Computer System Overview II — Memory Hierarchy & Cache
컴퓨터 메모리 계층 구조와 캐시 메모리의 동작 원리를 정리합니다.
메모리 설계 제약조건
메모리 설계 시 고려해야 할 세 가지: 용량(Capacity), 접근 시간(Access Time), 비용(Cost per bit)
하나의 메모리 기술에 의존하지 않고, 여러 메모리를 계층적으로 조합하여 사용합니다.
메모리 계층 구조 (Memory Hierarchy)
작고 빠르고 비싼 메모리를 크고 느리고 싼 메모리로 보완하는 구조입니다.
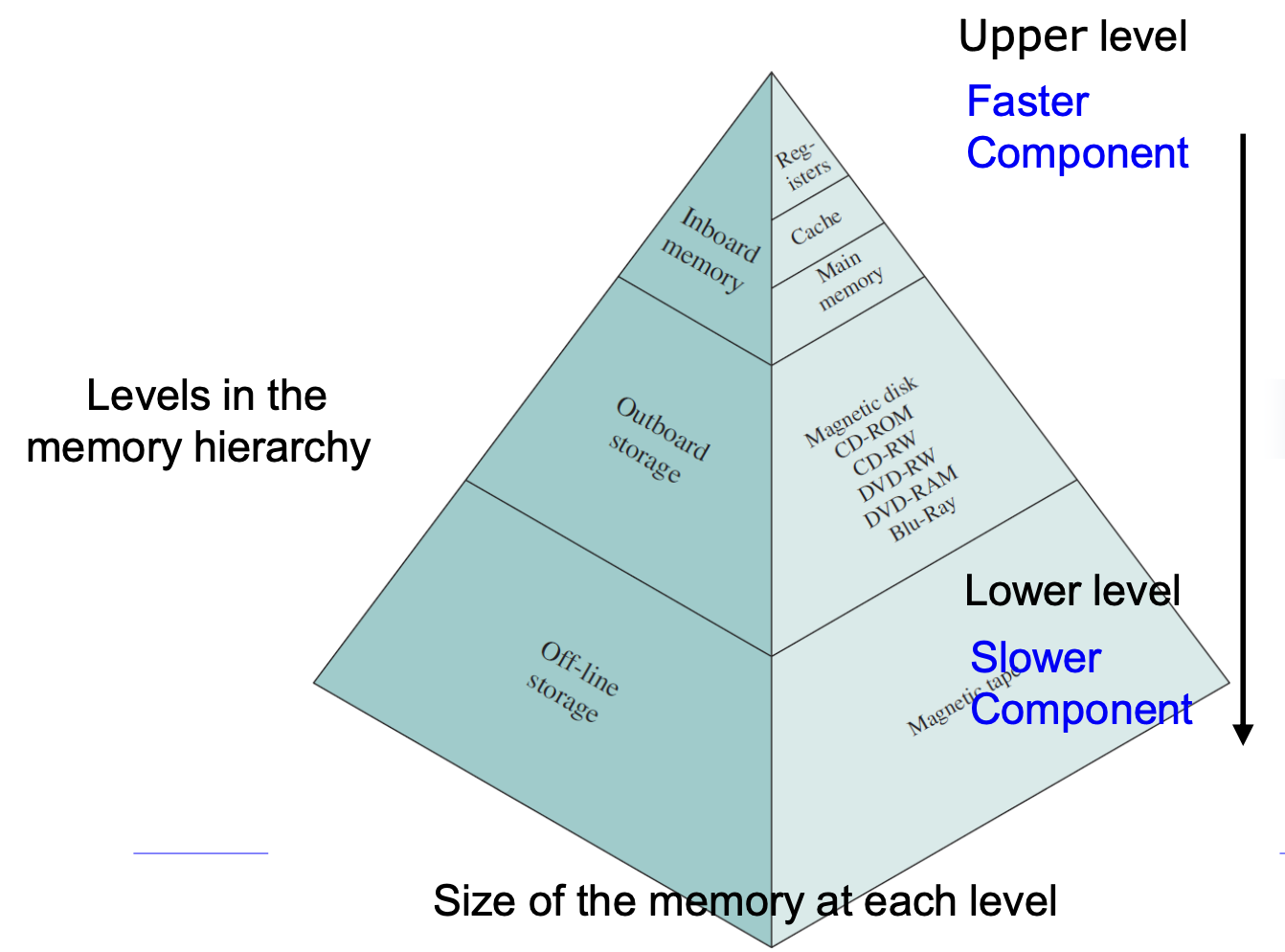
Register → Cache(SRAM) → Main Memory(DRAM) → Disk
- Cache: <10ns, MB급
- Main Memory: <100ns, GB급
- Disk: <10^7ns, TB급
핵심 전략: 하위 계층 메모리 접근을 최소화하는 것
참조의 지역성 (Locality of Reference)
