Analyzing Algorithms and Problems — 알고리즘 분석의 원리
같은 문제를 푸는 알고리즘이 여러 개라면, 어떤 기준으로 고를 것인가. “빠르다”는 감이 아니라 수학적으로 정량화할 수 있어야 한다. 알고리즘 분석은 그 도구를 제공한다.
알고리즘이란
알고리즘(Algorithm)은 컴퓨터를 사용하여 문제를 해결하기 위한 단계별 방법(step-by-step method)이다.
컴퓨터로 문제를 해결하는 과정은 다음 단계를 따른다:
- Problem: 문제를 정의한다
- Strategy: 해결 전략을 선택한다
- Algorithm: 입력(Input), 출력(Output), 단계(Step)를 명세한다
- Analysis: 정확성(Correctness), 시간/공간 복잡도(Time & Space), 최적성(Optimality)을 분석한다
- Implementation: 구현한다
- Verification: 검증한다
알고리즘의 명세에는 C++ 유사 문법의 의사 코드(pseudo-code)를 사용한다. 세부 구현이 아닌 전략과 기법에 집중하기 위함이다.
예제: 비정렬 배열 탐색
가장 단순한 탐색 문제로 시작한다.
문제: 크기 n인 배열 E[0], …, E[n-1]에서 키 K의 인덱스를 찾는다. 없으면 -1을 반환한다.
전략: K를 배열의 각 원소와 차례로 비교한다.
int seqSearch(int[] E, int n, int K)
1. int ans, index;
2. ans = -1; // 실패 가정
3. for (index = 0; index < n; index++)
4. if (K == E[index])
5. ans = index; // 성공
6. break;
7. return ans;
이 알고리즘의 기본 연산(Basic Operation)은 K와 배열 원소의 비교이다. 입력 크기(Input Size)는 n이다.
알고리즘 분석
알고리즘을 분석하는 목적은 개선하거나, 여러 후보 중 선택하기 위함이다. 분석 기준은 세 가지이다.
- 정확성(Correctness): 모든 입력에 대해 올바른 결과를 내는가
- 수행량(Amount of Work): 시간, 공간 복잡도
- 최적성(Optimality): 이론적으로 가장 빠른 알고리즘인가
수행량 측정
수행량은 특정 컴퓨터, 프로그래밍 언어, 프로그래머에 독립적인 척도여야 한다. 보통 입력 크기 n에 대한 함수로 나타낸다.
기본 연산(Basic Operation)을 정의하고 그 횟수를 센다. 기본 연산이란 문제의 핵심이 되는 연산으로, 가장 많이 수행되는 연산이다. 전체 연산 횟수는 기본 연산 횟수에 대략 비례한다.
또한 알고리즘의 동작에 영향을 미치는 입력의 속성을 파악해야 한다. 같은 크기 n이라도 입력에 따라 수행량이 달라질 수 있다.
최악의 경우 복잡도(Worst-Case Complexity)
$D_n$을 크기 $n$인 입력의 집합, $I$를 $D_n$의 원소, $t(I)$를 입력 $I$에서 기본 연산 횟수라 하자.
\[W(n) = \max\{t(I) \mid I \in D_n\}\]W(n)은 크기 n인 모든 입력 중 기본 연산을 가장 많이 수행하는 경우의 횟수이다.
순차 탐색에서 최악의 경우는 $K$가 배열의 마지막에 있거나 없는 경우이다. 이때 비교 횟수는 $n$이므로 $W(n) = n$이다.
평균 복잡도(Average-Case Complexity)
$Pr(I)$를 입력 $I$가 발생할 확률이라 하면:
\[A(n) = \sum_{I \in D_n} Pr(I) \cdot t(I)\]순차 탐색의 평균 분석을 위해 두 경우를 분리한다.
\[A(n) = Pr(succ) \cdot A_{succ}(n) + Pr(fail) \cdot A_{fail}(n)\]탐색 성공 확률을 $q$라 하자. $K$가 배열의 각 위치에 균등하게 분포한다고 가정하면 $Pr(I_i \mid succ) = 1/n$이고, 위치 $i$에서의 비교 횟수는 $i + 1$이다.
\[A_{succ}(n) = \sum_{i=0}^{n-1} \frac{1}{n}(i+1) = \frac{n+1}{2}\]실패 시에는 항상 $n$번 비교하므로 $A_{fail}(n) = n$이다.
\[A(n) = q \cdot \frac{n+1}{2} + (1-q) \cdot n\]$t(I)$는 알고리즘 분석으로 계산할 수 있지만, $Pr(I)$는 통계적으로만 구할 수 있다.
