IP Routing — 라우팅 알고리즘, Link State와 Distance Vector, AS와 실제 네트워크
데이터그램이 목적지로 가려면 각 라우터가 “다음에 어느 링크로 내보낼지”를 알아야 한다. 이 forwarding table을 채우는 일이 라우팅(routing)이다. forwarding이 패킷 하나를 테이블 보고 내보내는 data plane의 동작이라면, 라우팅은 그 테이블 자체를 계산하는 control plane의 동작이다. 이 글은 라우팅 알고리즘이 어떻게 동작하는지, 그리고 그것이 실제 인터넷에서 어떻게 조직되는지를 다룬다.
라우팅을 그래프 문제로 추상화한다
라우팅 프로토콜의 목표는 보내는 호스트에서 받는 호스트까지 라우터들을 거치는 좋은(good) 경로를 찾는 것이다. 여기서 경로(path)는 패킷이 통과하는 라우터의 시퀀스고, “좋다”는 것은 비용(cost)이 가장 작거나, 가장 빠르거나, 가장 덜 혼잡한 경로를 뜻한다.
이 문제는 그래프로 깔끔하게 추상화된다. 네트워크를 그래프 $G = (N, E)$로 본다. $N$은 라우터의 집합, $E$는 라우터를 잇는 링크의 집합이다. 각 링크 $(a, b)$에는 비용 $c_{a,b}$가 붙는다. 직접 연결되지 않은 두 노드 사이의 비용은 $c_{a,b} = \infty$로 둔다.
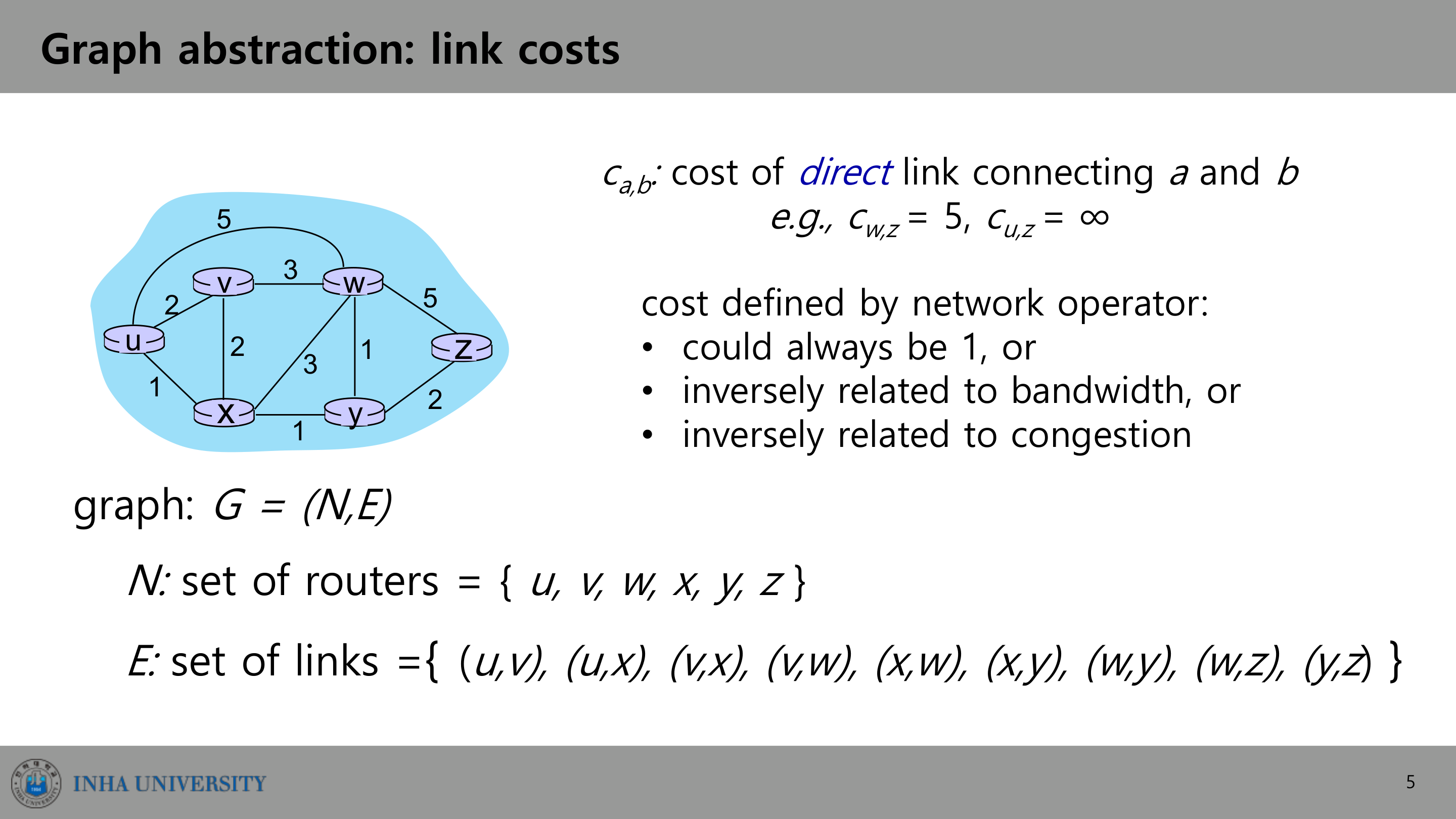
비용은 네트워크 운영자가 정한다. 모든 링크를 1로 두면 경로의 비용은 곧 hop 수가 되고, 대역폭에 반비례하게 두면 빠른 링크를 선호하게 되고, 혼잡도에 반비례하게 두면 덜 막히는 경로를 선호하게 된다. 어떤 정책을 쓰든, 최소 비용 경로를 찾는 문제로 환원된다.