- 시간적 지역성(Temporal): 한 번 접근한 데이터는 곧 다시 접근될 가능성이 높음 (예: 반복문의 변수)
- 공간적 지역성(Spatial): 한 주소를 접근하면 인접한 주소도 곧 접근될 가능성이 높음 (예: 배열)
평균 접근 시간
T = H × T1 + (1-H) × (T1 + T2)
- H: 히트율, T1: 상위 계층 접근 시간, T2: 하위 계층 접근 시간
- 예: T1=1cycle, T2=100cycles일 때, 97% 히트 → 4cycles, 99% 히트 → 2cycles
- 히트율 2% 차이지만 성능은 2배 차이
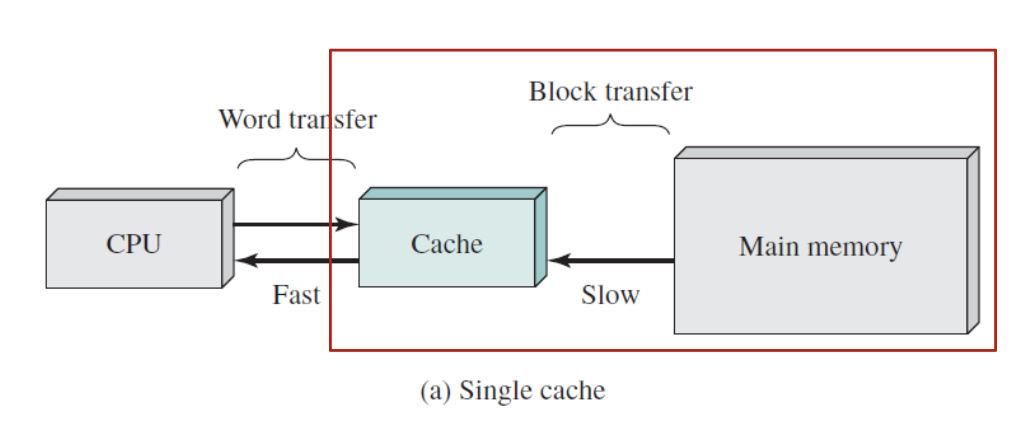
캐시 메모리
캐시는 CPU 내부에 위치하며, 프로세서와 메모리 속도 차이를 해결합니다.
- CPU ↔ Cache: 워드(Word) 단위 전송
- Cache ↔ Main Memory: 블록(Block) 단위 전송
블록 단위 전송은 공간적 지역성을 활용하여 인접 데이터도 함께 캐싱합니다.
