HTTP, DNS and DHCP — 응용 계층 핵심 프로토콜
웹 페이지 하나를 여는 순간 응용 계층 프로토콜 세 개가 동시에 움직인다. 주소를 입력하면 DHCP로 내 IP부터 받고, DNS로 도메인을 IP로 바꾸고, HTTP로 페이지를 가져온다. 각각을 따로 본 뒤 마지막에 한 번의 웹 요청으로 묶는다.
HTTP
웹 페이지는 객체(object)들의 묶음이다. HTML 파일, JPEG 이미지, 오디오 파일 등이 각각 별개의 객체이고, 서로 다른 서버에 흩어져 있을 수도 있다. 페이지는 base HTML 파일 하나가 다른 객체들을 URL로 참조하는 구조다.
www.someschool.edu/someDept/pic.gif
└──── host name ───┘└─── path name ──┘
HTTP(HyperText Transfer Protocol)는 웹의 응용 계층 프로토콜이다. 클라이언트/서버 모델로 동작한다 — 클라이언트(브라우저)가 객체를 요청하고, 서버(웹 서버)가 응답으로 객체를 보낸다.
HTTP는 TCP 위에서 동작한다
전송 계층으로 TCP를 쓴다. 흐름은 단순하다.
- 클라이언트가 서버의 포트 80으로 TCP 연결(소켓)을 연다
- 서버가 연결을 수락한다
- 브라우저와 서버가 HTTP 메시지를 주고받는다
- TCP 연결을 닫는다
HTTP는 무상태(stateless) 프로토콜이다. 서버는 과거 클라이언트 요청에 대한 정보를 전혀 유지하지 않는다. 상태를 유지하는 프로토콜은 복잡하다 — 과거 이력을 보관해야 하고, 서버나 클라이언트가 죽으면 서로의 상태 인식이 어긋나 이를 다시 맞춰야 한다. HTTP는 이 복잡성을 처음부터 버렸다.
두 가지 연결 방식
| Non-persistent HTTP | Persistent HTTP | |
|---|---|---|
| 연결당 객체 수 | 최대 1개 | 여러 개 |
| 동작 | 객체 하나마다 TCP 연결을 새로 열고 닫음 | 한 TCP 연결을 열어두고 재사용 |
| 비용 | 객체 N개면 연결 N번 | 연결 1번 |
Non-persistent HTTP는 객체 하나를 받을 때마다 TCP 연결을 새로 만든다. 10개의 JPEG을 참조하는 페이지라면 연결을 10번 더 열어야 한다. 응답 시간을 따져보면 객체당 다음과 같다.

- TCP 연결을 여는 데 1 RTT(Round Trip Time, 왕복 시간)
- HTTP 요청을 보내고 응답 첫 바이트가 돌아오는 데 1 RTT
- 그 뒤 파일 전송 시간
객체마다 $2 \cdot RTT$가 붙고, TCP 연결마다 OS 오버헤드도 든다. 그래서 브라우저는 보통 여러 TCP 연결을 병렬로 열어 객체를 동시에 받는다.
Persistent HTTP(HTTP/1.1)는 응답을 보낸 뒤에도 연결을 열어둔다. 이후 객체들은 같은 연결 위에서 주고받는다. 참조된 객체를 발견하는 즉시 요청을 보내고, 파이프라이닝(pipelining)까지 쓰면 모든 참조 객체를 단 1 RTT에 요청할 수 있어 응답 시간이 절반으로 준다.
HTTP 메시지: 요청
HTTP 메시지는 요청(request)과 응답(response) 두 종류다. 둘 다 ASCII(사람이 읽을 수 있는 형식)다.

요청 메시지는 요청 라인(request line) 한 줄과 헤더 라인(header lines)들로 구성된다.
GET /index.html HTTP/1.1\r\n
Host: www-net.cs.umass.edu\r\n
User-Agent: Mozilla/5.0 ...\r\n
Accept: text/html,application/xhtml+xml\r\n
Accept-Language: en-us,en;q=0.5\r\n
Accept-Encoding: gzip,deflate\r\n
Connection: keep-alive\r\n
\r\n
각 줄 끝의 \r\n은 캐리지 리턴(carriage return)과 라인 피드(line feed)다. 헤더가 끝나면 빈 줄(\r\n 하나)이 헤더의 끝을 알린다. 일반 형식으로 보면 [요청 라인] → [헤더 라인들] → [빈 줄] → [본문(entity body)] 순서다.
요청 메서드는 여러 가지가 있다.