라우팅 알고리즘의 분류
라우팅 알고리즘은 두 축으로 나뉜다.
첫째, 정보를 얼마나 전역적으로 쓰느냐다.
- global(전역) 알고리즘: 모든 라우터가 전체 토폴로지와 모든 링크 비용을 안다. 이 정보로 최소 비용 경로를 직접 계산한다. link-state(LS) 알고리즘이 여기 속한다.
- decentralized(분산) 알고리즘: 각 라우터는 처음에 자기에게 직접 연결된 이웃까지의 비용만 안다. 이웃과 정보를 주고받는 반복(iterative) 과정을 거쳐 점점 경로를 알아간다. distance-vector(DV) 알고리즘이 여기 속한다.
둘째, 경로가 얼마나 빨리 바뀌느냐다.
- static(정적): 경로가 거의 바뀌지 않는다. 사람이 손으로 설정하는 수준.
- dynamic(동적): 링크 비용 변화에 반응하거나 주기적으로 경로를 갱신한다.
실제 인터넷 라우팅 프로토콜은 대부분 dynamic하며, LS 또는 DV 중 하나에 기반한다.
확장성 문제: 왜 평평한 라우팅은 안 되는가
지금까지의 설명은 이상화된 가정 위에 있다. 모든 라우터가 동일하고, 네트워크가 하나의 평평한(flat) 구조라는 가정이다. 현실은 다르다. 두 가지 문제가 발생한다.
규모(scale). 인터넷에는 수십억 개의 목적지가 있다. 이 모두를 라우팅 테이블에 담을 수 없고, 담는다 해도 라우팅 정보를 교환하는 것만으로 링크가 마비된다.
관리 자율성(administrative autonomy). 인터넷은 “네트워크들의 네트워크”다. 각 네트워크 관리자는 자기 네트워크 안의 라우팅을 스스로 통제하고 싶어 한다.
해법은 라우터를 autonomous system(AS, 자율 시스템), 다른 말로 도메인(domain)이라는 영역으로 묶는 것이다. 라우팅을 두 층위로 나눈다.
- intra-AS(intra-domain) 라우팅: 같은 AS 안의 라우터들 사이의 라우팅. 한 AS 안의 모든 라우터는 동일한 intra-domain 프로토콜을 돌려야 한다. 단, AS가 다르면 서로 다른 프로토콜을 써도 된다.
- inter-AS(inter-domain) 라우팅: AS와 AS 사이의 라우팅. 자기 AS의 가장자리(edge)에서 다른 AS의 라우터와 링크를 갖는 gateway router가 이 일을 맡는다.
라우터의 forwarding table은 이 둘이 함께 채운다. 목적지가 같은 AS 안이면 intra-AS 라우팅이 결정하고, 외부 목적지면 inter-AS와 intra-AS가 함께 결정한다. AS1의 라우터가 외부로 나가는 패킷을 받으면 “어느 gateway로 보낼지” 정해야 하는데, 이를 위해 inter-domain 라우팅은 (1) 어떤 목적지가 어느 이웃 AS를 통해 도달 가능한지 학습하고, (2) 그 도달성 정보를 AS 내 모든 라우터에 전파한다.
