Computer System Overview — 컴퓨터 시스템 개요
운영체제를 이해하려면 그 위에 올라가는 하드웨어를 먼저 알아야 한다. 프로세서는 어떻게 명령어를 실행하고, 인터럽트는 왜 필요하며, 메모리는 어떤 계층으로 구성되는가. 이 글에서는 컴퓨터 시스템의 전체적인 구조를 다룬다.
기본 구성 요소
컴퓨터는 데이터의 처리, 저장, 이동을 위한 자원의 집합이다. 핵심 구성 요소는 네 가지다.
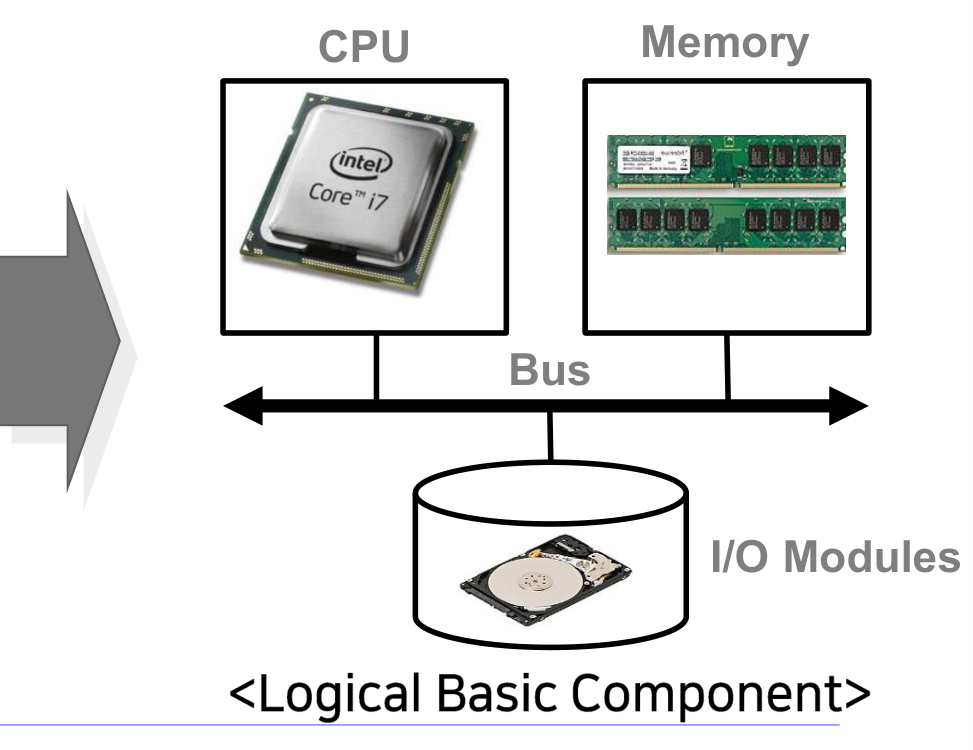
| 구성 요소 | 역할 |
|---|---|
| 프로세서(Processor, CPU) | 프로그램을 실행하는 하드웨어. 명령어를 해석하고 실행한다 |
| 메모리(Memory) | 프로그램의 데이터와 코드를 저장한다. 휘발성(volatile)이다 |
| I/O 모듈(I/O Modules) | 컴퓨터와 외부 장치(모니터, 디스크 등) 사이에서 데이터를 이동시킨다 |
| 버스(Bus) | 위 세 요소를 연결하는 데이터 통로이다 |
I/O 모듈은 다시 I/O 컨트롤러(하드웨어 제어 로직)와 I/O 디바이스(실제 장치)로 나뉜다.
프로그램과 프로세스
- 프로그램(Program): 특정 작업을 수행하기 위한 명령어들의 집합이다
- 프로세스(Process): 메모리에 로드되어 실행 중이거나 실행 대기 중인 프로그램이다
C 소스코드가 컴파일되면 기계어(Machine Code)로 변환된다. 이 바이너리가 디스크에 저장된 상태가 프로그램이고, 이를 메모리에 올려 실행하면 프로세스가 된다.
소스코드(.c) → [컴파일러] → 기계어 바이너리(디스크) → [실행] → 프로세스(메모리)
프로세서(CPU)
CPU(Central Processing Unit)는 프로그램의 명령어를 해석하고 실행하는 하드웨어이다.
CPU 내부의 핵심 구성 요소:
- ALU(Arithmetic/Logic Unit): 산술 연산(덧셈, 뺄셈)과 논리 연산(비교, Boolean)을 수행한다
- 레지스터(Register): 현재 사용 중인 데이터나 명령어를 임시로 저장하는 초고속 저장소이다
멀티프로세서와 프로세서의 진화
현대 CPU는 하나의 칩 안에 여러 개의 프로세서(코어)를 넣은 멀티프로세서(Multiprocessor) 구조이다. 각 코어는 독립적인 캐시 메모리를 가진다.
| 프로세서 | 클럭 속도 | 전력 |
|---|---|---|
| PIC | ~10 MHz | ~mW |
| Z80 | ~10 MHz | ~mW |
| ARM PXA | 400 MHz | ~500 mW |
| PowerPC MPC | 500 MHz | 2 W |
| Pentium | 2 GHz | 115 W |
클럭 속도는 지속적으로 올라왔지만, 전력 소모도 함께 급증했다. 이것이 전력 장벽(Power Wall)이다.
GPU(Graphical Processing Unit)는 대규모 병렬 연산에 특화된 프로세서이다. 그래픽뿐 아니라 AI 연산에도 쓰인다. SIMD(Single-Instruction Multiple Data) 방식으로 배열 데이터를 효율적으로 처리한다.
SoC(System on a Chip)는 모바일 기기용으로, CPU + GPU + NPU(Neural Processing Unit) + 코덱 + 메모리를 하나의 칩에 통합한 구조이다. Snapdragon, Exynos, Kirin 등이 대표적이다.
폰 노이만 병목
폰 노이만 아키텍처(Von Neumann Architecture)는 프로세서와 메모리가 버스로 연결된 구조이다. 명령어 fetch와 데이터 연산을 동시에 수행할 수 없다는 근본적인 한계가 있다. CPU와 메모리 사이의 버스 대역폭이 제한적이라 데이터 이동에 병목이 발생하는데, 이를 폰 노이만 병목(Von Neumann Bottleneck)이라 한다.