| 메서드 | 용도 |
|---|---|
| GET | 객체 요청. 서버로 데이터를 보낼 때는 URL의 ? 뒤에 붙임 (...?monkeys&banana) |
| POST | 폼 입력 등 사용자 데이터를 본문(entity body)에 담아 전송 |
| HEAD | GET과 동일하되 헤더만 요청 (본문 없음) |
| PUT | 새 파일을 서버에 업로드, 지정 URL의 파일을 통째로 교체 |
HTTP 메시지: 응답
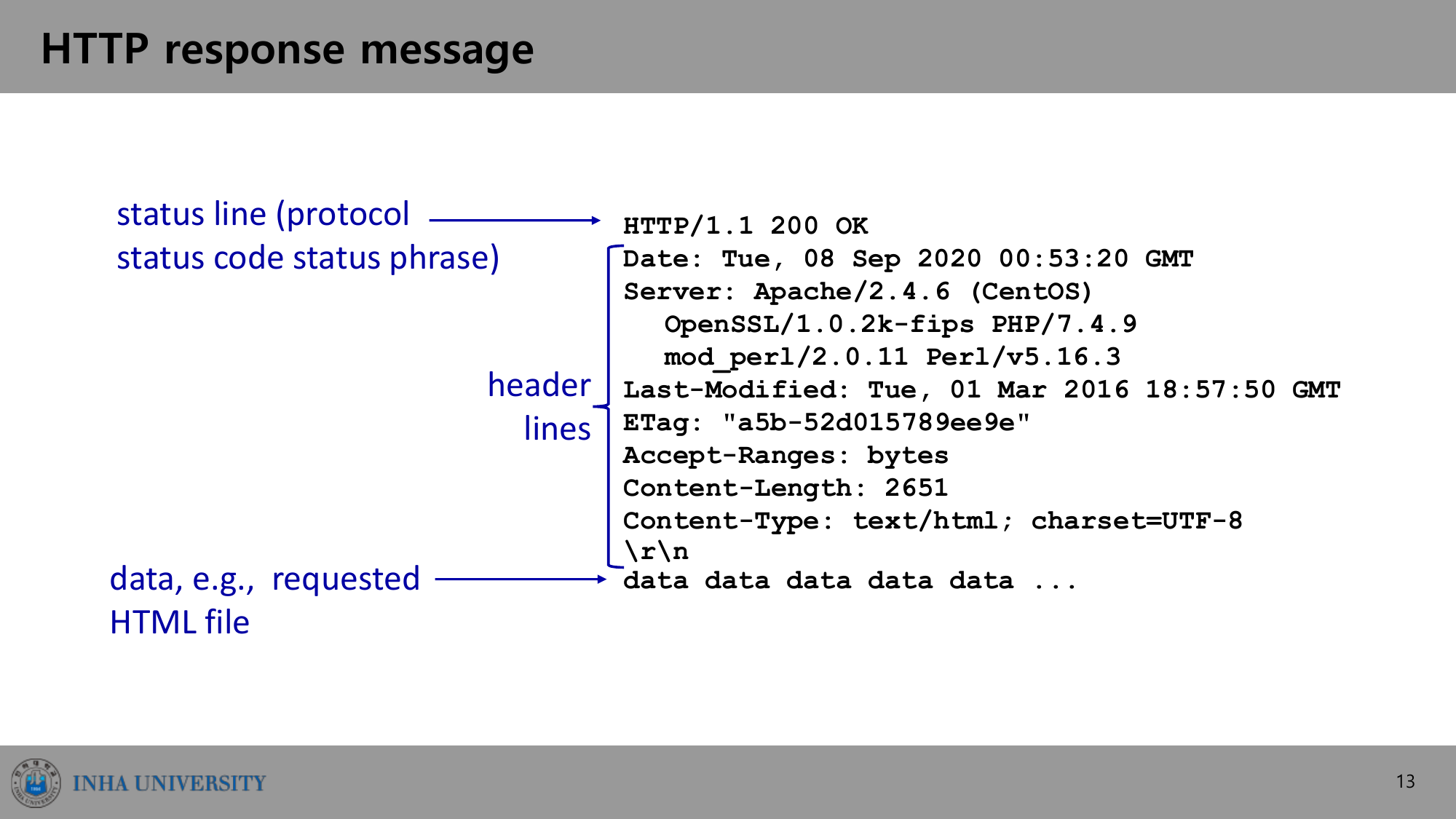
응답 메시지는 상태 라인(status line)으로 시작한다. 프로토콜 버전, 상태 코드, 상태 문구가 들어간다.
HTTP/1.1 200 OK
Date: Tue, 08 Sep 2020 00:53:20 GMT
Server: Apache/2.4.6 (CentOS) ...
Last-Modified: Tue, 01 Mar 2016 18:57:50 GMT
Content-Length: 2651
Content-Type: text/html; charset=UTF-8
\r\n
data data data data data ...
상태 코드는 응답 메시지 첫 줄에 나타난다.
| 코드 | 의미 |
|---|---|
| 200 OK | 요청 성공, 객체가 이 메시지 뒤에 포함됨 |
| 301 Moved Permanently | 객체 이동, 새 위치는 Location: 필드에 명시 |
| 400 Bad Request | 서버가 요청 메시지를 이해하지 못함 |
| 404 Not Found | 요청한 문서가 서버에 없음 |
| 505 HTTP Version Not Supported | 지원하지 않는 HTTP 버전 |
직접 확인해볼 수도 있다. nc -c -v gaia.cs.umass.edu 80(macOS)으로 포트 80에 TCP 연결을 연 뒤 GET /kurose_ross/interactive/index.php HTTP/1.1과 Host: 헤더를 입력하고 엔터를 두 번 치면 최소한의 GET 요청이 서버로 가고, 서버의 응답 메시지를 직접 볼 수 있다.
쿠키: 무상태 위에 상태 얹기
HTTP는 무상태인데, 장바구니나 로그인 같은 건 어떻게 유지할까. 답은 쿠키(cookie)다. 쿠키는 네 부분으로 동작한다.