가장 흔한 프로토콜은 다음과 같다.
| 구분 | 프로토콜 | 기반 | 비고 |
|---|---|---|---|
| intra-AS | RIP | distance vector | 30초마다 DV 교환, 현재는 거의 안 씀 |
| intra-AS | EIGRP | distance vector | 오래 Cisco 독점이었다가 2013년 공개 |
| intra-AS | OSPF | link state | IS-IS도 사실상 OSPF와 동일 |
| inter-AS | BGP | path vector | 인터넷을 묶는 사실상의 표준 |
BGP(Border Gateway Protocol)는 “인터넷을 하나로 붙들고 있는 접착제”라고 불린다. 서브넷이 “나는 여기 있고, 이런 목적지에 도달할 수 있으며, 경로는 이렇다”를 인터넷 전체에 광고하게 해준다. 이웃 AS로부터 도달성 정보를 받고(eBGP), 정책(policy)에 따라 경로를 정하고, 그 정보를 AS 내부 라우터로 전파하고(iBGP), 이웃 네트워크에 광고한다.
intra와 inter를 굳이 다른 프로토콜로 나누는 이유는 정책, 규모, 성능의 우선순위가 다르기 때문이다. inter-AS는 관리자가 트래픽 경로를 통제하려는 정책이 성능보다 우선한다. intra-AS는 관리자가 하나뿐이라 정책 문제가 작고, 성능에 집중할 수 있다. 계층화 자체는 테이블 크기와 갱신 트래픽을 줄여 규모 문제를 해결한다.
Link-State 라우팅: Dijkstra 알고리즘
link-state 라우팅의 전제는 각 라우터가 전체 토폴로지를 안다는 것이다. 각 라우터는 자기에게 직접 연결된 링크의 상태(link state)를 관찰할 수 있고, 이를 link-state broadcast로 다른 모든 라우터에 뿌린다. 그 결과 모든 라우터가 동일한 전체 지도를 갖게 된다.
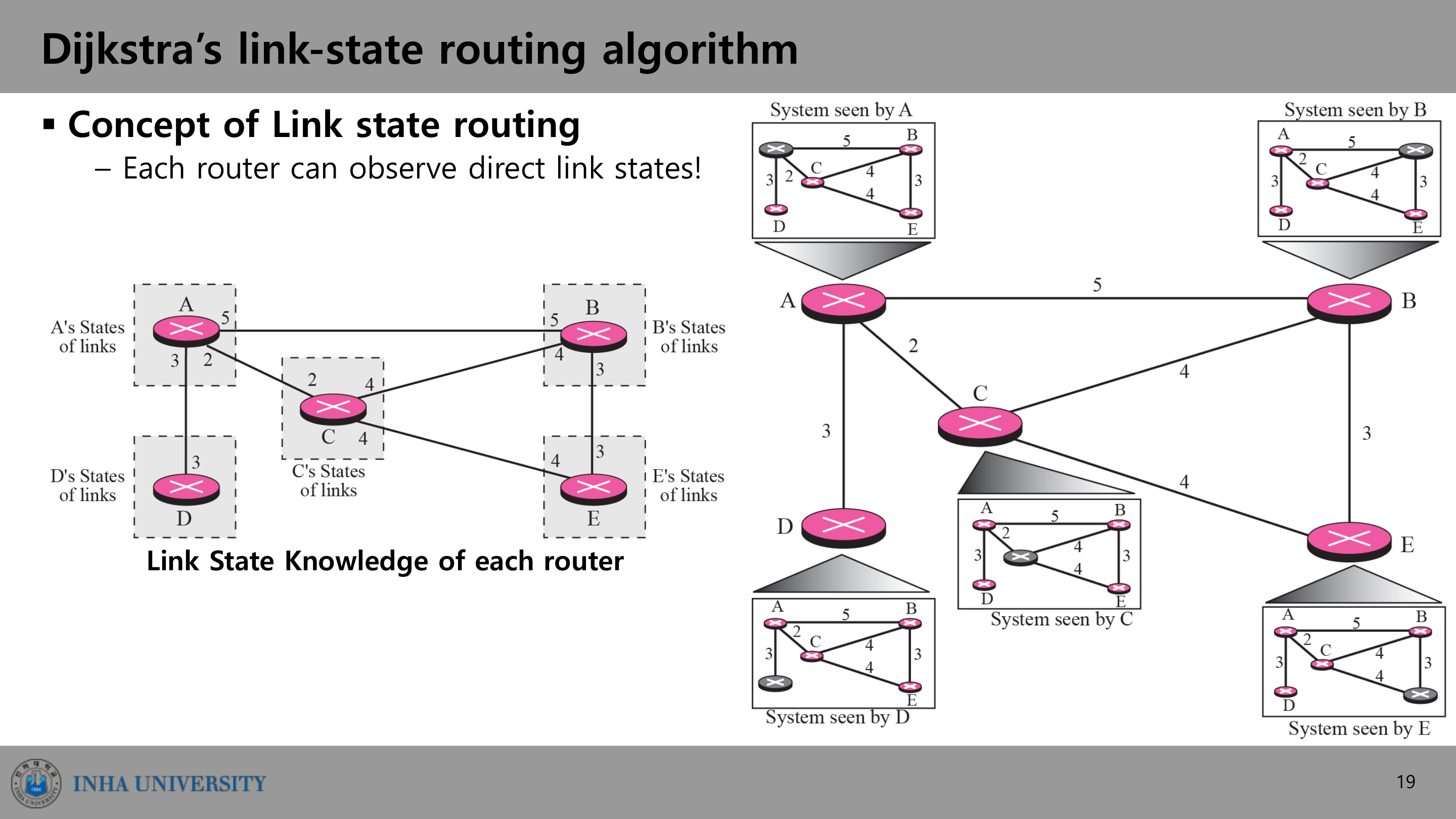
전체 지도를 가진 라우터는 자기를 출발점으로 모든 목적지까지의 최소 비용 경로를 중앙집중적으로(centralized) 계산한다. 이 계산이 곧 Dijkstra 알고리즘이다. 표기는 다음과 같다.