이 병목을 해소하기 위한 접근법:
- HBM(High Bandwidth Memory): 메모리 대역폭을 대폭 높여 병목을 완화한다
- 뉴로모픽 아키텍처(Neuromorphic Architecture): 연산과 메모리를 하나로 합쳐 데이터 이동 자체를 최소화한다. Intel Loihi2, IBM TrueNorth 등이 있다
메모리
RAM: SRAM vs DRAM
RAM(Random Access Memory)은 휘발성 메모리이다. 전원이 꺼지면 데이터가 사라진다.
| 특성 | SRAM | DRAM |
|---|---|---|
| 밀도 | 낮음 (6 트랜지스터/bit) | 높음 (1 트랜지스터/bit) |
| 속도 | 빠름 (~2 ns) | 느림 (~15 ns) |
| 가격 | 비쌈 | 저렴 |
| 리프레시 | 불필요 | 필요 |
| 용도 | 캐시(Cache) | 메인 메모리 |
SRAM은 플립플롭(flip-flop) 기반이라 리프레시가 필요 없고 빠르지만, 비싸고 집적도가 낮다. 그래서 CPU 내부의 캐시에 쓰인다. DRAM은 커패시터 기반으로 주기적인 리프레시가 필요하지만, 가격 대비 용량이 커서 메인 메모리로 쓰인다.
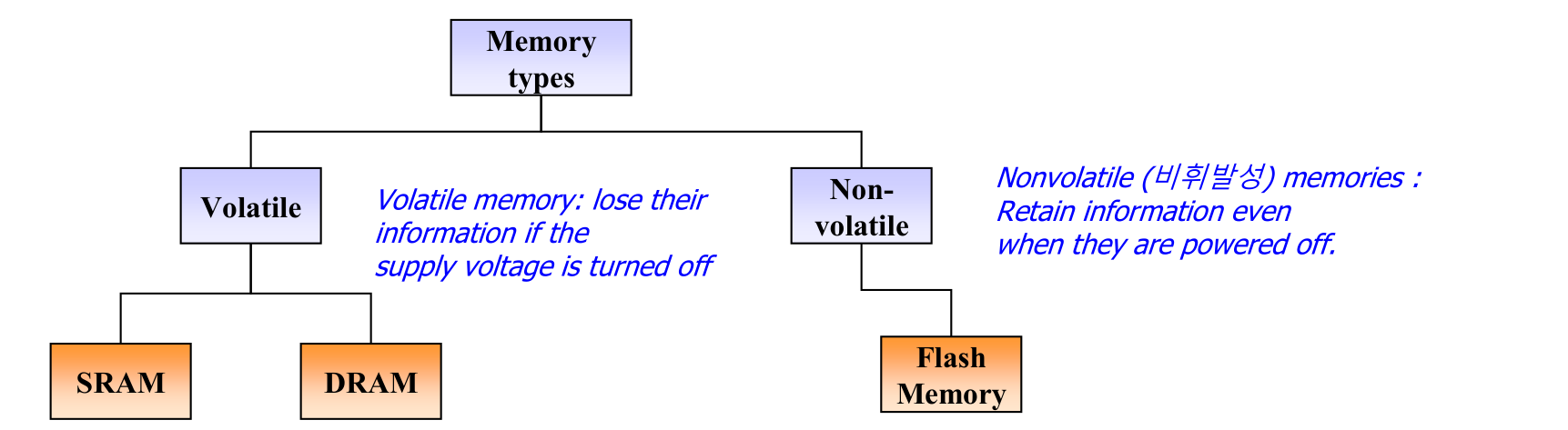
비휘발성 메모리
비휘발성(Non-volatile) 메모리는 전원이 꺼져도 데이터를 유지한다.
플래시 메모리(Flash Memory)의 세 가지 핵심 특성:
- 비대칭 읽기/쓰기: 읽기(~20 us)가 쓰기(~200 us)보다 빠르다
- 제자리 갱신 불가(No in-place update): 이미 쓰여진 페이지에 바로 덮어쓸 수 없다. 해당 페이지가 속한 블록 전체를 지운 뒤 다시 써야 한다
- 제한된 수명(Limited endurance): 블록당 약 10만 번 쓰기 후 마모된다. 마모된 블록은 사용 불가능하다
플래시 메모리는 Floating Gate에 전자를 가두거나 빼는 방식으로 데이터를 저장한다. 이를 반복하면 절연체(산화막)가 물리적으로 손상되어 전자가 새어나가고, 데이터를 보존할 수 없게 된다.
HDD(Hard Disk Drive)는 자기 저장 매체 기반의 비휘발성 장치이다. 읽기/쓰기에 5~35 ms가 소요된다.
SSD(Solid State Disk)는 플래시 메모리를 사용한 디스크이다. I/O 버스의 표준 디스크 슬롯에 연결되며 일반 디스크처럼 동작한다. 내부적으로 FTL(Flash Translation Layer)이 플래시의 특이한 동작(제자리 갱신 불가 등)을 감추고 HDD처럼 사용할 수 있게 해준다.
이종 메모리와 CXL
GPU 연산에서는 CPU 호스트 메모리와 GPU 로컬 메모리 사이의 데이터 이동이 PCI 버스 병목을 유발한다. 자주 쓰는 hot data는 GPU 로컬 메모리에, 자주 쓰지 않는 cold data는 CPU 호스트 메모리에 두는 전략이 필요하다.
CXL(Compute Express Link)은 PCIe 기반으로 CPU에 연결되는 새로운 메모리 기술이다. CPU 입장에서는 일반 메모리처럼 보이며 바이트 단위의 load/store로 접근 가능하다. DRAM을 fast tier(~100 ns), CXL 메모리를 slow tier(~200 ns)로 구성하는 메모리 티어링(Memory Tiering) 방식으로 대용량 메모리를 확보한다.
저장장치 접근 속도 비교
| 구성 요소 | 접근 시간 | 체감 비유 (프로세서 사이클 = 1초) |
|---|---|---|
| 프로세서 사이클 | 0.5 ns (2 GHz) | 1초 |
| 캐시 접근 | 2 ns | 4초 |
| 메모리 접근 | 15 ns | 30초 |
| SSD 접근 | 50,000 ns (50 us) | 27시간 |
| 디스크 접근 | 7,000,000 ns (7 ms) | 162일 |
캐시 접근이 4초라면 디스크 접근은 162일이다. 이 격차가 메모리 계층 구조가 존재하는 이유이다.