- HTTP 응답 메시지의 쿠키 헤더 라인 (
Set-cookie) - 다음 HTTP 요청 메시지의 쿠키 헤더 라인 (
cookie) - 사용자 호스트에 저장돼 브라우저가 관리하는 쿠키 파일
- 웹 사이트의 백엔드 데이터베이스
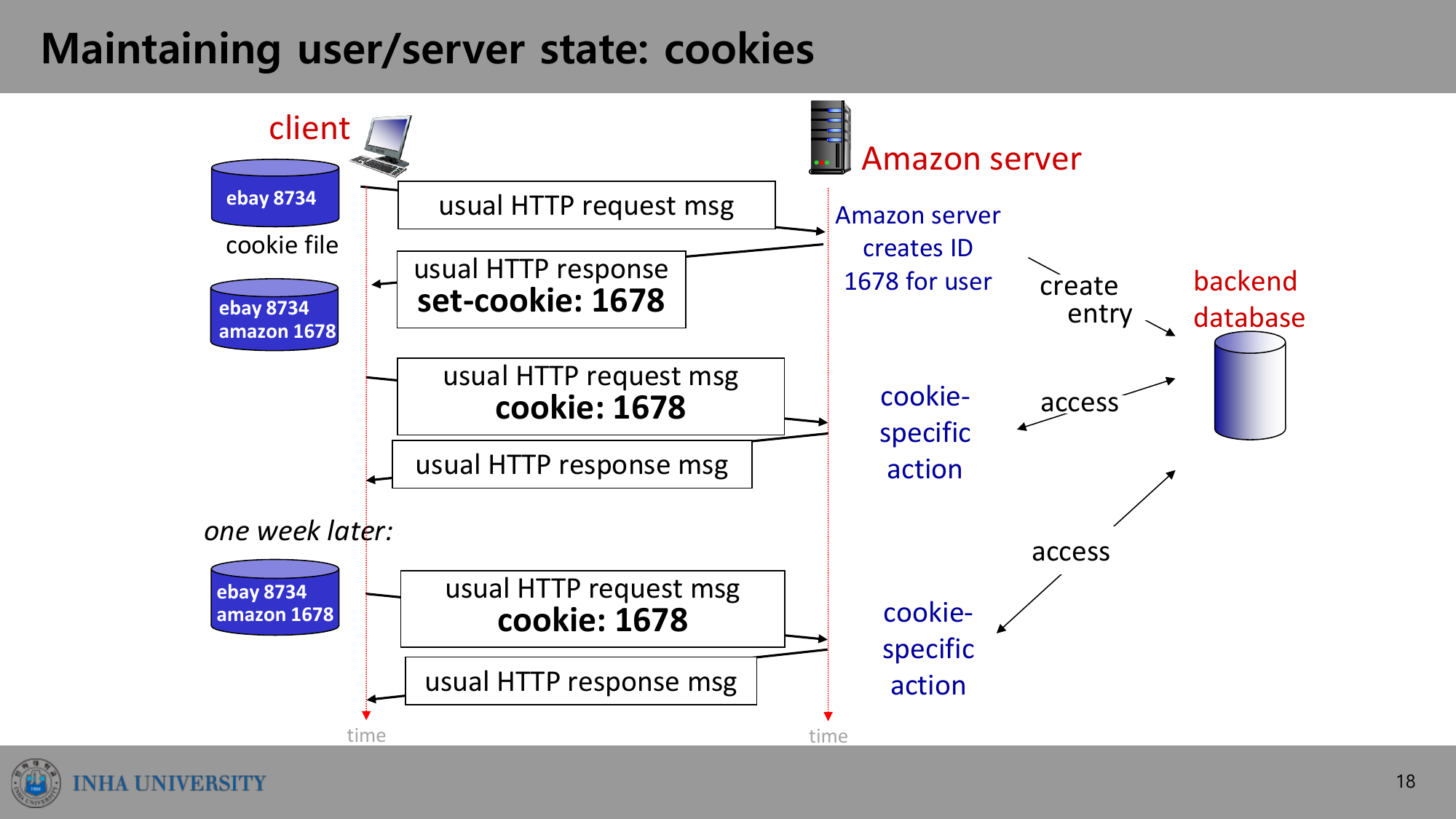
처음 사이트에 접속하면 서버가 고유 ID를 만들어 백엔드 DB에 기록하고, 응답에 Set-cookie: 1678을 담아 보낸다. 브라우저는 이걸 쿠키 파일에 저장한다. 이후 요청부터는 매번 cookie: 1678을 실어 보내므로 서버가 사용자를 식별할 수 있다. 일주일 뒤에 다시 와도 같은 쿠키 값으로 이어진다.
쿠키는 인증(authorization), 장바구니, 추천, 세션 상태 유지 등에 쓰인다. 상태를 유지하는 방법은 두 갈래다 — 프로토콜 양 끝점(endpoint)에서 여러 트랜잭션에 걸쳐 상태를 보관하거나, 메시지 안에 쿠키로 상태를 실어 나르는 것이다.
서드파티 쿠키와 추적
문제는 쿠키가 추적 수단이 된다는 점이다.
- 퍼스트파티 쿠키(first party cookie): 내가 직접 방문한 사이트(base HTML 제공)가 심는 쿠키
- 서드파티 쿠키(third party cookie): 내가 방문한 적 없는 사이트(예: 광고 서버 AdX)가 심는 쿠키
뉴스 사이트에 광고가 박혀 있으면, 그 광고를 가져오는 HTTP GET이 광고 서버 AdX로 가면서 AdX의 쿠키가 심긴다. AdX 광고가 걸린 여러 사이트를 돌아다니면 AdX는 Referrer 헤더로 내가 어떤 사이트를 봤는지 사이트를 넘나들며 추적하고, 그 이력을 바탕으로 타겟 광고를 돌려준다. 추적은 보이지 않게도 가능하다 — 광고 대신 보이지 않는 링크가 GET을 트리거할 수도 있다.