공간 사용량과 간결성
사용 공간도 입력에 따라 달라질 수 있으며, 최악/평균 분석을 할 수 있다. 시간과 공간 사이에는 트레이드오프(tradeoff)가 존재한다.
간결성(Simplicity)도 미덕이다. 가독성이 높아지고, 불필요한 연산이 줄며, 직관적이고 유지보수가 쉬워진다.
정확성 증명
알고리즘은 입력(사전조건, Precondition)을 출력(사후조건, Postcondition)으로 변환하는 단계의 나열이다. 정확성 증명은 다음을 보이는 것이다:
사전조건이 만족되면, 알고리즘이 종료했을 때 사후조건이 항상 참이다.
반복문이 포함된 알고리즘에서는 루프 불변(Loop Invariant)을 사용한다. 루프 불변은 세 단계로 증명한다:
- Initialization: 루프 시작 전에 속성이 성립한다
- Maintenance: 루프가 한 번 실행되면 속성이 유지된다
- Termination: 루프 종료 시 증명하고자 하는 속성이 만족된다
수학적 배경
급수(Series)
급수는 수열의 합이다. 알고리즘 분석에서 자주 등장하는 급수들:
등차급수:
\[\sum_{i=1}^{n} i = \frac{n(n+1)}{2}\]제곱의 합:
\[\sum_{i=1}^{n} i^2 = \frac{2n^3+3n^2+n}{6} \approx \frac{n^3}{3}\]일반 다항급수:
\[\sum_{i=1}^{n} i^k \approx \frac{n^{k+1}}{k+1}\]2의 거듭제곱 합:
\[\sum_{i=0}^{k} 2^i = 2^{k+1} - 1\]산술-기하급수:
\[\sum_{i=1}^{k} i \cdot 2^i = (k-1) \cdot 2^{k+1} + 2\]논리(Logic)
- $A \Rightarrow B$는 $\neg A \lor B$와 논리적으로 동치이다
- 드 모르간 법칙: $\neg(A \land B) \equiv \neg A \lor \neg B$, $\neg(A \lor B) \equiv \neg A \land \neg B$
증명 기법
| 기법 | 설명 |
|---|---|
| 반례(Counterexample) | 하나의 반례로 명제를 반증한다 |
| 대우(Contraposition) | $A \Rightarrow B$ 대신 $\neg B \Rightarrow \neg A$를 증명한다 |
| 귀류법(Contradiction) | 부정을 가정하여 모순을 유도한다 |
| 수학적 귀납법(Mathematical Induction) | 기저 사례 + 귀납 단계로 증명한다. 루프 불변과 연결된다 |
최적성(Optimality)
모든 문제에는 고유한 문제 복잡도(inherent complexity)가 있다. 문제를 풀기 위해 필요한 최소 기본 연산 횟수가 존재한다.
최적 알고리즘을 보이는 절차:
- 효율적인 알고리즘 $A$를 설계하고, 최악 복잡도 $W_A(n)$을 구한다
- 같은 클래스의 모든 알고리즘에 대해, 어떤 입력에서 최소 $F(n)$번의 기본 연산이 필요함을 증명한다 (하한, Lower Bound)
- $W_A(n) = F(n)$이면 알고리즘 $A$는 최적(optimal)이다
- 그렇지 않으면 더 나은 알고리즘이 존재하거나, 더 나은 하한이 존재한다
예제: 배열 최댓값 찾기
문제: 크기 n인 비정렬 배열에서 최댓값을 찾는다.
int findMax(int[] E, int n)
1. int max;
2. max = E[0];
3. for (index = 1; index < n; index++)
4. if (max < E[index])
5. max = E[index];
6. return max;
- 기본 연산: 배열 원소 간 비교
- $W_A(n) = n - 1$: 모든 입력에서 정확히 $n-1$번 비교한다
$F(n)$ 증명: $n$개의 서로 다른 원소 중 최댓값은 1개이고, 나머지 $n-1$개는 최댓값이 아니다. 어떤 원소가 최댓값이 아님을 결론짓려면 다른 원소보다 작다는 비교가 최소 1번 필요하다. 따라서 최소 $n-1$번의 비교가 필요하다. $F(n) = n - 1$.