프로세서 레지스터
레지스터는 CPU 내부의 초고속 저장소이다. 메모리 접근을 최소화하기 위해 중간 결과나 데이터를 임시 저장하는 역할을 한다.
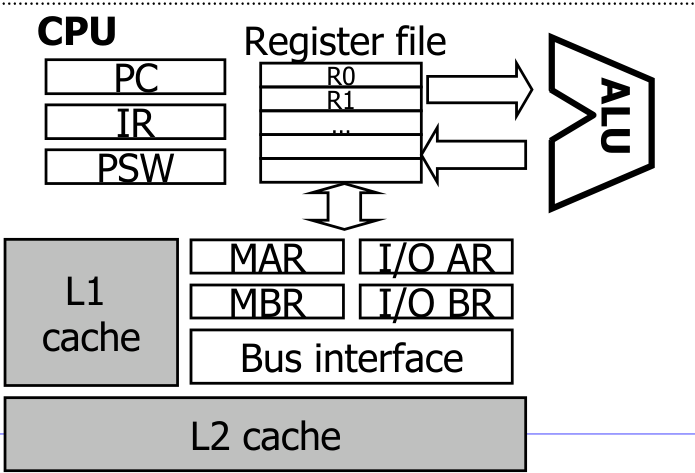
범용 레지스터(General Purpose Registers)
연산의 중간 결과나 데이터 값을 임시로 저장한다. x86 계열 CPU는 최소 8개의 범용 레지스터를 가진다. 레지스터 파일(Register File)이라는 단위로 묶여 ALU에 연결된다.
특수 목적 레지스터(Special-Purpose Registers)
| 레지스터 | 역할 |
|---|---|
| PC(Program Counter) | 다음에 실행할 명령어의 메모리 주소를 저장한다 |
| IR(Instruction Register) | 가장 최근에 fetch된 명령어를 저장한다 |
| PSW(Program Status Word) | CPU의 현재 상태(condition code, 인터럽트 마스크, 특권 수준 등)를 저장한다 |
| MAR(Memory Address Register) | 다음에 읽거나 쓸 메모리 주소를 저장한다 |
| MBR(Memory Buffer Register) | MAR이 가리키는 주소의 데이터를 저장한다. Memory Data Register(MDR)와 같은 의미이다 |
그 외 I/O AR(I/O 주소 레지스터)과 I/O BR(I/O 버퍼 레지스터)이 I/O 모듈과의 통신에 사용된다.
PSW의 Condition Code는 산술/논리 연산 결과에 따라 자동으로 갱신되는 플래그이다. OF(Overflow Flag), ZF(Zero Flag) 등이 있다.
명령어 집합 구조(ISA)와 명령어 형식
ISA(Instruction Set Architecture)는 소프트웨어와 하드웨어 사이의 인터페이스를 정의한다. 프로세서가 실행할 수 있는 명령어 집합과 머신 상태(Machine State) = 레지스터 + 메모리를 규정한다. x86, x86-64, IA64, ARM 등이 대표적인 ISA이다.
명령어 형식(Instruction Format)은 명령어의 비트 구조를 정의하는 머신 고유의 템플릿이다. 예를 들어 16비트 고정 크기 명령어라면:
| Opcode (4 bits) | Address (12 bits) |
| 0 3 4 | 15 |
- Opcode(연산자): 수행할 연산을 지정한다. 예:
0001= Load,0010= Store,0101= Add - Operand(피연산자): 입출력 데이터 또는 그 주소를 지정한다
명령어가 수행하는 동작은 네 가지로 분류된다:
| 유형 | 설명 | 예시 |
|---|---|---|
| 데이터 처리 | 산술/논리 연산 | add, sub |
| 제어 | 실행 흐름 변경 | jump, call |
| 프로세서-메모리 | 메모리 읽기/쓰기 | load, store |
| 프로세서-I/O | I/O 장치와 통신 | in, out |
명령어 사이클(Instruction Cycle)
프로세서는 하나의 명령어를 Fetch → Decode → Execute 세 단계로 처리한다. 이를 명령어 사이클(Instruction Cycle)이라 한다.
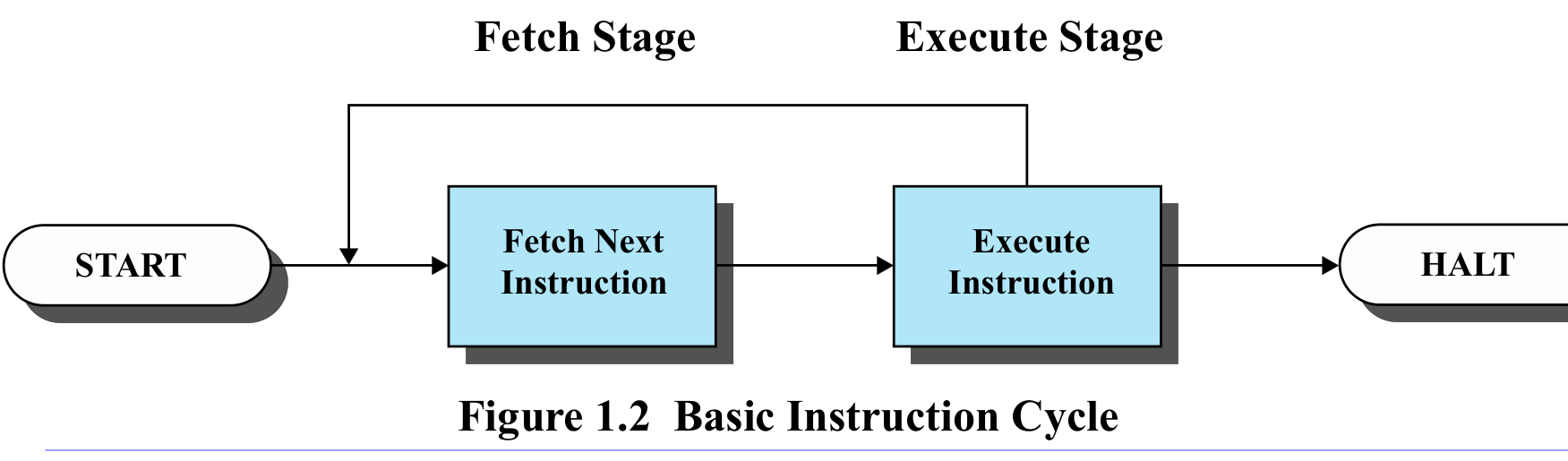
Fetch-Decode-Execute
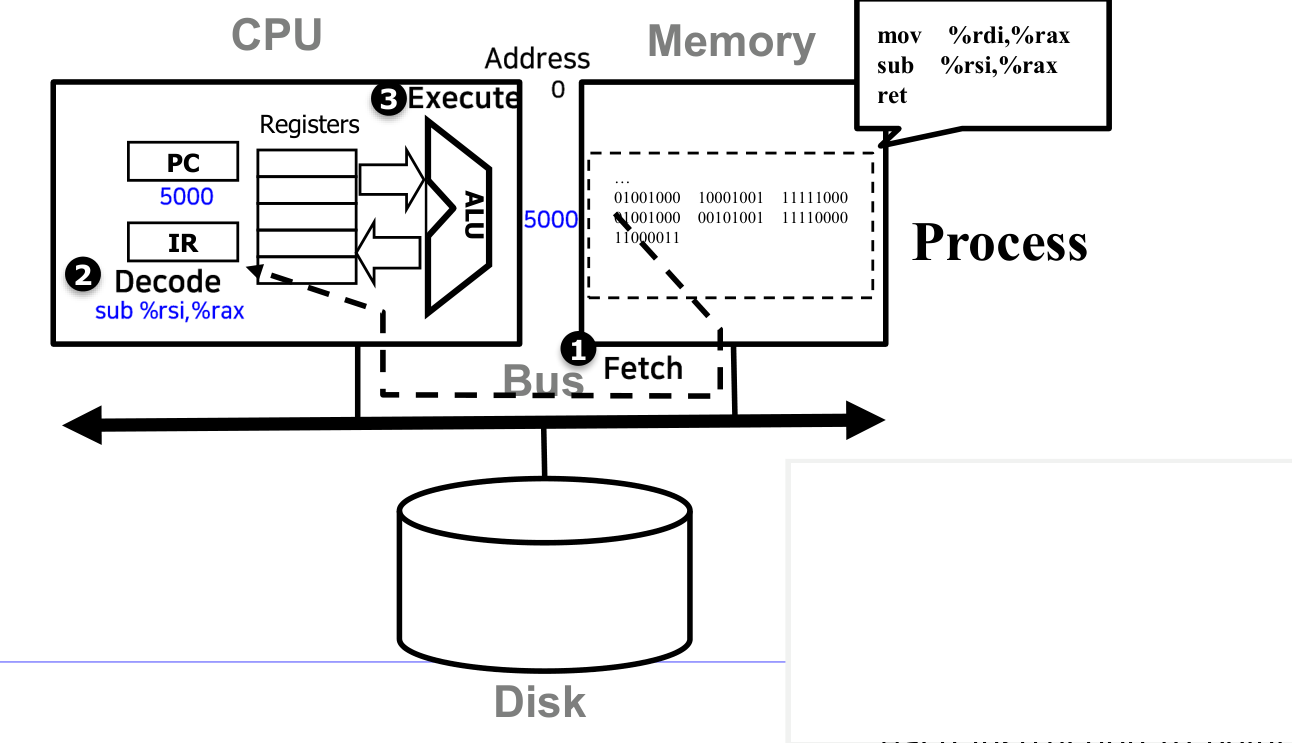
- Fetch: PC가 가리키는 주소에서 명령어를 읽어 IR에 저장한다
- Decode: IR에 있는 명령어를 해석한다. opcode가 무엇인지, operand가 어디인지 파악한다
- Execute: 해석된 연산을 ALU 등을 통해 실제로 수행한다
이 과정에서 MAR과 MBR이 메모리와의 통신을 중개한다. PC는 매 사이클마다 다음 명령어 주소로 갱신된다.
프로그램 실행 예제
다음은 1940, 5941, 2941이라는 세 명령어가 메모리 주소 300~302에 저장된 상태에서의 실행 과정이다. 데이터로는 주소 940에 0003, 941에 0002가 있다.
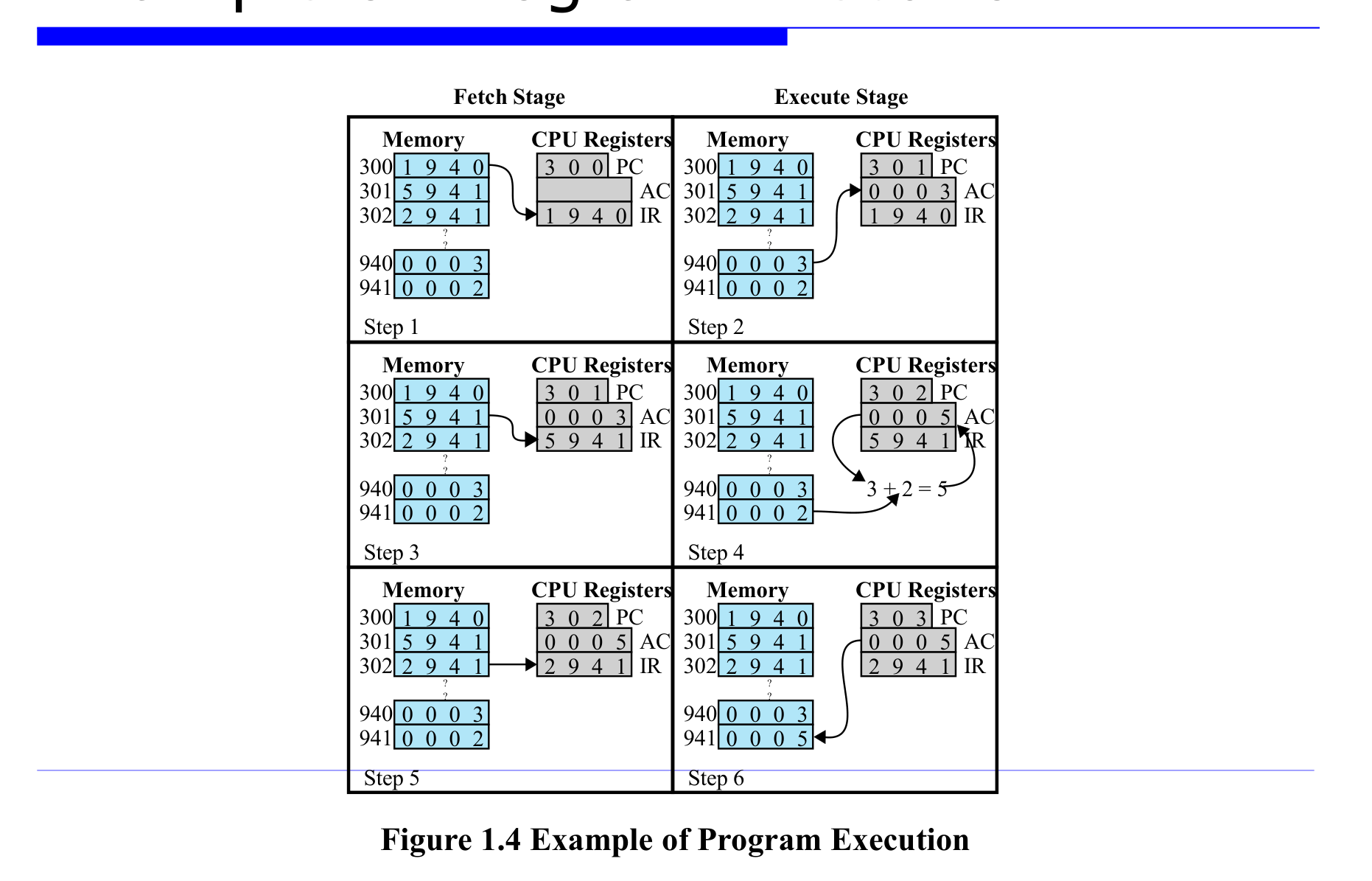
| Step | 단계 | 동작 | PC | AC | IR |
|---|---|---|---|---|---|
| 1 | Fetch | 주소 300에서 명령어 1940을 가져온다 |
300→301 | - | 1940 |
| 2 | Execute | 1940 = Load AC from 940 → AC에 0003 적재 |