이런 이유로 서드파티 추적 쿠키는 Firefox, Safari에서 기본 차단됐고, GDPR(EU General Data Protection Regulation)은 쿠키가 개인을 식별할 수 있으면 개인정보로 보아 규제 대상으로 삼는다. 그래서 “이 사이트는 쿠키를 사용합니다” 동의 배너가 뜨는 것이다.
HTTP 버전 정리
| 버전 | RFC / 연도 | 핵심 |
|---|---|---|
| HTTP/1.1 | RFC 2616, 1997 | 단일 TCP 연결에서 다중·파이프라인 GET. 서버는 FCFS(선입선출)로 응답 → 작은 객체가 큰 객체 뒤에서 막히는 HOL(Head-of-Line) blocking 발생 |
| HTTP/2 | RFC 7540, 2015 | 클라이언트가 지정한 우선순위로 전송 순서 조정, 요청 안 한 객체도 푸시, 객체를 프레임으로 쪼개 HOL blocking 완화 |
| HTTP/3 | RFC 9114, 2022 | QUIC/UDP 위에서 보안과 객체별 오류·혼잡 제어 추가, 세밀한 파이프라이닝 |
DNS
사람은 cs.umass.edu 같은 이름을 쓰지만, 인터넷 호스트와 라우터는 32비트 IP 주소로 데이터그램을 주소 지정한다. 이름과 주소를 서로 변환해야 한다. 이 일을 하는 게 DNS(Domain Name System)다.
DNS는 두 얼굴을 가진다.
- 분산 데이터베이스(distributed database): 수많은 네임 서버(name server)의 계층 구조로 구현됨
- 응용 계층 프로토콜: 호스트와 DNS 서버가 통신해 이름을 resolve(주소/이름 변환)함
DNS는 인터넷의 핵심 기능이지만 네트워크의 가장자리(edge)에 복잡성을 두는 방식, 즉 응용 계층 프로토콜로 구현됐다.
도메인 계층 구조
도메인 네임스페이스(domain namespace)는 트리 형태로 조직된다. 각 노드를 도메인(domain), 부모 기준으로는 서브도메인(subdomain)이라 부른다. 트리의 뿌리는 ROOT이고 .으로 표기한다.
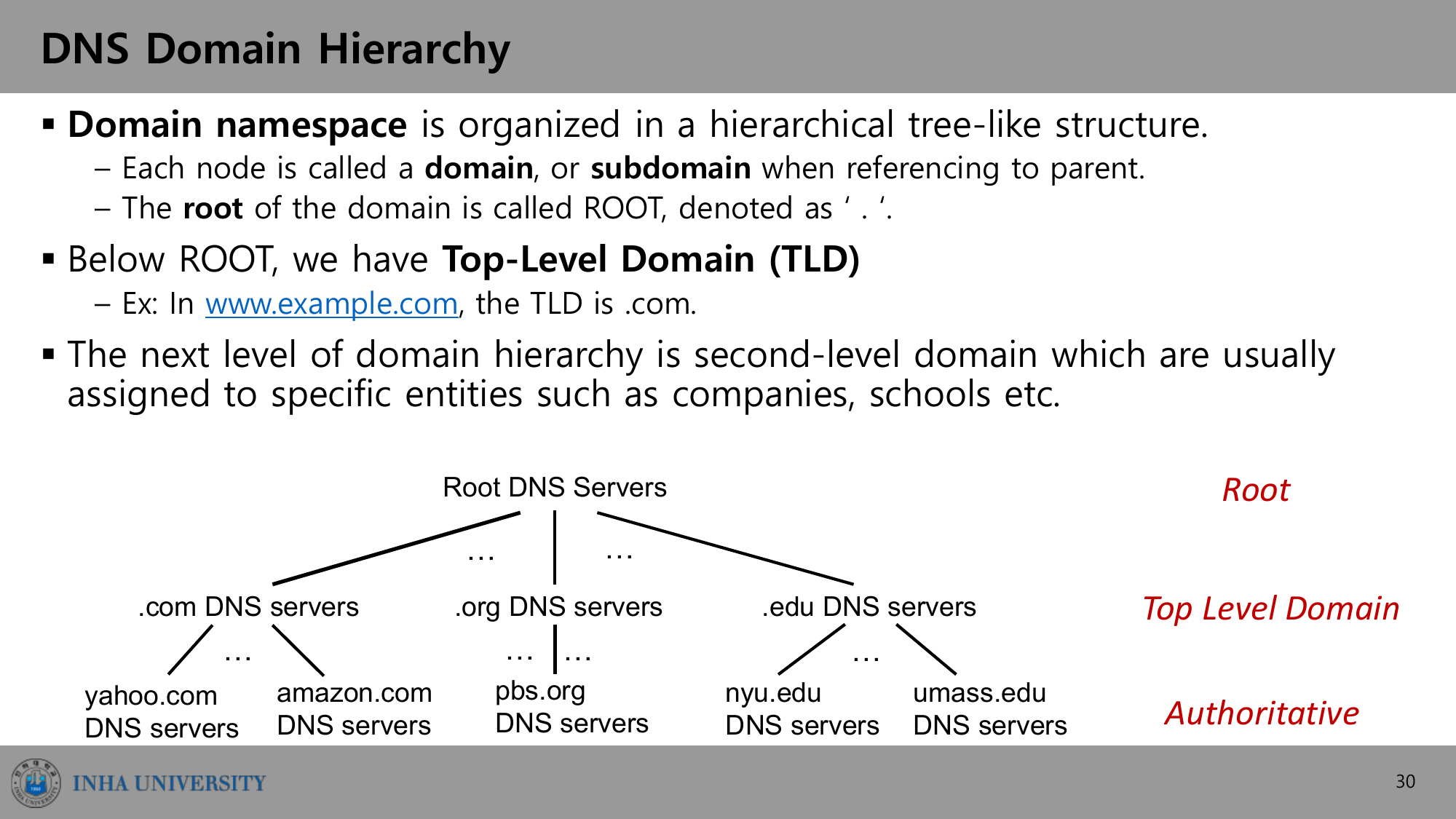
- ROOT: 최상단.