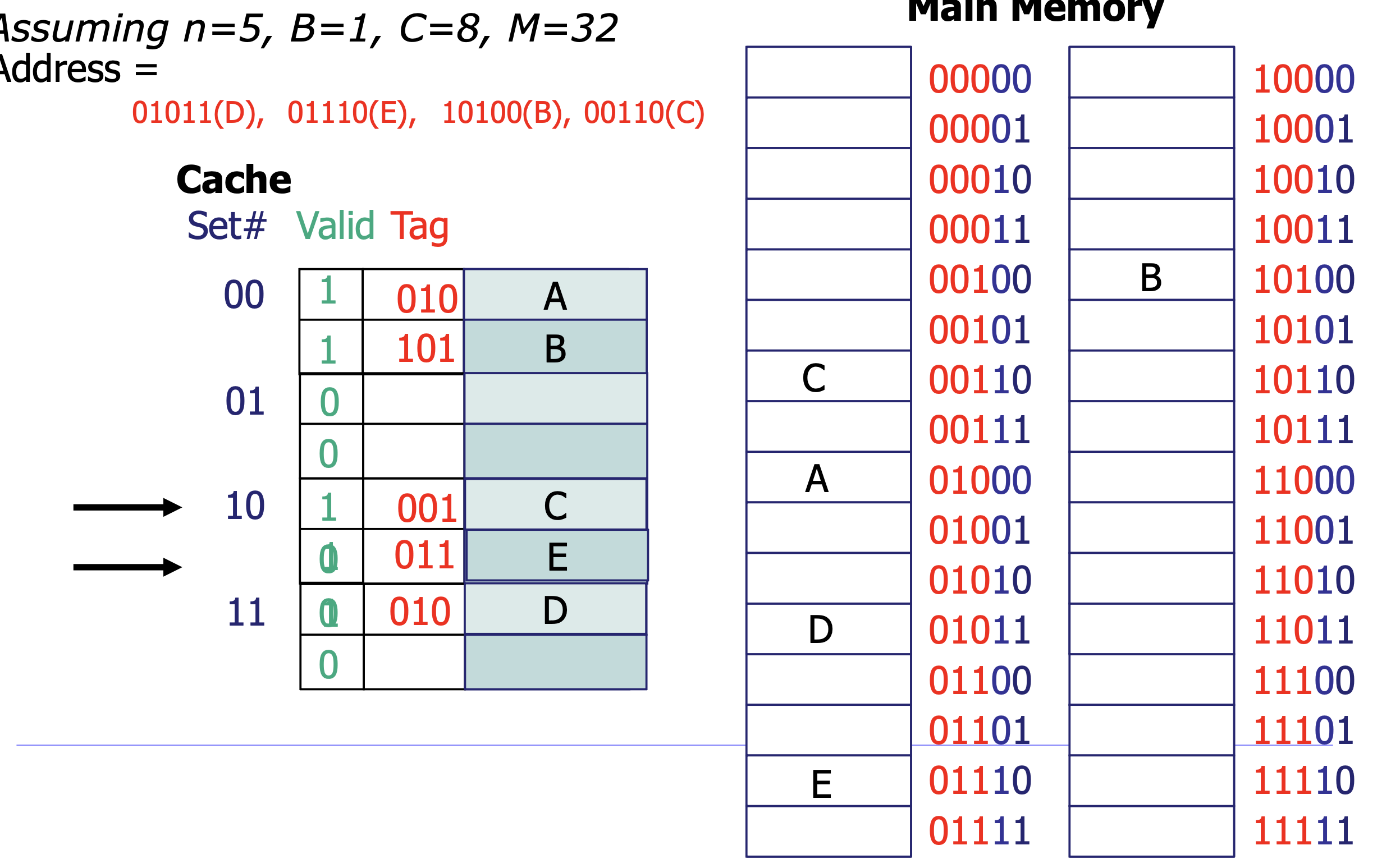
캐시 구조
주소 구조: [Tag | Set index | Block offset]
- Tag: 어떤 블록인지 식별
- Set index: 어떤 세트에 매핑되는지
- Block offset: 블록 내에서 몇 번째 바이트인지
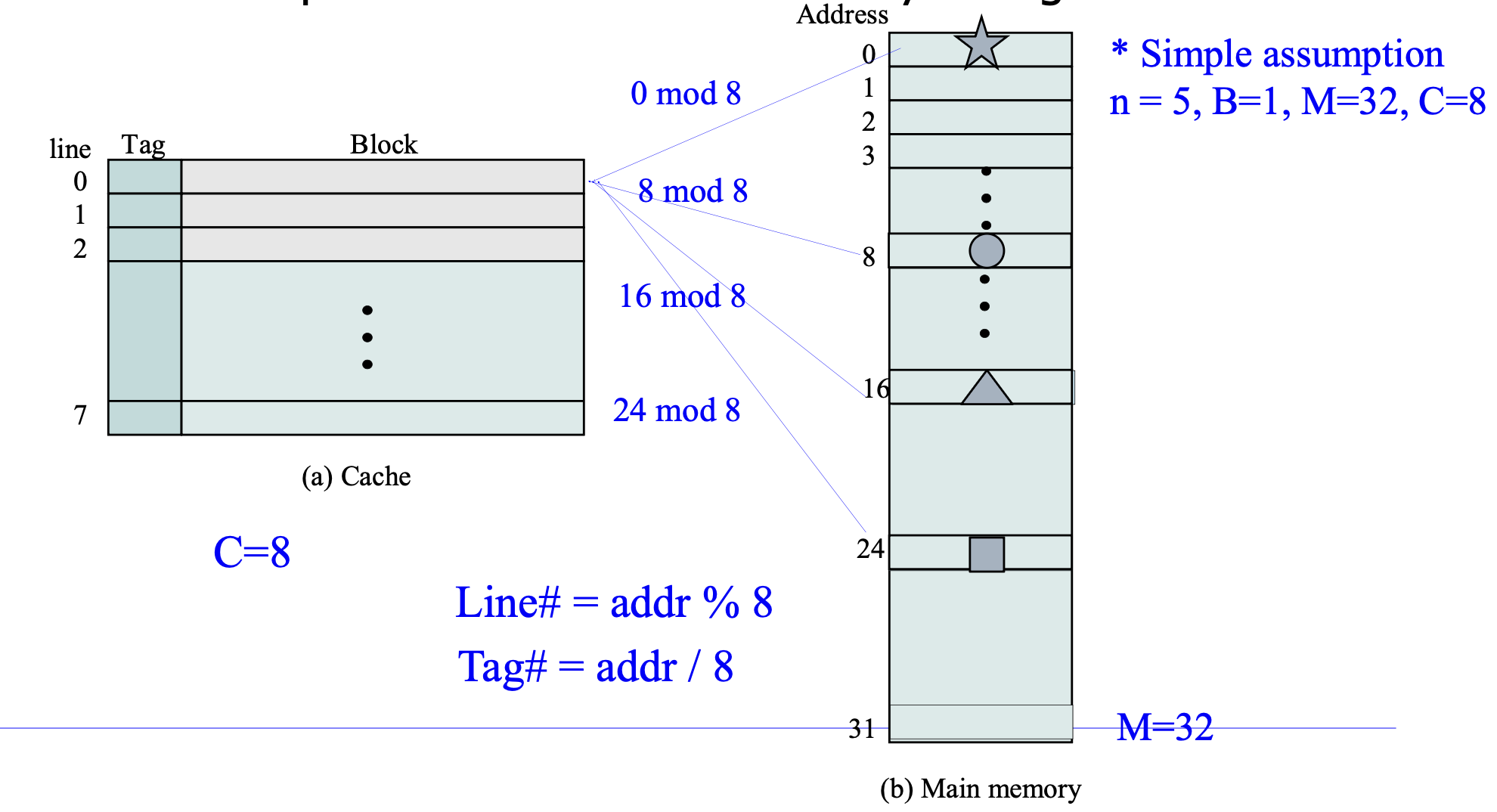
