시키며, TTL이 0이 되면 데이터그램을 버리고 송신자에게 ICMP 메시지로 알린다. 목적은 인터넷에서 패킷이 무한 루프를 도는 것을 방지하는 것이다. 원래는 초 단위 최대 수명이었으나, 라우터가 항상 최소 1씩 줄이도록 요구되면서 사실상 홉 카운트가 됐다.
Protocol (8비트): 페이로드 데이터의 종류를 나타내는 번호. UDP는 17, TCP는 6 등이다. IP가 여러 프로토콜의 페이로드를 실어 나를 수 있도록 역다중화(demultiplexing) 기능을 제공한다.
| Value | Protocol | Value | Protocol |
|---|---|---|---|
| 1 | ICMP | 17 | UDP |
| 2 | IGMP | 89 | OSPF |
| 6 | TCP |
Header Checksum (16비트): IPv4 헤더에 대해서만 계산한다. IP 프로토콜 자체는 정확성을 검사하지 않는다. IPv6는 이 필드를 헤더에서 제거했는데, 유선 네트워크에서는 비트 오류가 드물고 필요하면 상위 계층에서 더 강력한 메커니즘을 쓸 수 있기 때문이다.
Options: 가변 길이지만 32비트 경계에서 끝나야 한다. 경계를 맞추기 위해 1바이트 NOP, EOP 옵션으로 패딩한다. (자세한 내용은 아래 IP Options 절에서 다룬다.)
IPv4 단편화 (Fragmentation)
네트워크 링크마다 전송 가능한 최대 프레임 크기가 정해져 있다. 이를 MTU(Maximum Transfer Unit)라 한다. 링크 종류가 다르면 MTU도 다르다.
큰 IP 데이터그램이 MTU가 작은 링크를 지나야 하면 어떻게 되는가. 데이터그램을 여러 조각으로 쪼갠다(fragmented). 하나의 데이터그램이 여러 개가 되는 것이다. 그리고 쪼개진 조각은 목적지에서만(only at destination) 재조립(reassembled)된다. 중간 라우터는 재조립하지 않는다.
조각의 식별과 순서 정렬에는 IP 헤더 필드가 쓰인다. 특히 3비트 flags 필드가 이 동작을 제어한다.
- D (Do not Fragment): 단편화 금지 비트.
- M (More Fragments): 뒤에 더 조각이 있으면 1, 마지막 조각이면 0.
그리고 Fragment Offset이 원본 데이터에서 이 조각이 시작하는 위치를 가리킨다. 단위가 8바이트라는 점이 핵심이다.

예시로 4000바이트 데이터그램(헤더 20바이트 + 데이터 3980바이트)을 MTU 1500인 링크로 보낸다고 하자. 각 조각은 헤더 20바이트를 제외하고 최대 1480바이트의 데이터를 담을 수 있다.
| 조각 | length | ID | fragflag (M) | offset |
|---|---|---|---|---|
| 1 | 1500 | x | 1 | 0 |
| 2 | 1500 | x | 1 | 185 |
| 3 | 1040 | x | 0 | 370 |
offset 값에 주목한다. 두 번째 조각의 데이터는 원본의 1480바이트 지점에서 시작하므로
\[\text{offset} = \frac{1480}{8} = 185\]세 번째 조각은 $\frac{2960}{8} = 370$이다. 마지막 조각만 M=0이고, 모든 조각의 ID는 동일하다. 이 ID로 수신 측이 같은 데이터그램의 조각임을 식별하고, offset으로 순서를 맞춰 재조립한다.
IPv6는 라우터나 방화벽 같은 중간 장비에서의 단편화를 허용하지 않는다. 다만 종단 호스트는 IPv6 fragment 확장 헤더를 써서 패킷을 단편화할 수 있다. IPv6 헤더가 Next Header 필드로 연결되는 체인 구조이기 때문에 가능한 일이다.
IPv4 Options
IP 옵션은 데이터그램 단위로 선택할 수 있는 부가 기능이다. 가변 길이지만 32비트 경계에서 끝나야 하며, 부족하면 NOP/EOP로 패딩한다.
옵션은 크게 두 종류로 나뉜다.
- Single-byte 옵션: No Operation(NOP), End of Option(EOP). 정렬과 패딩 용도.
- Multiple-byte 옵션: Record Route, Strict Source Route, Loose Source Route, Timestamp.
Multiple-byte 옵션은 Type(8비트) + Length(8비트) + Value(가변) 형식이며, Type은 다시 Copy(1비트), Class(2비트), Number(5비트)로 나뉜다.