www.example.com을 거꾸로 읽으면 맨 끝의.이 루트 - Top-Level Domain(TLD): 루트 바로 아래.
www.example.com의 TLD는.com - Second-level domain: 그 아래, 보통 회사·학교 같은 특정 주체에 할당
ROOT 서버는 이 트리의 시작점이다. 루트 존(zone)에는 13개의 권한 네임서버(DNS root server, a~m.root-servers.net)가 있고, ICANN이 루트 DNS 도메인을 관리한다. 이들은 모든 TLD의 네임서버 정보(약 2MB)를 제공하며 DNS 질의의 출발점이 된다. 인터넷에서 가장 중요한 인프라다.
TLD는 종류가 나뉜다.
| 종류 | 예시 |
|---|---|
| Infrastructure TLD | .arpa |
| Generic TLD (gTLD) | .com, .net |
| Sponsored TLD (sTLD) | .edu, .gov, .mil, .travel |
| Country Code TLD (ccTLD) | .au, .cn, .fr, .kr |
| Reserved TLD | .example, .test, .localhost, .invalid |
공식 TLD 목록은 IANA(Internet Assigned Numbers Authority)가 관리한다. 각 TLD는 IANA가 지정한 관리자, 즉 레지스트리(registry)에 위임된다. 한국의 .kr은 KISA(한국인터넷진흥원)가 ccTLD 관리자다. 레지스트리는 다시 등록대행자(registrar)들과 계약한다 — GoDaddy, 가비아, 후이즈, 메가존 같은 업체가 실제 등록 업무를 대행한다.
Zone vs Domain
도메인 트리는 네임스페이스가 어떻게 조직되는지를 나타낼 뿐, DNS 시스템이 어떻게 조직되는지와는 다르다. DNS는 존(zone) 단위로 관리된다.
존은 트리 위에서 인접한 도메인·서브도메인을 묶어 하나의 관리 주체(authority)에 권한을 부여한 것이다. 도메인은 권한 정보를 담지 않지만 존은 담는다. 한 도메인이 여러 존으로 쪼개져 여러 주체가 나눠 관리할 수도 있다. 예를 들어 example.com 회사가 나라별 지사의 독립성을 위해 usa.example.com, uk.example.com의 관리 권한을 각 지사로 위임(delegate)하면, 각 지사가 자기 DNS 정보를 직접 관리한다.
도메인이 서브도메인으로 나뉘지 않으면 존과 도메인은 같다. 나뉘더라도 DNS 데이터를 같은 존에 둘 수 있어 여전히 같을 수 있다. 다만 서브도메인은 자기만의 존을 가질 수 있다. 즉 존은 도메인의 DNS 데이터 일부만 담는다.
네임 서버의 종류
권한 네임 서버(authoritative name server): 각 존은 최소 하나의 권한 네임서버를 두고 그 존 정보를 공개한다. DNS 질의에 대한 원본이자 확정적인 답을 준다. 마스터 서버(primary)는 모든 존 레코드의 원본을 저장하고, 슬레이브 서버(secondary)는 자동 갱신으로 마스터의 복사본을 유지한다. 조직이 직접 운영하거나 서비스 제공자에게 맡긴다.
로컬 DNS 네임 서버(local DNS name server): 호스트가 DNS 질의를 하면 우선 로컬 DNS 서버로 간다. 로컬 서버는 최근 변환 쌍을 담은 캐시에서 바로 답하거나, 답이 없으면 DNS 계층으로 질의를 전달한다. 각 ISP가 로컬 DNS 서버를 둔다(macOS는 scutil --dns, Windows는 ipconfig /all로 확인). 로컬 DNS 서버는 엄밀히 말하면 계층 구조에 속하지 않는다.
요즘은 로컬 ISP 서버 대신 1.1.1.1(Cloudflare)이나 8.8.8.8(Google) 같은 기본 DNS 서버를 쓰기도 한다. 응용은 로컬 머신의 DNS resolver에게 IP를 묻고, resolver는 자기 데이터에서 못 찾으면 로컬 DNS 서버(여기서는 recursive resolver)에게 넘긴다. 로컬 머신 쪽 resolver를 stub-resolver라 부른다.
캐싱
어떤 네임 서버든 변환을 한 번 알아내면 그 매핑을 캐시(cache)하고, 이후 같은 질의에는 캐시된 답을 즉시 돌려준다. 캐싱은 응답 시간을 크게 줄인다. 캐시 항목은 TTL(Time To Live) 이후 사라지며, TLD 서버 정보는 보통 로컬 네임 서버에 캐시된다.
대신 캐시는 낡을 수 있다(out-of-date). 이름이 가리키는 호스트가 IP를 바꿔도, 기존 TTL이 모두 만료되기 전까지는 인터넷 전역이 그 변경을 모를 수 있다. DNS는 최선형(best-effort) 이름-주소 변환이다.