- $c_{x,y}$: 노드 $x$에서 $y$로의 직접 링크 비용. 직접 이웃이 아니면 $\infty$.
- $D(v)$: 출발지에서 목적지 $v$까지 현재 추정된 최소 비용.
- $p(v)$: 출발지에서 $v$로 가는 경로 상에서 $v$의 직전(predecessor) 노드.
- $N’$: 최소 비용 경로가 확정된 노드의 집합.
알고리즘은 출발지 $u$만 $N’$에 넣고 시작해, 매 반복마다 아직 확정 안 된 노드 중 $D$가 가장 작은 노드를 골라 $N’$에 넣고, 그 노드를 거치는 경로로 이웃들의 비용을 갱신한다.
Initialization:
N' = {u}
for all nodes v:
if v adjacent to u: D(v) = c(u,v)
else: D(v) = ∞
Loop:
N'에 없는 노드 w 중 D(w)가 최소인 것을 찾는다
w를 N'에 추가
w에 인접하고 N'에 없는 모든 v에 대해:
D(v) = min( D(v), D(w) + c(w,v) )
until 모든 노드가 N'에 들어갈 때까지
핵심은 갱신식 $D(v) = \min(D(v),\ D(w) + c_{w,v})$다. $v$까지의 새 최소 비용은 “기존에 알던 비용”과 “방금 확정된 $w$까지의 비용 + $w$에서 $v$로 가는 직접 비용” 중 작은 쪽이다.
예제로 따라가기
앞의 그래프(출발지 $u$)에 적용해보자. 링크 비용은 $c_{u,v}=2$, $c_{u,w}=5$, $c_{u,x}=1$, $c_{v,w}=3$, $c_{v,x}=2$, $c_{x,w}=3$, $c_{x,y}=1$, $c_{w,y}=1$, $c_{w,z}=5$, $c_{y,z}=2$다.
| Step | N’ | D(v),p(v) | D(w),p(w) | D(x),p(x) | D(y),p(y) | D(z),p(z) |
|---|---|---|---|---|---|---|
| 0 | u | 2,u | 5,u | 1,u | ∞ | ∞ |
| 1 | ux | 2,u | 4,x | 2,x | ∞ | |
| 2 | uxy | 2,u | 3,y | 4,y | ||
| 3 | uxyv | 3,y | 4,y | |||
| 4 | uxyvw | 4,y | ||||
| 5 | uxyvwz |
각 단계에서 굵게 표시된 값이 그 라운드에 $N’$로 확정되는 노드다. 매번 확정 직후 이웃들의 $D$를 갱신한다. 예를 들어 Step 1에서 $x$가 확정되면 $D(w) = \min(5,\ 1+3) = 4$, $D(y) = \min(\infty,\ 1+1) = 2$로 줄어든다.
계산이 끝나면 $p(\cdot)$를 거꾸로 추적해 최소 비용 경로 트리를 만들고, 거기서 $u$의 forwarding table을 뽑는다. $u$ 입장에서 $v$는 직접 링크 $(u,v)$로, 나머지 $w, x, y, z$는 전부 첫 hop이 $x$이므로 $(u,x)$ 링크로 내보낸다.