다만 표준화된 대부분의 옵션은 오늘날 거의 쓰이지 않는다. 그래서 IPv4 옵션은 기업 네트워크 경계의 방화벽에서 차단되거나 제거되는 경우가 많다.
Record Route Option
패킷이 지나온 경로를 헤더에 기록하는 옵션이다. 주의할 점은 출발지가 목적지의 도움 없이는 기록된 IP 주소를 알 수 없다는 것이다. 이 때문에 traceroute는 이 옵션을 사용하지 않는다는 사실을 쉽게 추론할 수 있다.
IP Options 필드가 최대 40바이트로 제한되므로 최대 9개의 IP 주소만 기록할 수 있다. 평균 라우터 홉 수가 약 15개임을 감안하면 그다지 유용하지 않다. 다만 2017년 ACM IMC의 한 논문은 오늘날 인터넷에서 이 옵션이 유용할 수 있다고 주장하기도 했다.
Source Route Options
출발지가 데이터그램이 거쳐갈 게이트웨이 목록을 직접 지정하는 옵션이다. 특정 ToS(최소 지연, 최대 처리량 등)를 가진 경로를 고르거나, 더 안전하고 신뢰성 있는 경로를 선택하는 데 쓸 수 있다.
- Strict Source Route (Type 137): 옵션에 명시된 라우터를 모두 거쳐야 하고, 명시되지 않은 라우터는 거치면 안 된다.
- Loose Source Route (Type 131): 명시된 라우터는 반드시 거치되, 다른 라우터도 거칠 수 있다.
Timestamp Option
라우터가 데이터그램을 처리한 시각을 기록한다(자정 기준 밀리초, UTC). 이를 통해 한 라우터에서 다른 라우터로 가는 데 걸린 시간을 추정할 수 있다. overflow 필드는 공간이 부족해 타임스탬프를 추가하지 못한 라우터 수를 기록한다. flag 값에 따라 동작이 달라진다.
- flag=0: 각 라우터가 타임스탬프만 기록.
- flag=1: 각 라우터가 자신의 “outgoing” IP 주소와 타임스탬프를 기록.
- flag=3: IP 주소가 출발지에서 미리 주어지고, 각 라우터는 주어진 IP가 자신의 “incoming” IP와 일치하면 outgoing IP로 덮어쓰고 타임스탬프를 추가.
IP 주소 체계
IPv4 주소
IPv4 주소는 인터넷 전체에서 쓰이는 32비트 음이 아닌 정수다. 사람이 읽기 쉽도록 보통 dotted-decimal(dotted-quad) 표기법으로 나타낸다. 예를 들어 165.195.130.107처럼 각 10진수가 $[0, 255]$ 범위에 있다.
| Dotted-Quad | Binary |
|---|---|
| 0.0.0.0 | 00000000 00000000 00000000 00000000 |
| 1.2.3.4 | 00000001 00000010 00000011 00000100 |
| 165.195.130.107 | 10100101 11000011 10000010 01101011 |
| 255.255.255.255 | 11111111 11111111 11111111 11111111 |
각 바이트(8비트)를 10진수로 바꾸고 점으로 구분하면 dotted-decimal, 반대로 각 10진수를 8비트 2진수로 바꾸면 binary가 된다. 주소 표기에서 흔한 오류는 다음과 같다.
045처럼 앞에 0을 붙이는 것(leading zero) — 허용 안 됨.- 바이트가 5개 이상인 경우 — IPv4는 4바이트만 허용.
301처럼 255를 초과하는 바이트.- 2진수와 dotted-decimal을 섞어 쓰는 것.
IPv6 주소
IPv6 주소는 128비트 음이 아닌 정수로 IPv4보다 4배 길다 [RFC 4291]. 콜론(:)으로 구분된 4자리 16진수 블록(block 또는 field) 8개로 표기한다.
5f05:2000:80ad:5800:0058:0800:2023:1d71
표기를 단순화하는 규칙이 있다.
- 블록의 앞쪽 0은 생략 가능:
0058→58. - 모두 0인 블록은
::로 생략 가능:0:0:0:0:0:0:0:1→::1,2001:0db8:0:0:0:0:0:2→2001:db8::2. - IPv4-mapped:
::ffff:10.0.0.1. - IPv4-compatible:
::0102:f001==::1.2.240.1.
포트 번호 구분자(:)와 혼동을 피하려면 대괄호를 쓴다. 예: http://[2001:db8::2]:443/.