301 | 0003 | 1940 |
| 3 | Fetch | 주소 301에서 명령어 5941을 가져온다 |
301→302 | 0003 | 5941 |
| 4 | Execute | 5941 = Add to AC from 941 → AC = 3 + 2 = 0005 |
302 | 0005 | 5941 |
| 5 | Fetch | 주소 302에서 명령어 2941을 가져온다 |
302→303 | 0005 | 2941 |
| 6 | Execute | 2941 = Store AC to 941 → 주소 941에 0005 저장 |
303 | 0005 | 2941 |
결국 이 프로그램은 int x = 3; int y = 2; y = x + y;와 같은 연산을 수행한 것이다.
인터럽트(Interrupt)
왜 인터럽트가 필요한가
프로세서가 하는 일은 단 하나, 명령어 실행이다. 시작부터 종료까지 PC가 가리키는 주소의 명령어를 순차적으로 fetch-decode-execute한다.
여기서 문제가 발생한다. 프로세스가 무한 루프에 빠지면 CPU를 독점해 버린다. 또한 I/O 작업 중에 CPU가 완료를 기다리며 놀고 있는 것도 낭비이다.
인터럽트는 이 문제들을 해결한다:
- 시의성(Timely Service): 긴급하거나 시간에 민감한 이벤트를 빠르게 처리한다
- 시스템 활용도(System Utilization): I/O 장치가 작업하는 동안 CPU가 다른 일을 할 수 있다
- 독점 방지(Prevention of Monopolization): 타이머 인터럽트로 프로세스의 CPU 독점을 막는다
인터럽트 메커니즘
인터럽트(Interrupt)는 현재 프로세스를 중단하고 인터럽트 핸들러로 제어를 이동시키는 하드웨어 이벤트이다. 처리가 끝나면 반드시 원래 프로세스로 복귀해야 한다.
명령어 사이클에 인터럽트 단계가 추가되면 다음과 같다:
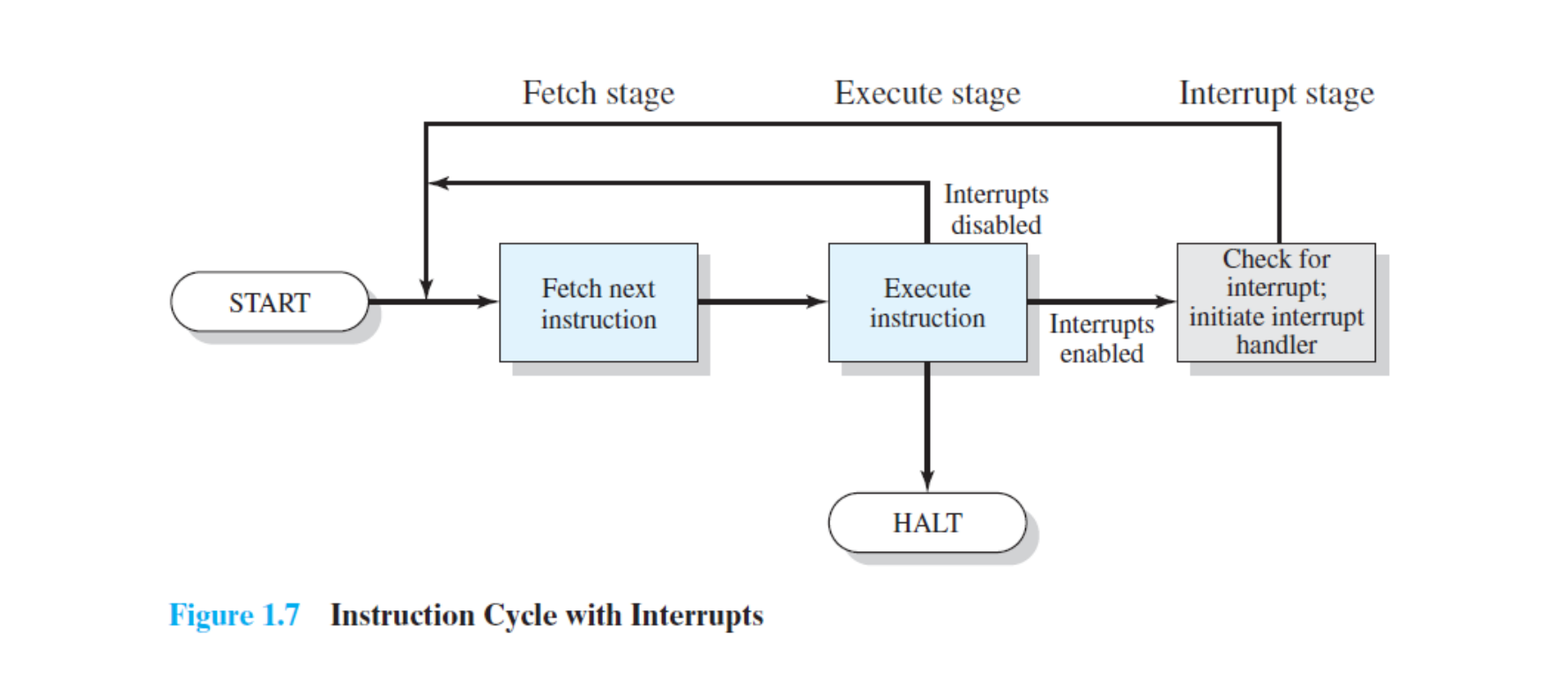
각 명령어 실행 후 인터럽트 발생 여부를 확인한다. 인터럽트가 비활성화(disabled) 상태이면 바로 다음 fetch로 넘어가고, 활성화(enabled) 상태이면 인터럽트를 확인하여 핸들러를 호출한다.