복잡도와 진동(oscillation)
노드가 $n$개일 때, 각 반복에서 $N’$에 없는 모든 노드를 확인해야 하므로 비교 횟수는 $n(n+1)/2$, 즉 $O(n^2)$이다. 우선순위 큐를 쓰면 $O(n \log n)$까지 줄일 수 있다. 메시지 복잡도는 각 라우터가 link state를 다른 $n$개 라우터에 broadcast해야 하므로 전체 $O(n^2)$이다.
link-state에는 미묘한 함정이 있다. 링크 비용이 트래픽 양에 의존하면 경로가 진동(oscillation)할 수 있다. 모두가 덜 혼잡한 경로로 몰리면 그 경로가 혼잡해지고, 그러면 다시 다른 경로로 몰리고, 이게 반복된다. 비용을 트래픽과 무관하게 두거나, 모든 라우터가 동시에 계산하지 않도록 조정해 완화한다.
Distance-Vector 라우팅: Bellman-Ford
distance-vector는 전혀 다른 접근이다. 각 라우터는 전체 지도를 모른 채, 이웃과 “거리 벡터”를 주고받으며 점진적으로 경로를 알아간다. 이론적 토대는 Bellman-Ford(BF) 방정식이다.
$D_x(y)$를 $x$에서 $y$까지의 최소 비용이라 하면,
\[D_x(y) = \min_{v} \{\, c_{x,v} + D_v(y) \,\}\]이다. $\min$은 $x$의 모든 이웃 $v$에 대해 취한다. $c_{x,v}$는 $x$에서 이웃 $v$로의 직접 비용이고, $D_v(y)$는 그 이웃 $v$가 추정한 $y$까지의 최소 비용이다. 즉 “$y$로 가는 최선은, 이웃 하나를 거쳐 가는 경우들 중 가장 싼 것”이라는 동적 계획법(dynamic programming)의 점화식이다.
예를 들어 $u$의 이웃 $v, x, w$가 목적지 $z$까지의 비용을 각각 $D_v(z)=5$, $D_x(z)=3$, $D_w(z)=3$으로 알려줬다고 하자. 그러면
\[D_u(z) = \min\{\, c_{u,v}+D_v(z),\ c_{u,x}+D_x(z),\ c_{u,w}+D_w(z) \,\} = \min\{2+5,\ 1+3,\ 5+3\} = 4\]이고, 최소를 만든 이웃 $x$가 $z$로 가는 경로의 next hop이 된다.
동작 방식
핵심 아이디어는 단순하다.
- 각 노드는 때때로 자기 distance vector(목적지별 최소 비용 추정의 묶음)를 이웃에게 보낸다.
- 노드 $x$가 어떤 이웃으로부터 새 DV를 받으면, BF 방정식으로 자기 DV를 갱신한다.
약한 자연스러운 조건 아래에서, 이 추정값 $D_x(y)$는 실제 최소 비용 $d_x(y)$로 수렴한다. 이 과정은 비동기적이고 자기 종료적(self-terminating)이다. 갱신할 게 없으면 멈춘다.
정보는 반복적인 통신·계산을 통해 네트워크에 확산(diffuse)된다. $t=0$에 노드 $c$만 알던 상태가, $t=1$에는 1 hop 떨어진 이웃까지, $t=2$에는 2 hop까지 영향을 미친다. 즉 $t$번 반복 후 정보는 $t$ hop까지 퍼진다.
Link cost가 변할 때: good news vs bad news
DV의 진짜 흥미로운(그리고 골치 아픈) 부분은 링크 비용이 변할 때다. 노드는 로컬 링크 비용 변화를 감지하면 라우팅 정보를 갱신하고 DV를 다시 계산하며, DV가 바뀌면 이웃에게 알린다.

“good news travels fast” — 비용이 줄어드는 경우. 위 그림에서 $y$-$x$ 링크 비용이 4에서 1로 줄었다고 하자.
- $t_0$: $y$가 변화를 감지하고 DV를 갱신, 이웃에게 알린다.
- $t_1$: $z$가 $y$의 갱신을 받아 $x$까지의 새 최소 비용을 계산하고, 자기 이웃에게 알린다.
- $t_2$: $y$가 $z$의 갱신을 받지만 $y$의 최소 비용은 바뀌지 않으므로 더 이상 알리지 않는다. 빠르게 안정된다.
“bad news travels slow” — 비용이 늘어나는 경우. 이번엔 $y$-$x$ 비용이 4에서 60으로 뛰었다고 하자. 여기서 count-to-infinity 문제가 발생한다.
- $y$는 $x$로의 직접 비용이 60이 됐지만, $z$가 “나는 $x$까지 비용 5인 경로가 있다”고 했던 걸 기억한다. 그래서 $y$는 “$z$를 거치면 6”이라 계산하고 $z$에게 알린다.