로컬 파일도 변환에 관여한다. /etc/hosts는 일부 호스트명의 IP를 담고 있고, 머신은 로컬 DNS 서버에 묻기 전에 이 파일을 먼저 본다. /etc/resolv.conf는 로컬 DNS 서버의 IP 정보를 담는데, DHCP가 받아온 로컬 DNS 서버 주소도 여기 저장된다.
Iterated Query
이름 변환 과정을 보자. engineering.nyu.edu의 호스트가 gaia.cs.umass.edu의 IP를 알고 싶다.
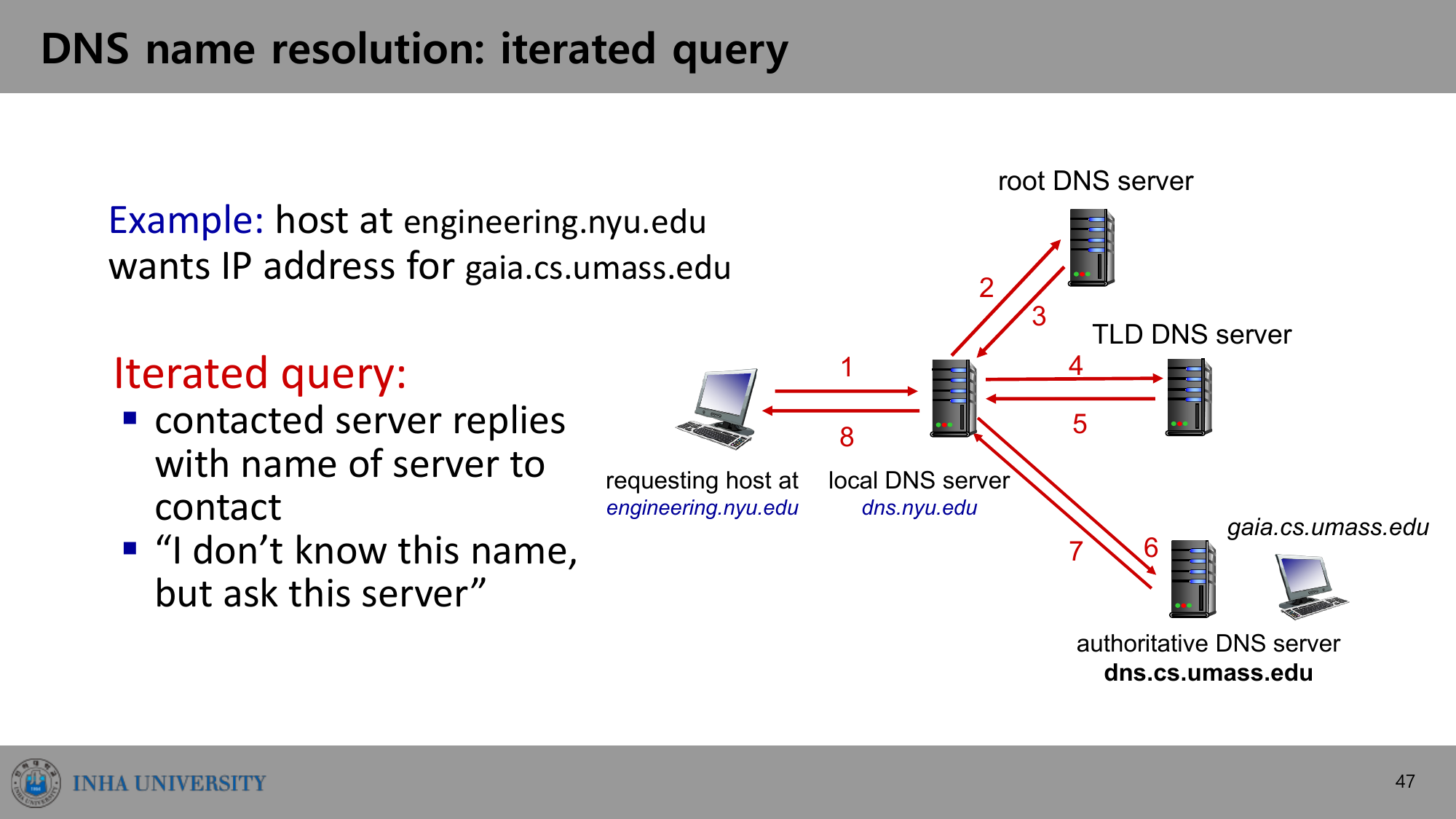
Iterated query(반복 질의)에서 질의 받은 서버는 “나는 이 이름을 모르지만, 저 서버에 물어봐라”라며 다음에 물어볼 서버 이름을 답으로 준다.
- 호스트가 로컬 DNS 서버(
dns.nyu.edu)에 질의 2~3. 로컬 서버가 root DNS 서버에 묻고, root는.eduTLD 서버를 알려줌 4~5. 로컬 서버가 TLD DNS 서버에 묻고, TLD는umass.edu의 권한 서버를 알려줌 6~7. 로컬 서버가 권한 DNS 서버(dns.cs.umass.edu)에 묻고, IP를 받음 - 로컬 서버가 호스트에 최종 답을 전달
DNS 레코드
DNS는 자원 레코드(Resource Record, RR)를 저장하는 분산 DB다. RR 형식은 (name, value, type, ttl)이다. type에 따라 의미가 달라진다.
| type | name | value |
|---|---|---|
| A | 호스트명 | IP 주소 |
| NS | 도메인 (예: foo.com) |
그 도메인의 권한 네임서버 호스트명 |
| CNAME | 별칭(alias) 이름 | 정규(canonical) 이름. www.ibm.com → servereast.backup2.ibm.com |
| MX | 도메인 | 그 도메인의 SMTP 메일 서버 이름 |
DNS 프로토콜 메시지
DNS의 질의(query)와 응답(reply) 메시지는 같은 형식을 쓴다. 헤더에는 identification(16비트 식별자, 응답은 같은 번호를 사용)과 flags(질의/응답, recursion desired, recursion available, reply is authoritative)가 있다. 그 뒤로 질문 수·답변 RR 수·권한 RR 수·추가 RR 수가 오고, 실제 질문/답변/권한/추가 정보 섹션이 따른다.