$W_A(n) = F(n)$이므로 findMax 알고리즘은 최적이다.
점근적 증가율(Asymptotic Growth Rate)
입력이 충분히 클 때, 상수 인자(constant factor)와 작은 입력을 무시하고 함수의 증가율만 비교하는 것이 점근적 분석이다.
O, Θ, Ω 표기법
f와 g가 비음수 정수에서 비음수 실수로의 함수일 때:

| 표기 | 정의 | 의미 |
|---|---|---|
| $O(g)$ | 어떤 $c > 0$, $n_0 \geq 0$에 대해 $f(n) \leq c \cdot g(n)$, $\forall n \geq n_0$ | $g$보다 느리거나 같은 함수들의 집합 (상한) |
| $\Omega(g)$ | 어떤 $c > 0$, $n_0 \geq 0$에 대해 $f(n) \geq c \cdot g(n)$, $\forall n \geq n_0$ | $g$보다 빠르거나 같은 함수들의 집합 (하한) |
| $\Theta(g)$ | $O(g) \cap \Omega(g)$ | $g$와 같은 증가율인 함수들의 집합 (tight bound) |
$f \in \Theta(g)$는 “f is asymptotic order g” 또는 “f is order g”로 읽는다.
극한을 이용한 비교
$\lim_{n \to \infty} \frac{f(n)}{g(n)}$의 값으로 관계를 판별할 수 있다:
| 극한값 | 결론 |
|---|---|
| $< \infty$ (0 포함) | $f \in O(g)$ |
| $> 0$ ($\infty$ 포함) | $f \in \Omega(g)$ |
| $= c$ ($0 < c < \infty$) | $f \in \Theta(g)$ |
| $= 0$ | $f \in o(g)$ — “little oh”, $f$가 $g$보다 엄격히 느리게 증가 |
| $= \infty$ | $f \in \omega(g)$ — “little omega”, $f$가 $g$보다 엄격히 빠르게 증가 |
O, Θ, Ω의 성질
- 이행성(Transitive): $f \in O(g)$이고 $g \in O(h)$이면 $f \in O(h)$. $\Omega$, $\Theta$, $o$, $\omega$도 동일하다
- 반사성(Reflexive): $f \in \Theta(f)$
- 대칭성(Symmetric): $f \in \Theta(g)$이면 $g \in \Theta(f)$. $\Theta$는 동치 관계(equivalence relation)를 정의한다
- $f \in O(g) \Leftrightarrow g \in \Omega(f)$
- $O(f + g) = O(\max(f, g))$
함수 분류
| 증가율 | 이름 |
|---|---|
| $\Theta(1)$ | 상수(constant) |
| $\Theta(\log n)$ | 로그(logarithmic) |
| $\Theta(n)$ | 선형(linear) |
| $\Theta(n \log n)$ | 선형로그(linearithmic) |
| $\Theta(n^2)$ | 이차(quadratic) |
| $\Theta(n^3)$ | 삼차(cubic) |
| $\Theta(2^n)$ | 지수(exponential) |
핵심 성질: 다항 함수의 증가율은 어떤 지수 함수보다 느리다. 즉, $n^k \in o(c^n)$ ($k > 0$, $c > 1$).
또한 $\log(n!) \in \Theta(n \log n)$이다 (스털링 근사).