- $z$는 “$y$를 거치는 경로가 6이 됐네”라며 “그럼 나는 7”이라 계산하고 $y$에게 알린다.
- $y$는 다시 8, $z$는 9… 이렇게 둘이 서로의 옛 정보를 보고 1씩 올려가며, 실제 정답(50)에 도달할 때까지 핑퐁한다.
문제의 본질은 $y$와 $z$가 서로의 경로가 자기를 거쳐 간다는 사실을 모른 채 상대의 광고를 믿는 데 있다. 분산 알고리즘이 까다로운 이유를 잘 보여주는 사례다.
Link State vs Distance Vector
두 알고리즘을 정리하면 이렇다.
| 기준 | Link State | Distance Vector |
|---|---|---|
| 메시지 복잡도 | $n$ 라우터, $O(n^2)$ 메시지 | 이웃끼리만 교환, 수렴 시간 가변 |
| 수렴 속도 | $O(n^2)$ 알고리즘, 진동 가능 | 가변, 라우팅 루프·count-to-infinity 가능 |
| 견고성(robustness) | 잘못된 링크 비용을 광고할 수 있으나, 각 라우터가 자기 테이블만 계산 | 잘못된 경로 비용을 광고하면(“어디든 싸게 간다”) black-holing 발생, 오류가 네트워크 전체로 전파 |
robustness가 중요한 차이다. LS에서는 고장난 라우터가 자기 링크 비용을 틀리게 말해도 영향이 국소적이다. 반면 DV에서는 한 라우터의 DV를 다른 라우터들이 그대로 받아 쓰므로, 한 곳의 오류가 연쇄적으로 퍼진다.
실제 네트워크는 어떻게 생겼나
이론을 봤으니 실제 네트워크가 이 조각들을 어떻게 조립하는지 보자.
캠퍼스 네트워크
UMass 캠퍼스 네트워크는 방화벽 4개, 라우터 10개, 스위치 2000개 이상, 무선 AP 6000개, 유선 잭 3만 개, 동시 접속 무선 기기 5만 5천 개 규모를 약 15명이 운영한다. 구조는 명확한 계층을 이룬다.
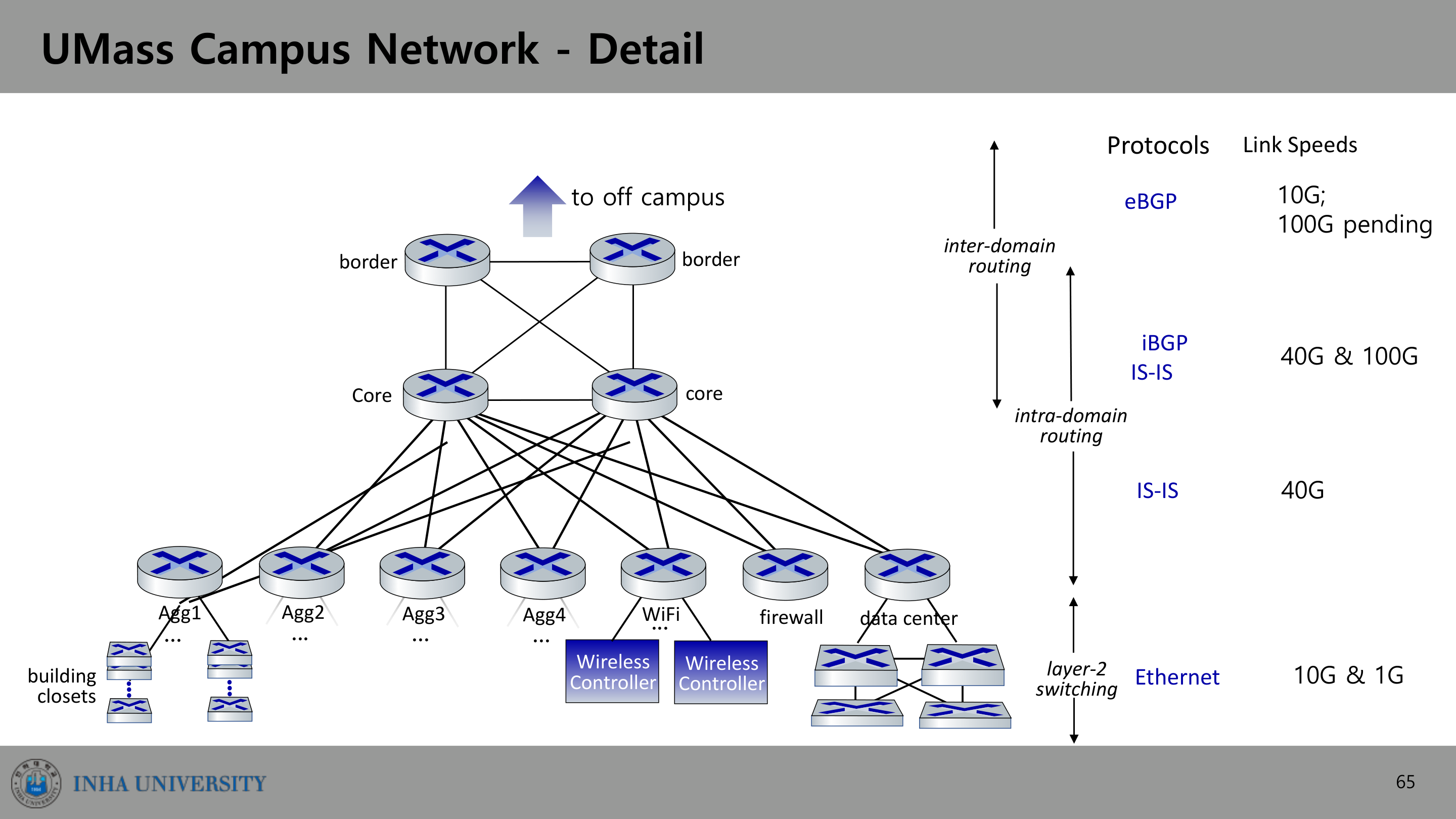