인터럽트 발생 시 처리 과정
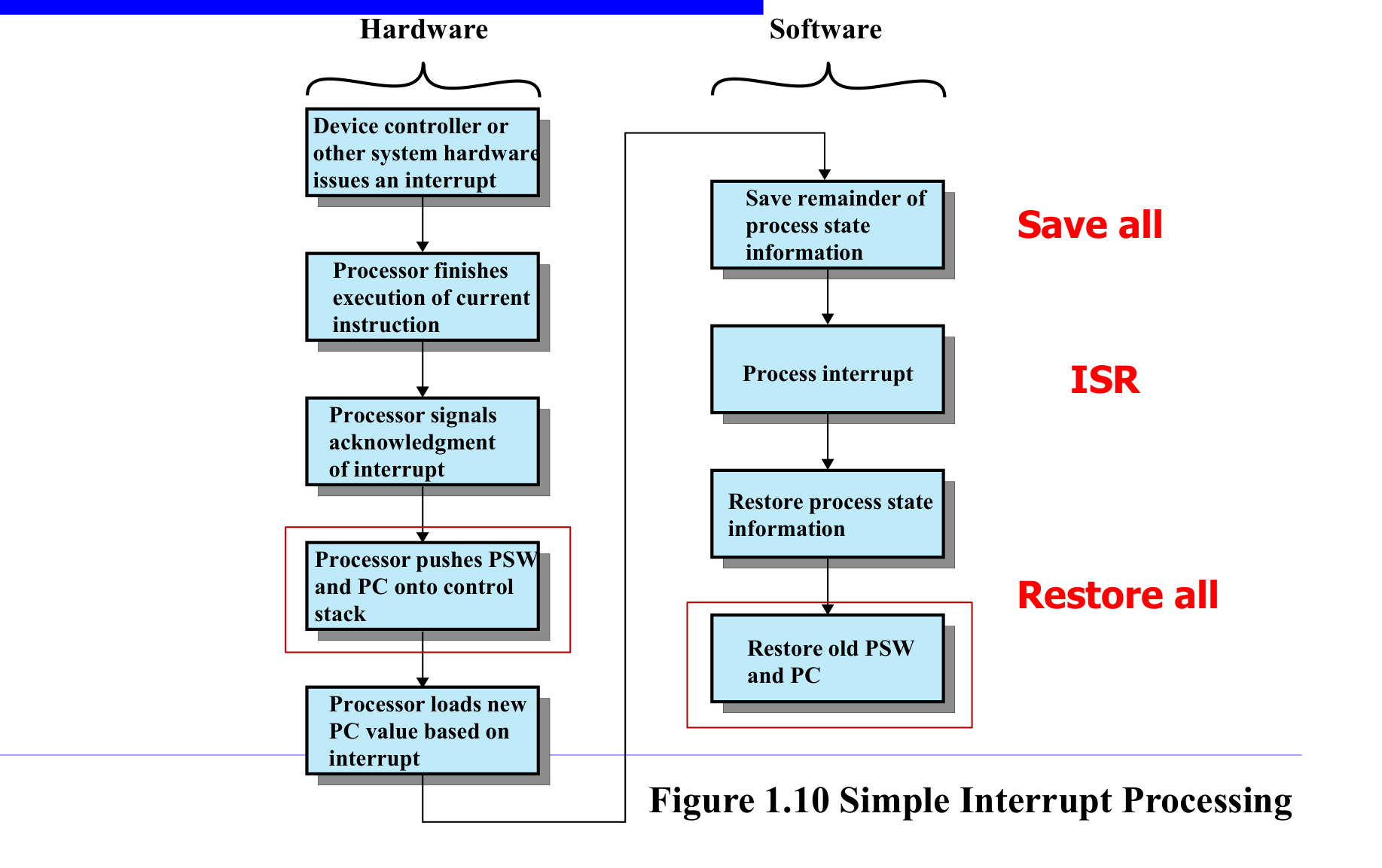
인터럽트 처리는 하드웨어 단계와 소프트웨어 단계로 나뉜다.
하드웨어 단계 (CPU가 자동으로 수행):
- 장치 컨트롤러가 인터럽트를 발생시킨다
- CPU가 현재 명령어 실행을 완료한다
- CPU가 인터럽트 수신을 확인(ACK)한다
- PC와 PSW를 스택에 push한다 (돌아올 주소 + 상태 저장)
- PC에 인터럽트 핸들러의 주소를 load한다
소프트웨어 단계 (OS 코드가 수행):
- Save all: 나머지 레지스터를 모두 저장한다
- ISR(Interrupt Service Routine) 실행: 실제 인터럽트를 처리한다
- Restore all: 저장한 레지스터를 복원한다
- 스택에서 PC와 PSW를 pop하여 원래 프로세스로 복귀한다
Linux에서의 구현을 보면, entry.S의 common_interrupt에서 save all → call do_IRQ → restore all을 수행한다. do_IRQ(n)은 irq_desc[] 배열에서 IRQ 번호에 해당하는 ISR을 찾아 호출한다.