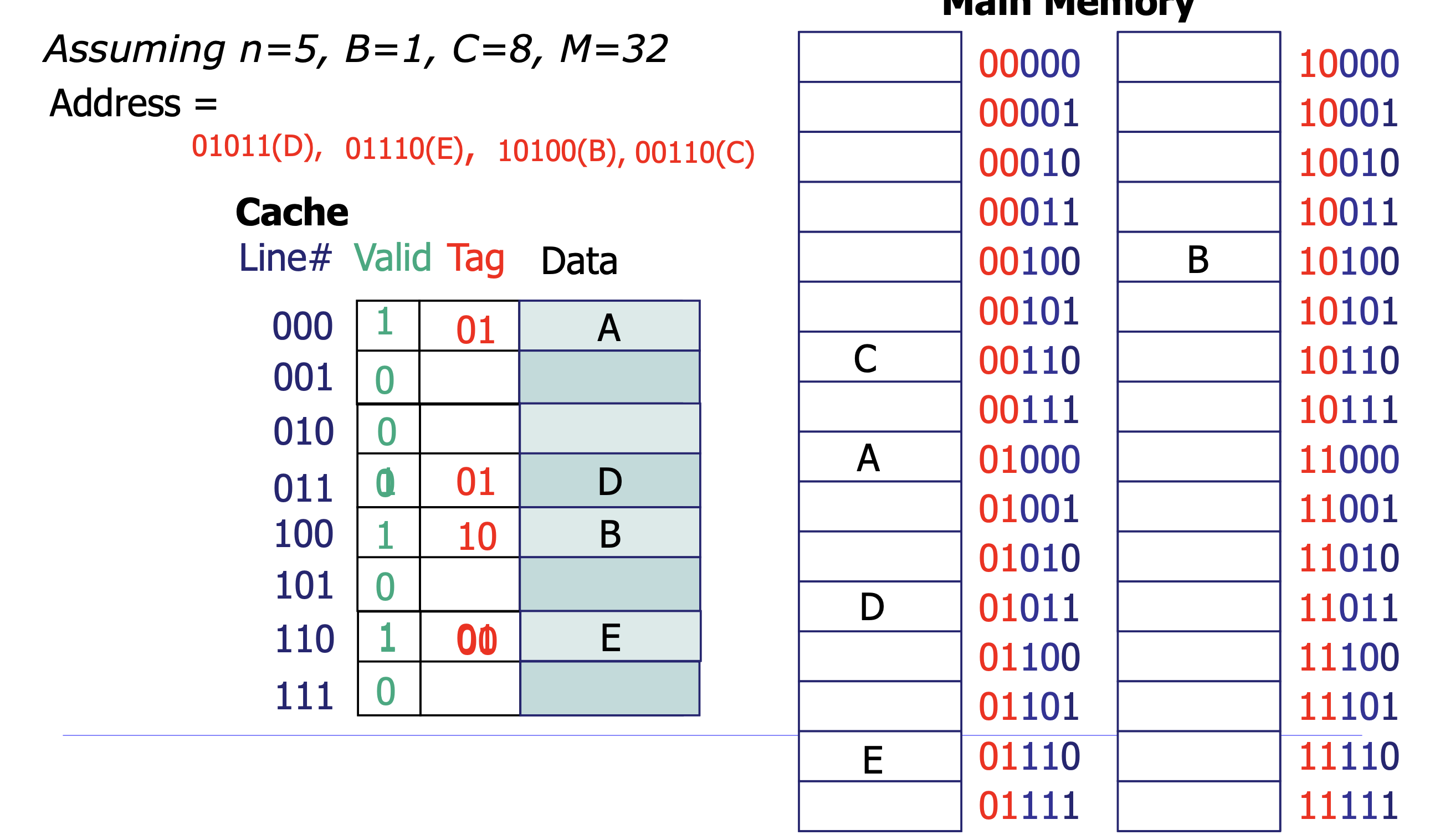
캐시 매핑 (Cache Mapping)
- Direct Mapped: 각 블록이 캐시의 한 곳에만 매핑. 간단하지만 충돌 미스 발생
- Set-Associative: 세트 안에 E개 라인. 충돌 완화. LRU로 교체 대상 선택