위 그림에서 계층별로 쓰이는 기술이 다르다는 점이 핵심이다.
- 외부로 나가는 border router는 eBGP로 inter-domain 라우팅을 한다(10G, 100G 준비 중).
- core 계층은 iBGP와 IS-IS로 intra-domain 라우팅을 한다(40G, 100G).
- aggregation 계층은 IS-IS(40G).
- 맨 아래 building closet과 데이터센터 쪽은 Ethernet의 layer-2 스위칭(10G, 1G).
여기서 스위치와 라우터의 구분이 다시 등장한다. 둘 다 store-and-forward 장비고 둘 다 forwarding table을 갖지만, 라우터는 네트워크 계층 장비로 IP 주소와 라우팅 알고리즘으로 테이블을 계산하고, 스위치는 링크 계층 장비로 MAC 주소를 flooding·learning해 테이블을 채운다.
데이터센터 네트워크
데이터센터는 수만에서 수십만 대의 호스트가 가까이 모인 환경이다. e-business(Amazon), 콘텐츠 서버(YouTube, Akamai), 검색·데이터마이닝(Google) 등이 돌아간다. 도전 과제는 막대한 클라이언트를 감당하는 다중 애플리케이션, 신뢰성, 그리고 부하 분산과 병목 회피다.
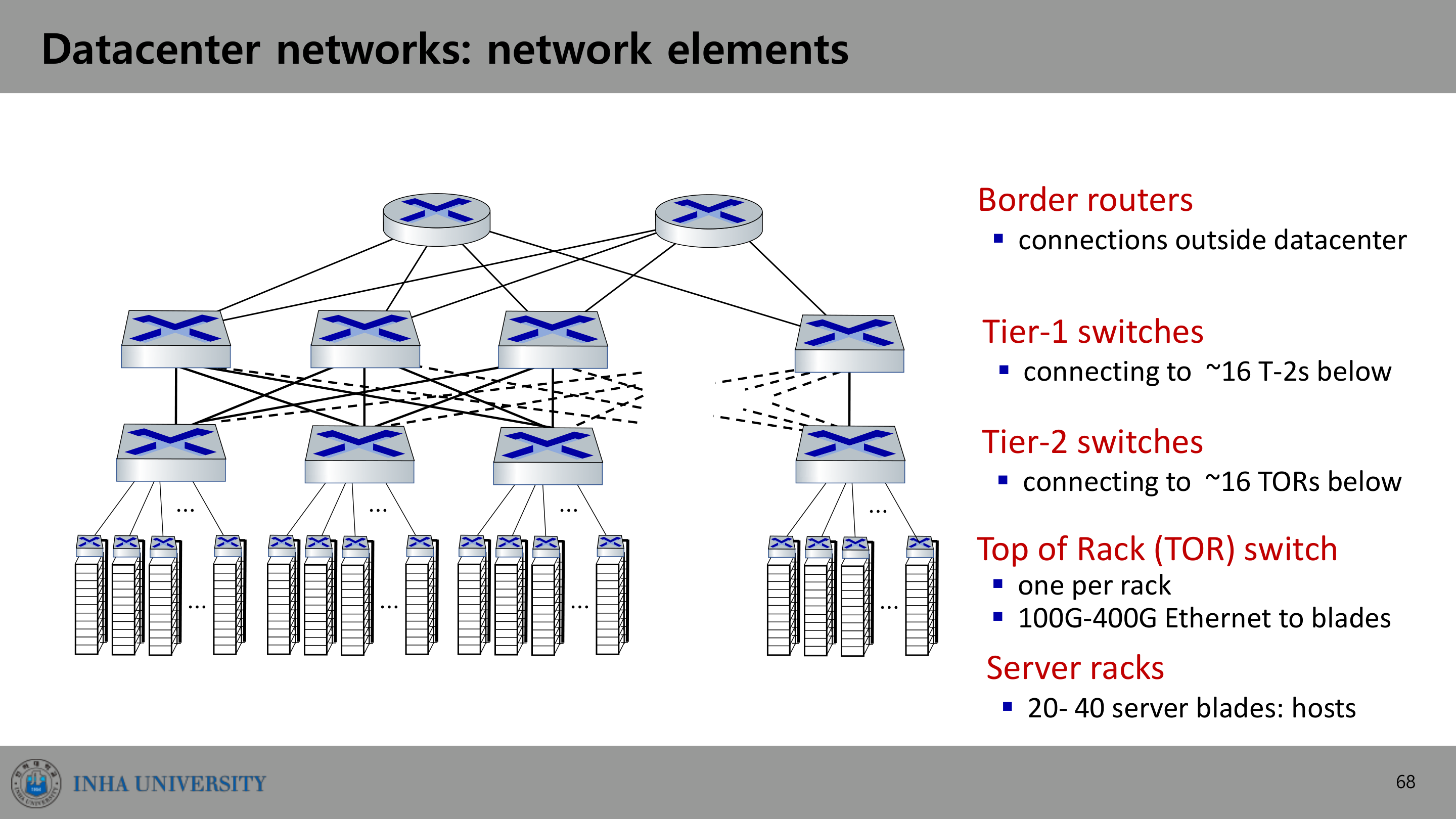
구조는 계층적이다. 맨 위 border router가 데이터센터 외부와 연결되고, 그 아래 tier-1 스위치 각각이 약 16개의 tier-2 스위치에 연결되며, tier-2 스위치는 각각 약 16개의 TOR(Top of Rack) 스위치에 연결된다. TOR은 랙마다 하나씩 놓여 100G~400G Ethernet으로 서버 블레이드와 이어진다. 랙 하나에는 20~40개의 서버 블레이드(호스트)가 들어간다.
이 구조의 두 가지 설계 포인트가 있다.