Classful Addressing
IP 주소 체계는 수십 년 전 처음 만들어질 때 클래스(class) 개념을 사용했다. 주소의 첫 비트 패턴으로 클래스를 구분한다.
| Class | 첫 비트 패턴 | 첫 바이트 범위 |
|---|---|---|
| A | 0… | 0–127 |
| B | 10… | 128–191 |
| C | 110… | 192–223 |
| D | 1110… | 224–239 (멀티캐스트) |
| E | 1111… | 240–255 (예약) |
classful addressing에서 한 조직은 하나 이상의 주소 블록을 가지며, 각 블록은 netid(network identifier)로 식별된다. 한 네트워크는 유일한 netid를 갖고, 그 안의 호스트는 각자의 hostid(host identifier)를 갖는다. netid와 hostid는 IP 주소에서 잘라낸다.
- Class A: netid 1바이트 + hostid 3바이트 → 128개 블록, 블록당 약 1677만 개 주소.
- Class B: netid 2바이트 + hostid 2바이트 → 16,384개 블록, 블록당 65,536개 주소.
- Class C: netid 3바이트 + hostid 1바이트 → 약 209만 개 블록, 블록당 256개 주소.
- Class D: 멀티캐스트, Class E: 미래 예약.
Classful 주소에서의 라우팅
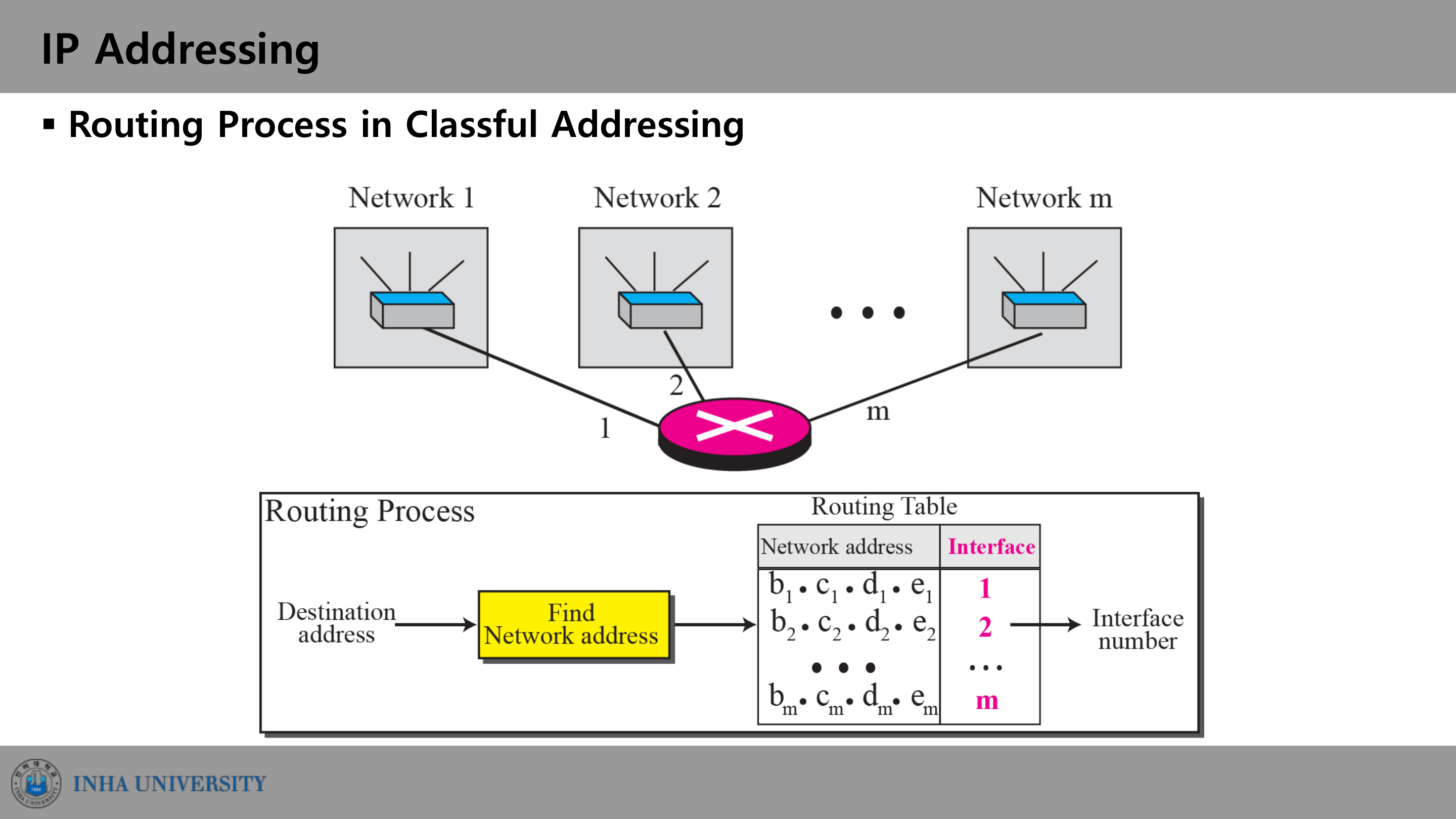
라우터는 목적지 주소에서 네트워크 주소(network address)를 추출해 라우팅 테이블에서 출력 인터페이스를 찾는다. 네트워크 주소를 뽑아내는 데 network mask를 쓴다. 목적지 주소와 마스크를 비트 AND 연산하면 네트워크 주소가 나온다.