DNS 응답에는 네 종류의 섹션이 있다.
| 섹션 | 내용 |
|---|---|
| Question | 네임서버에 던지는 질문 |
| Answer | 질문에 답하는 레코드 |
| Authority | 권한 네임서버를 가리키는 레코드 |
| Additional | 질의와 관련된 부가 레코드 |
DNS에 내 정보 등록하기
새 스타트업 “Network Utopia”가 networkutopia.com을 쓰려면, DNS 등록대행자(예: Network Solutions)에 이름을 등록하고 권한 네임서버(primary·secondary)의 이름과 IP를 제공한다. 등록대행자는 .com TLD 서버에 NS·A 레코드를 넣는다.
(networkutopia.com, dns1.networkutopia.com, NS)
(dns1.networkutopia.com, 212.212.212.1, A)
그리고 IP 212.212.212.1의 권한 서버를 직접 세워, www.networkutopia.com의 A 레코드와 networkutopia.com의 MX 레코드를 만든다.
DHCP
호스트가 IP 주소를 얻는 질문은 사실 두 개다 — 호스트가 자기 네트워크 안에서 주소(주소의 호스트 부분)를 얻는 법, 그리고 네트워크가 자신을 위한 주소(주소의 네트워크 부분)를 얻는 법. 앞의 질문을 푸는 게 DHCP다.
호스트가 IP를 얻는 방법은 두 가지다. 관리자가 설정 파일에 하드코딩하거나(예: UNIX /etc/rc.config), DHCP(Dynamic Host Configuration Protocol)로 서버에서 동적으로 받는 것이다. DHCP는 plug-and-play다.
DHCP의 목표는 호스트가 네트워크에 합류할 때 서버로부터 IP를 동적으로 얻는 것이다.
- 사용 중인 주소의 임대(lease)를 갱신할 수 있다
- 주소 재사용이 가능하다 (연결된 동안만 보유)
- 네트워크를 드나드는 모바일 사용자를 지원한다
DHCP 4단계
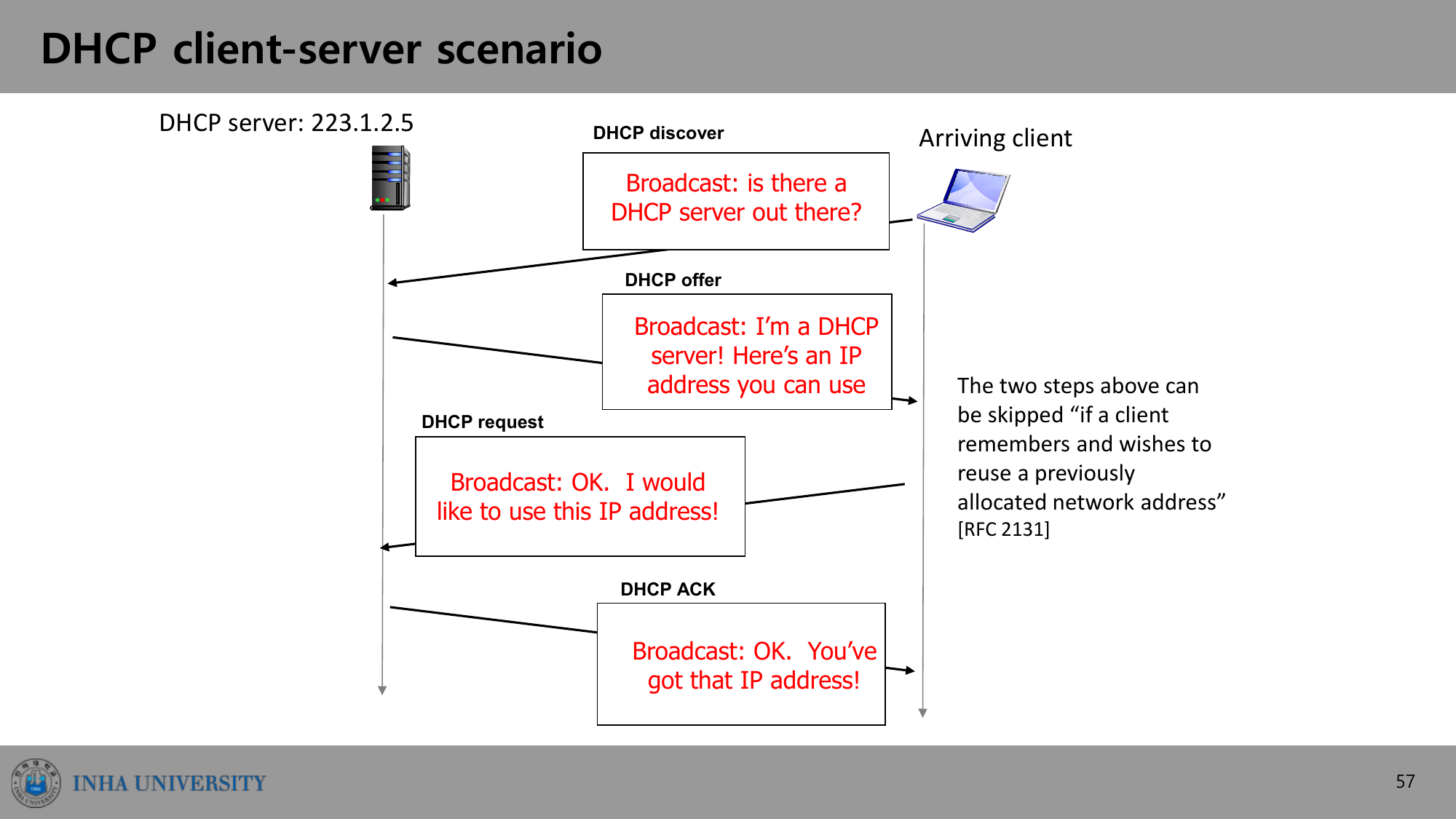
호스트가 막 네트워크에 들어오면 네 단계로 주소를 받는다. 모두 브로드캐스트(broadcast)로 오간다.