- 캐시 크기:
C = S(세트 수) × E(세트당 라인 수) × B(블록 크기)
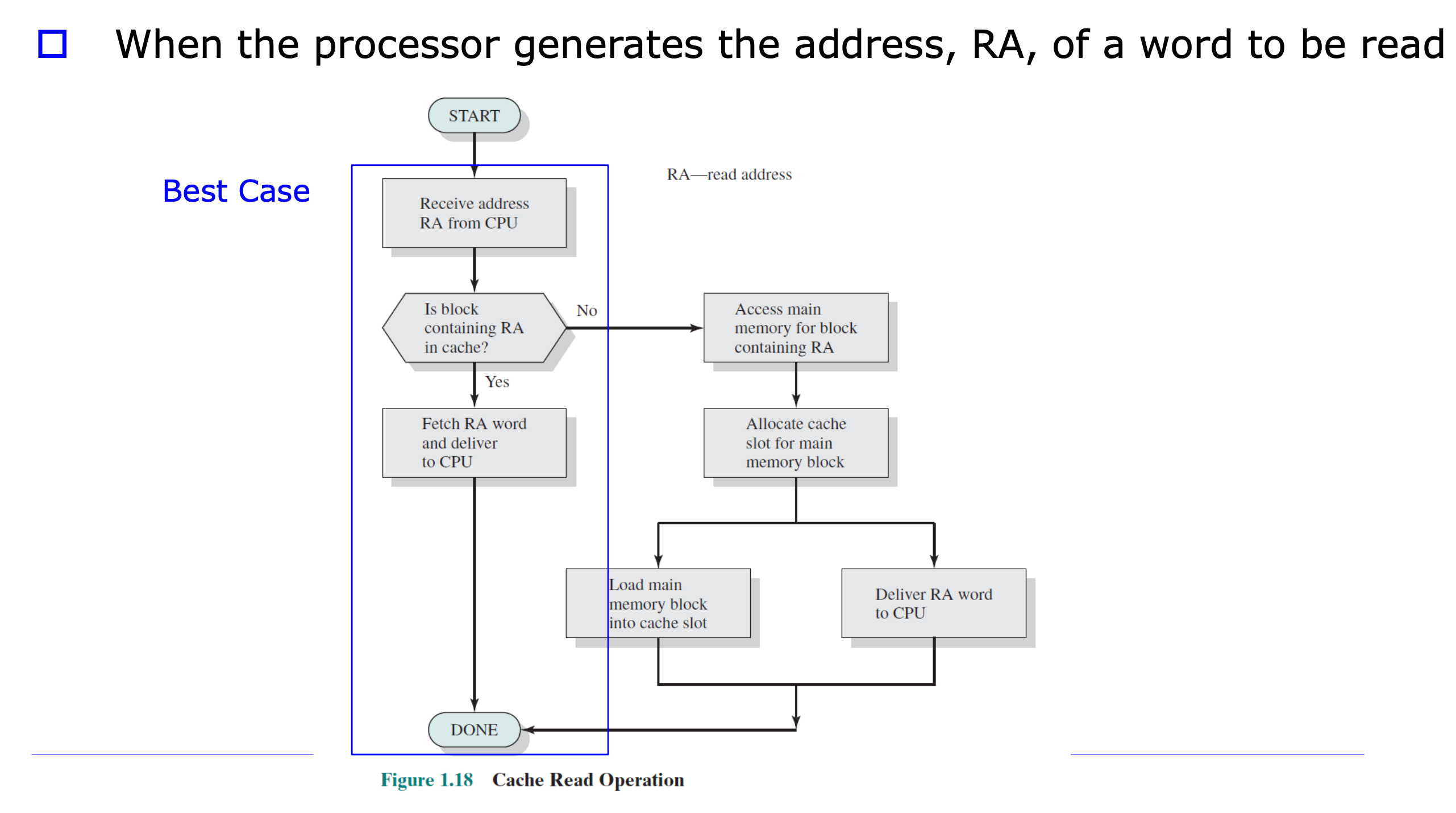
쓰기 정책
| 정책 | 동작 | 특징 |
|---|---|---|
| Write-through | 캐시 수정 시 메모리에도 바로 write | 메모리 항상 최신, 느림 |