\[\text{Network Address} = \text{Destination Address} \mathbin{\&} \text{Mask}\]클래스별 기본 마스크는 다음과 같다.
| Class | Mask | Dotted-Decimal |
|---|---|---|
| A | 8비트 1 | 255.0.0.0 |
| B | 16비트 1 | 255.255.0.0 |
| C | 24비트 1 | 255.255.255.0 |
Classful 주소의 문제
classful 방식은 주소를 비효율적으로 낭비했다. Class A와 B 블록의 상당수가 버려졌고, Class C 블록 하나에 들어가기엔 너무 큰 조직이 많았다. 주소 공간 배분도 불공평했다. Class A가 전체의 50%, Class B가 25%를 차지한다.
- Class A: $2^{31} = 2{,}147{,}483{,}648$개 주소 (50%)
- Class B: $2^{30} = 1{,}073{,}741{,}824$개 주소 (25%)
- Class C: $2^{29} = 536{,}870{,}912$개 주소 (12.5%)
- Class D: $2^{28}$개 (6.25%)
- Class E: $2^{28}$개 (6.25%)
최근에는 IPv4 주소가 희소 자원이 되어 거래되기도 한다. Google이 /12 블록을 매입하거나, MIT가 보유한 1400만 개 중 800만 개를 매각한 사례가 있다.
Subnetting (서브네팅)
인터넷 성장 초기 10년간은 서브네팅이 없었고 classful addressing만 존재했다. 그러나 1980년대 초 LAN이 늘면서, hostid가 큰 클래스를 인터넷 코어 라우팅 인프라를 바꾸지 않고 더 잘게 나눌 필요가 생겼다 [RFC 950].
핵심 아이디어는 hostid 영역의 일부를 떼어 subnetid로 쓰는 것이다. 기존 netid와 hostid 사이의 경계를 옮기는 셈이다. 외부 인터넷은 여전히 원래 netid만 보지만, 조직 내부에서는 subnetid로 더 세분화된 네트워크를 관리한다.
Subnet Mask
서브넷 마스크는 호스트나 라우터가 IP 주소에서 네트워크/서브네트워크 정보가 어떻게 분할되는지 결정하는 비트 배열이다. IPv4에서는 dotted-decimal 표기가 널리 쓰였지만, 요즘은 prefix length 형식이 더 일반적이다.
| Dotted-Decimal | Prefix Length | Binary |
|---|---|---|
| 255.0.0.0 | /8 | 11111111 00000000 00000000 00000000 |
| 255.255.0.0 | /16 | 11111111 11111111 00000000 00000000 |
| 255.255.255.0 | /24 | 11111111 11111111 11111111 00000000 |
| 255.255.255.192 | /27 | 11111111 11111111 11111111 11100000 |
| 255.255.255.255 | /32 | 11111111 11111111 11111111 11111111 |
서브넷 주소 계산은 classful 라우팅과 동일하다. 주소와 마스크를 AND 한다. 예를 들어 주소 128.32.1.14에 마스크 255.255.255.0(/24)를 AND 하면 128.32.1.0이 나온다. site-wide subnet mask가 255.255.255.0이면 256개의 서브네트워크가 생기고, 각 서브넷은 254개의 호스트를 수용할 수 있다.