- multipath: 스위치·랙 사이를 촘촘히 연결해 랙 간 처리량을 높이고(여러 라우팅 경로 가능), 중복(redundancy)으로 신뢰성을 높인다. 두 랙 사이에 서로 겹치지 않는(disjoint) 경로가 여러 개 존재한다.
- application-layer routing: load balancer가 외부 클라이언트 요청을 받아 데이터센터 내부로 작업을 분배하고, 결과를 클라이언트에 돌려준다. 클라이언트에게는 내부 구조가 숨겨진다.
데이터센터는 프로토콜 혁신의 무대이기도 하다. 링크 계층에서는 RoCE(RDMA over Converged Ethernet), 전송 계층에서는 ECN 기반 혼잡 제어(DCTCP, DCQCN)와 hop-by-hop backpressure 실험, 라우팅·관리에서는 SDN이 널리 쓰인다.
프로토콜은 죽어가는가
마지막으로 Google의 control plane인 ORION은 흥미로운 질문을 던진다. ORION은 내부 데이터센터(Jupiter)와 광역망(B4)을 위한 SDN control plane으로, 라우팅(intra-domain, iBGP)과 traffic engineering을 ORION 코어 위의 애플리케이션으로 구현한다. edge-edge flow 기반 제어(CoFlow 스케줄링 등)로 계약 SLA를 맞추고, 관리는 Orion 코어의 pub-sub 마이크로서비스로, 스위치 신호·모니터링은 OpenFlow로 한다.
주목할 점은 라우팅 프로토콜이 없다는 것이다. 전통적으로 라우터들이 분산 프로토콜로 자율적으로 합의하던 일을, SDN 컨트롤러가 중앙에서 계산해 내려보낸다. 혼잡 제어조차 부분적으로 프로토콜이 아니라 SDN이 관리한다. “프로토콜은 죽어가는가?”라는 도발적 질문이 자연스럽게 따라온다. link-state와 distance-vector가 라우터의 자율적 합의로 경로를 찾는 고전적 모델이었다면, SDN은 그 통제권을 중앙으로 되돌린 셈이다.