인터럽트 유무에 따른 프로그램 흐름
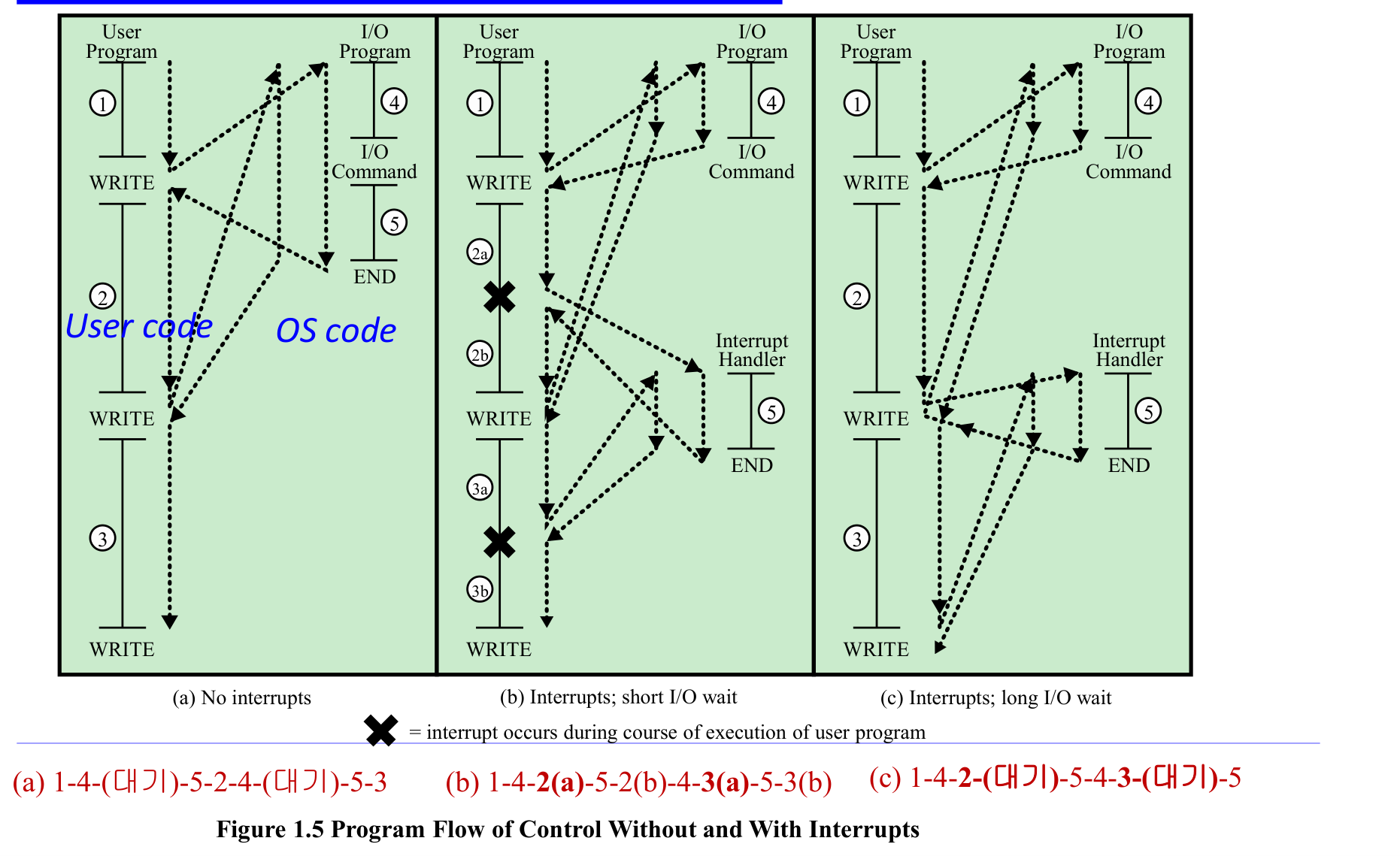
(a) 인터럽트 없음: 사용자 프로그램이 I/O 명령(WRITE)을 내리면 I/O 완료까지 CPU가 대기한다. 실행 순서는 1-4-(대기)-5-2-4-(대기)-5-3.
(b) 인터럽트, 짧은 I/O 대기: I/O 시작 후 CPU가 다음 코드를 바로 실행한다. I/O 완료 시 인터럽트로 알려준다. 1-4-2(a)-5-2(b)-4-3(a)-5-3(b).
(c) 인터럽트, 긴 I/O 대기: I/O가 오래 걸리면 사용자 코드가 먼저 끝나고 I/O 완료를 기다린다. 1-4-2-(대기)-5-4-3-(대기)-5.
핵심은 (b) 상황이다. 인터럽트 덕분에 I/O와 CPU 연산이 동시에 진행되어 전체 시간이 단축된다. 대신 모드 스위치 오버헤드가 발생한다.
PIC(Programmable Interrupt Controller)
여러 I/O 장치의 인터럽트 신호를 받아 IRQ(Interrupt Request) 번호로 변환하고, CPU에 전달하는 하드웨어이다. Intel 8259A가 대표적이다.
PIC의 동작:
- I/O 컨트롤러로부터 인터럽트 신호를 받는다
- 디바이스의 요청을 IRQ 번호로 변환한다
- CPU에 인터럽트를 발생시키고 IRQ 번호를 전달한다
- CPU의 ACK를 기다린다
PIC의 핵심 기능:
- 우선순위 변경: 인터럽트 간 우선순위를 설정할 수 있다
- 마스킹(Masking): 특정 인터럽트를 비활성화(끄기)할 수 있다
- 다수 장치 관리: 많은 수의 장치로부터의 인터럽트를 효율적으로 처리한다
인터럽트와 예외(Exception)
인터럽트는 두 종류로 나뉜다.
| 구분 | 인터럽트(Interrupt) | 예외(Exception) |
|---|---|---|
| 원인 | CPU 외부 (I/O 장치, 타이머 등) | CPU 내부 (명령어 실행 중 발생) |
| 동기성 | CPU 클럭과 비동기(Asynchronous) | CPU 클럭과 동기(Synchronous) |
| 현재 명령어 | 현재 명령어를 완료한 뒤 처리 | 현재 명령어가 완료되지 않을 수 있다 |
| 예시 | I/O 장치, 타이머 | illegal opcode, illegal address, divide by zero |
시스템 콜(System Call)도 의도적으로 발생시키는 예외(Intentional Exception)의 일종이다. Linux에서는 인터럽트와 예외를 동일한 방식으로 처리한다.
다중 인터럽트 처리
인터럽트 처리 중에 또 다른 인터럽트가 발생하면 어떻게 할 것인가. 두 가지 방식이 있다.