서브넷이란 무엇인가
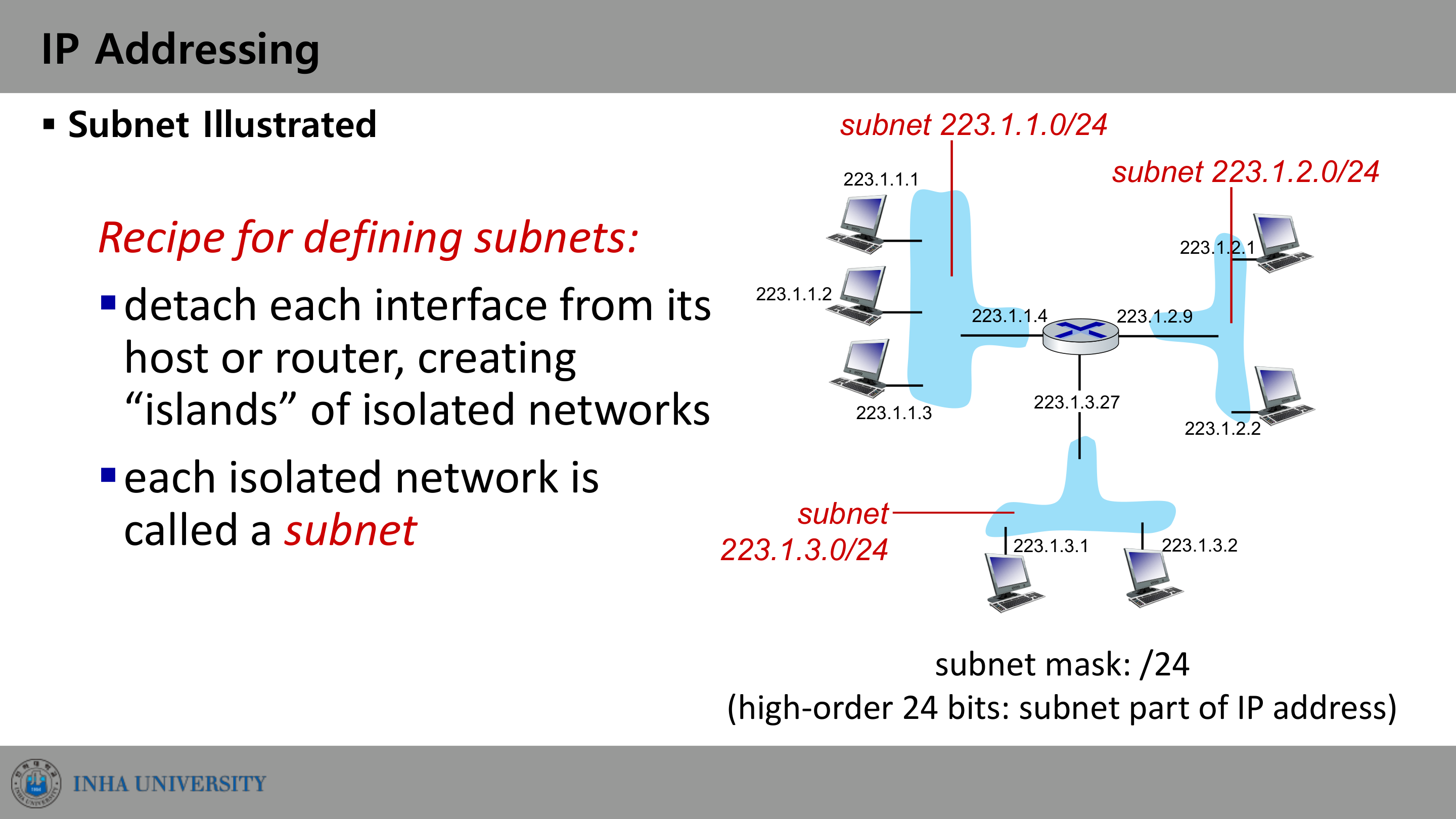
서브넷의 정의는 다음과 같다. 중간 라우터를 거치지 않고(without passing through an intervening router) 물리적으로 서로 도달할 수 있는 장치 인터페이스들의 집합이다.
이를 판별하는 레시피는 간단하다. 각 인터페이스를 자신의 호스트나 라우터에서 떼어내면, 격리된 네트워크의 “섬(island)”들이 만들어진다. 이 격리된 네트워크 하나하나가 서브넷이다.
IP 주소는 이 구조를 반영한다.
- subnet part: 같은 서브넷의 장치들이 공유하는 상위 비트.
- host part: 나머지 하위 비트.
예를 들어 223.1.1.1, 223.1.1.2, 223.1.1.3이 라우터를 거치지 않고 연결되어 있다면, 이들은 서브넷 223.1.1.0/24에 속한다. 같은 방식으로 라우터 간 연결 구간도 별도의 서브넷이 된다. 세 라우터가 삼각형으로 연결된 토폴로지라면 호스트 서브넷뿐 아니라 라우터-라우터 링크 각각도 /24 서브넷을 형성한다.