증가율 비교
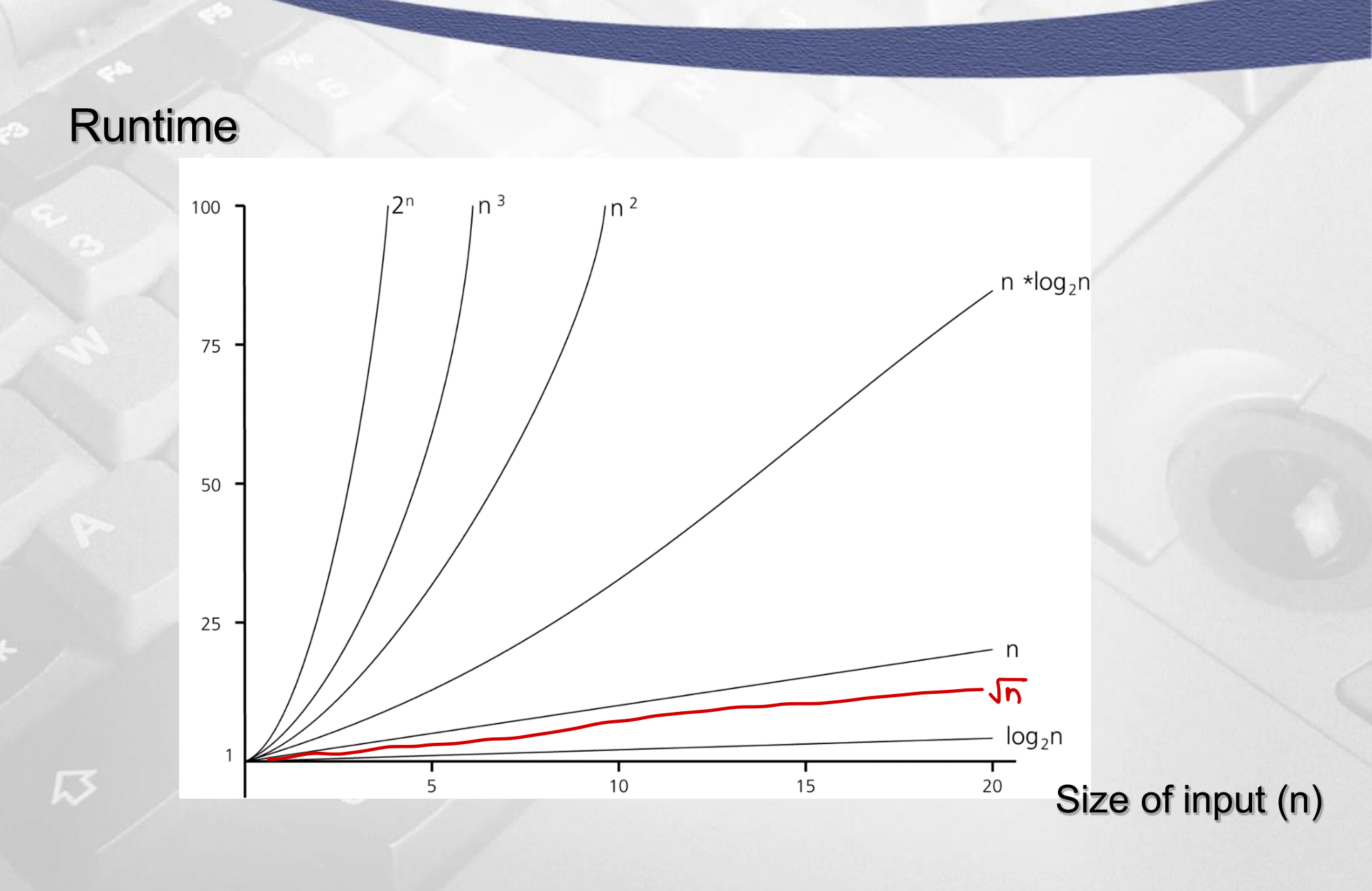
n이 작을 때는 증가율 차이가 미미하지만, n이 커지면 격차가 기하급수적으로 벌어진다.