- DHCP discover — 호스트: “DHCP 서버 있나요?” (선택)
- DHCP offer — 서버: “내가 DHCP 서버다, 이 IP를 써라” (선택)
- DHCP request — 호스트: “이 IP를 쓰겠다”
- DHCP ACK — 서버: “그 IP는 네 것이다”
앞의 두 단계(discover/offer)는 클라이언트가 이전에 할당받은 주소를 기억하고 재사용하려는 경우 생략할 수 있다(RFC 2131). 보통 DHCP 서버는 라우터에 함께 들어가 있어, 라우터에 연결된 모든 서브넷을 서비스한다.
DHCP는 IP 주소만 주는 게 아니다
DHCP는 할당된 IP 외에도 다음을 함께 돌려준다.
- 클라이언트의 first-hop 라우터 주소
- DNS 서버의 이름과 IP 주소
- 네트워크 마스크(network mask) (주소의 네트워크 부분과 호스트 부분 구분)
동작은 캡슐화로 이뤄진다. DHCP 요청 메시지는 UDP → IP → Ethernet 순으로 캡슐화되고, 이더넷 프레임은 브로드캐스트(목적지 FFFFFFFFFFFF)로 LAN에 뿌려져 DHCP 서버를 돌리는 라우터가 받는다. 받은 쪽은 Ethernet → IP → UDP → DHCP로 역다중화(de-mux)해 올린다. 서버가 만든 DHCP ACK도 같은 방식으로 클라이언트까지 거슬러 올라간다. 끝나면 클라이언트는 자기 IP, DNS 서버 이름·주소, first-hop 라우터 주소를 모두 알게 된다.
웹 요청 한 번에 일어나는 일
지금까지 본 프로토콜들이 어떻게 한꺼번에 얽히는지 보자. 시나리오: 학생이 노트북을 학교 네트워크에 연결하고 www.google.com을 요청한다. 간단해 보이지만 응용·전송·네트워크·링크 계층이 전부 동원된다.
1) DHCP — 네트워크 합류 노트북은 자기 IP, first-hop 라우터 주소, DNS 서버 주소가 필요하다. DHCP를 쓴다. DHCP 요청이 UDP→IP→802.3 이더넷으로 캡슐화돼 브로드캐스트되고, 라우터의 DHCP 서버가 ACK로 응답한다. 이제 노트북은 IP, DNS 서버, first-hop 라우터를 안다.
2) ARP — 라우터의 MAC 주소 알아내기
HTTP 요청을 보내려면 www.google.com의 IP가 필요하고, 그건 DNS로 알아낸다. DNS 질의는 UDP→IP→Ethernet으로 캡슐화되는데, 프레임을 라우터로 보내려면 라우터 인터페이스의 MAC 주소가 필요하다. ARP를 쓴다. ARP query를 브로드캐스트하면 라우터가 ARP reply로 자기 MAC을 알려준다. 이제 DNS 질의를 담은 프레임을 보낼 수 있다.
3) DNS — 도메인을 IP로
DNS 질의를 담은 IP 데이터그램이 LAN 스위치를 거쳐 first-hop 라우터로, 다시 학교 네트워크에서 Comcast 네트워크로 라우팅된다(라우팅 테이블은 RIP, OSPF, IS-IS, BGP 같은 프로토콜이 만든다). DNS 서버까지 도달해 역다중화되고, DNS 서버가 www.google.com의 IP를 답으로 돌려준다.
4) TCP — 연결 수립 HTTP 요청을 보내기 전에 클라이언트는 웹 서버로 TCP 소켓을 연다. TCP SYN 세그먼트(3-way handshake 1단계)가 웹 서버로 라우팅되고, 서버가 SYNACK(2단계)으로 응답하면 TCP 연결이 수립된다.
5) HTTP — 페이지 받기
HTTP 요청이 TCP 소켓으로 들어가고, 이를 담은 IP 데이터그램이 www.google.com으로 라우팅된다. 웹 서버가 웹 페이지를 담은 HTTP 응답을 돌려주고, 그 데이터그램이 클라이언트로 라우팅되면 브라우저가 마침내 페이지를 그린다.
주소를 입력하고 페이지가 뜨기까지 DHCP, ARP, DNS, TCP, HTTP가 그리고 그 밑의 라우팅 프로토콜들이 순서대로 맞물려 돌아간다. “간단해 보이는” 웹 요청 하나가 응용 계층부터 링크 계층까지 프로토콜 스택 전체를 관통한다.