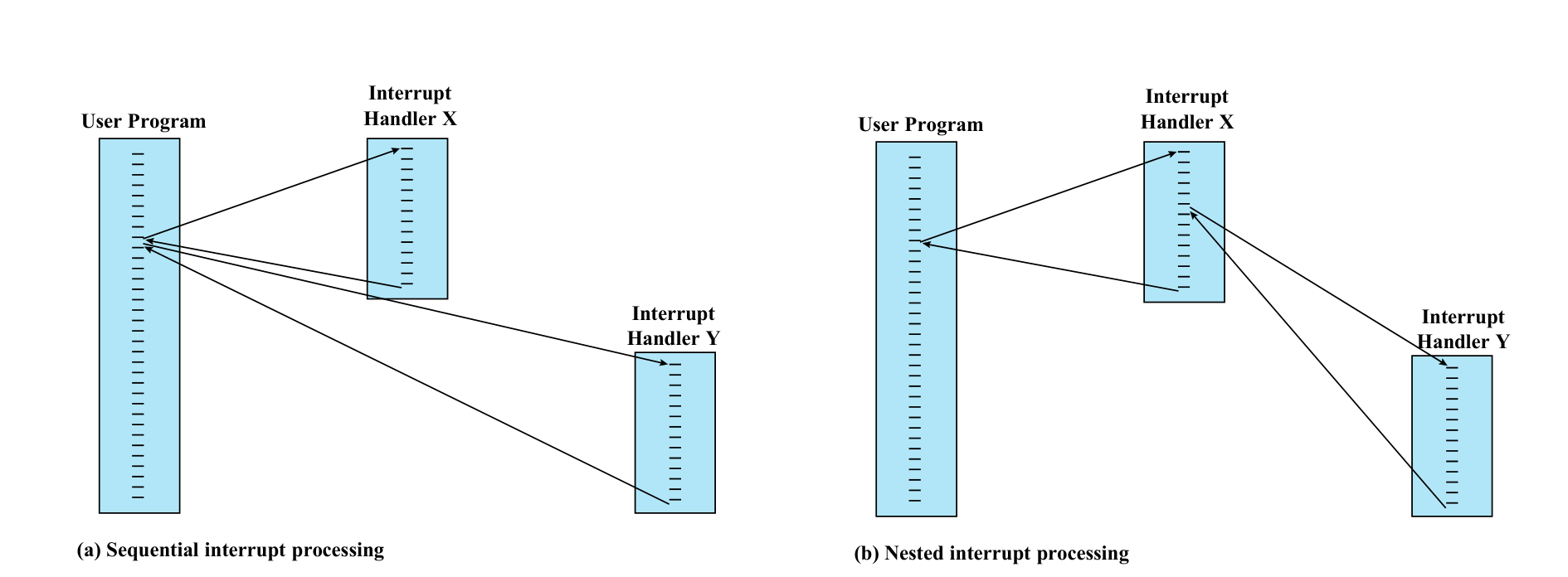
순차적 처리(Sequential Interrupt Processing)
인터럽트 처리 중에는 다른 인터럽트를 비활성화(disable)한다. 새로운 인터럽트 신호가 오면 pending 상태로 대기시키고, 현재 핸들러가 끝난 뒤 처리한다.
- 장점: 구현이 단순하다
- 단점: 우선순위를 고려하지 못한다. 시간에 민감한 인터럽트가 긴급하지 않은 인터럽트 뒤에서 대기할 수 있다
중첩 처리(Nested Interrupt Processing)
인터럽트에 우선순위를 부여하고, 현재 처리 중인 인터럽트보다 더 높은 우선순위의 인터럽트만 허용한다. 현재 상태를 컨트롤 스택에 push하고 우선순위가 높은 핸들러를 먼저 실행한다.
예를 들어 우선순위가 Communication > Disk > Printer 순이라면:
- t=0: 사용자 프로그램 실행 중
- t=10: 프린터 인터럽트 발생 → 프린터 ISR 시작
- t=15: 통신 인터럽트 발생 → 우선순위가 높으므로 프린터 ISR 중단, 통신 ISR 시작
- t=20: 디스크 인터럽트 발생 → 통신보다 우선순위가 낮으므로 pending
- t=25: 통신 ISR 완료 → 디스크 ISR 시작
- t=35: 디스크 ISR 완료 → 프린터 ISR 재개
- t=40: 프린터 ISR 완료 → 사용자 프로그램 재개
시스템 타이머
OS의 거의 모든 기능은 시간 기반(time-driven)이다. 시간 관리를 위해 두 가지 하드웨어 타이머를 사용한다.
PIT(Programmable Interval Timer) — 시스템 타이머
주기적으로 인터럽트를 발생시키는 장치이다. 매 tick마다 인터럽트가 발생하며, 이 주기를 Hz로 표현한다. 대부분의 아키텍처에서 HZ = 100이다(초당 100회).
/* <asm/param.h> */
#define HZ 100 /* internal kernel time frequency */
Jiffies는 부팅 이후 발생한 tick 수를 저장하는 리눅스 커널 전역 변수이다. 타이머 인터럽트가 발생할 때마다 1씩 증가한다. 상대 시간(relative time)을 측정하는 데 사용된다.
/* <linux/jiffies.h> */
extern unsigned long volatile jiffies;
// 부팅 시: jiffies = 0;
// 매 타이머 인터럽트: jiffies++;
경과 시간(초)은 jiffies / HZ로 계산한다. 예를 들어 5초 후의 시점은 jiffies + 5 * HZ이다.
RTC(Real Time Clock) — 하드웨어 클럭
배터리로 구동되는 비휘발성 장치로, OS가 꺼져 있을 때도 실제 시각(wall time)을 유지한다. 메인보드에 장착된 코인 배터리가 전원을 공급한다.
OS 부팅 시 RTC에서 시간을 읽어 struct timespec xtime에 저장한다. hwclock 명령어(/dev/rtc)로 접근할 수 있다. 이것이 절대 시간(absolute time)이다.
타이머 인터럽트 핸들러
타이머 인터럽트 핸들러가 수행하는 작업:
- Jiffies 갱신: tick 수를 증가시킨다
- Wall time 갱신:
xtime을 업데이트한다 - 프로세스 시간 갱신:
- 현재 프로세스의 자원 사용량을 갱신한다
- 타임 슬라이스(time slice) 확인: 할당된 시간을 초과했으면 프로세스 전환(process switch)을 발동한다
- 동적 타이머 실행: 만료된 동적 타이머(예:
sleep 5)가 있으면 해당 콜백을 실행한다