| Write-back | 캐시만 수정, 교체 시 메모리에 write | dirty bit 필요, 빠름 |
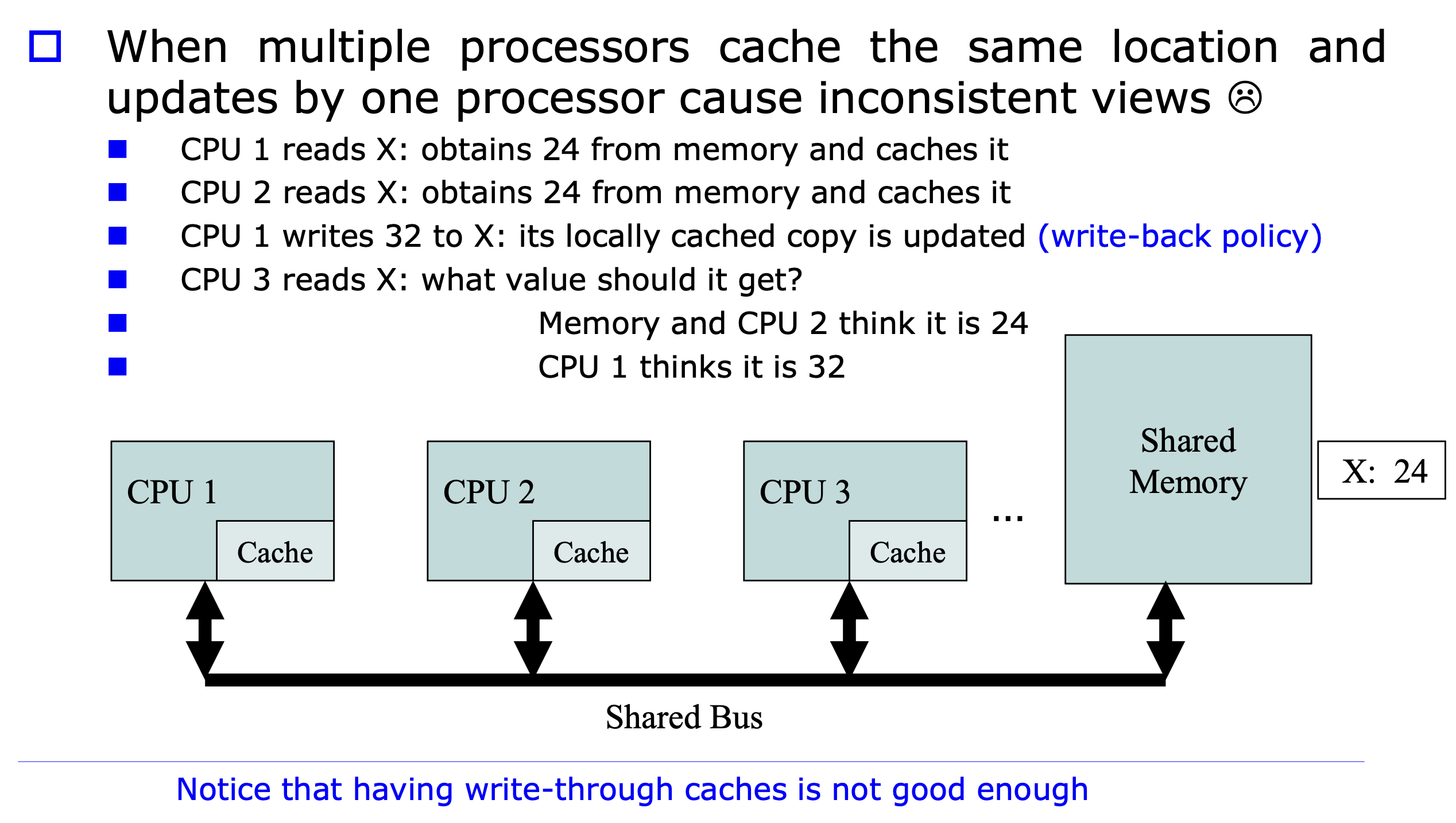
캐시 일관성 문제 (Cache Coherence)
멀티프로세서에서 여러 CPU가 같은 주소를 캐싱했을 때, 한 CPU가 수정하면 다른 CPU 캐시와 불일치가 발생합니다.
스누핑 프로토콜(Snooping Protocol): 각 CPU의 캐시 컨트롤러가 공유 버스를 감시하여 무효화(Invalidate)합니다.
거짓 공유 (False Sharing)
서로 다른 변수가 같은 캐시 라인에 있으면 불필요한 일관성 트래픽이 발생합니다.
해결: 캐시 라인 패딩 — 변수 사이에 빈 공간을 넣어 서로 다른 캐시 라인에 배치