| Function | n=10 | n=100 | n=1,000 | n=10,000 | n=100,000 | n=1,000,000 |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| log₂n | 3 | 6 | 9 | 13 | 16 | 19 |
| n | 10 | 10² | 10³ | 10⁴ | 10⁵ | 10⁶ |
| n·log₂n | 30 | 664 | 9,965 | 10⁵ | 10⁶ | 10⁷ |
| n² | 10² | 10⁴ | 10⁶ | 10⁸ | 10¹⁰ | 10¹² |
| n³ | 10³ | 10⁶ | 10⁹ | 10¹² | 10¹⁵ | 10¹⁸ |
| 2ⁿ | 10³ | 10³⁰ | 10³⁰¹ | 10³·⁰¹⁰ | 10³⁰·¹⁰³ | 10³⁰¹·⁰³⁰ |
상수는 왜 무시하는가
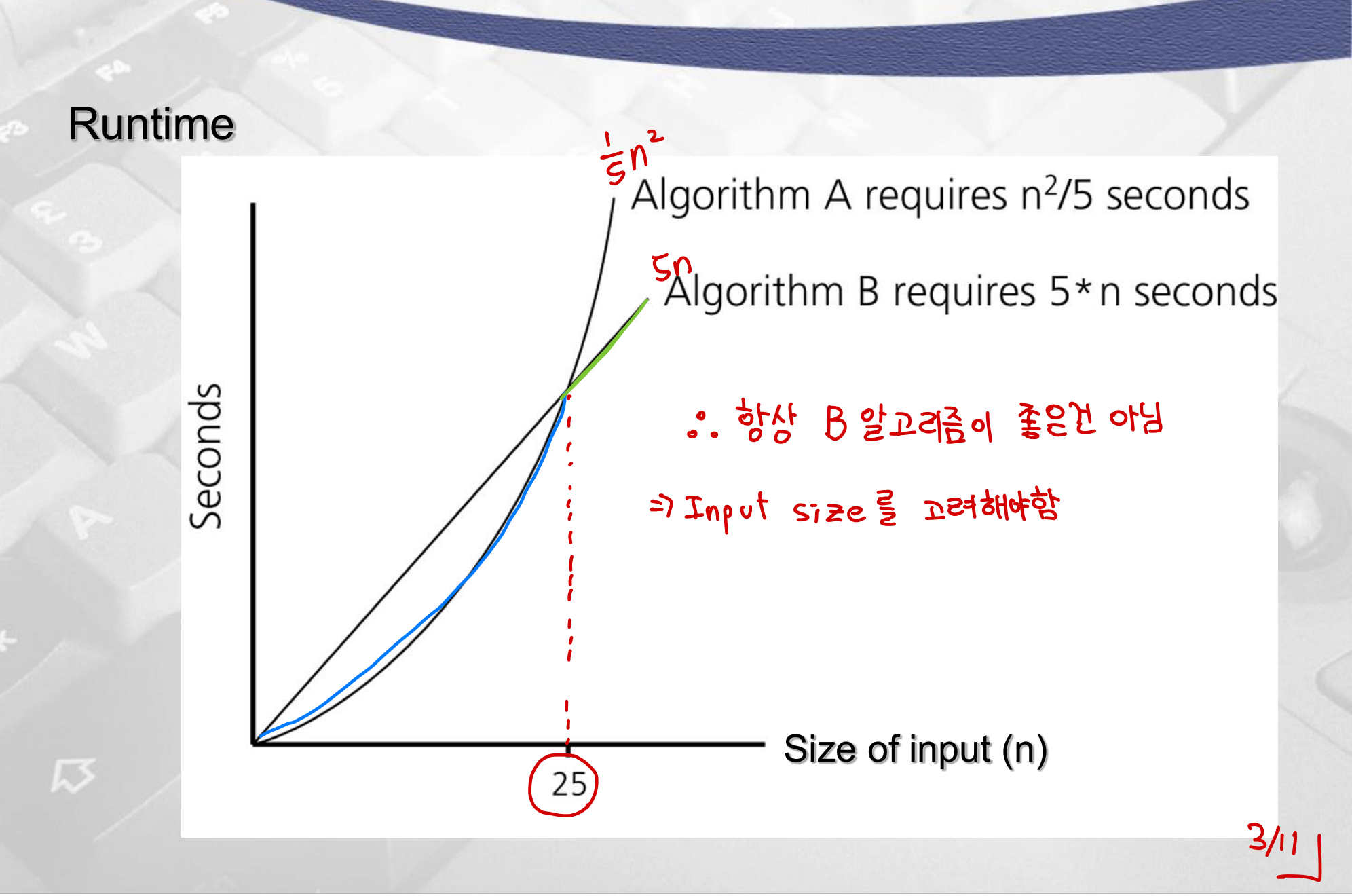
알고리즘 A의 수행 시간이 n²/5이고 알고리즘 B가 5n이라면, n < 25에서는 A가 빠르다. 하지만 n > 25부터는 B가 항상 빠르고, 그 격차는 점점 벌어진다. 점근적 분석에서 상수를 무시하는 이유가 여기에 있다. 입력이 충분히 클 때의 증가율이 실질적인 성능을 결정한다.
정렬 배열 탐색
배열 탐색 문제에서 전략을 개선해 나가는 과정을 통해, 알고리즘 분석의 전체 프레임워크를 적용한다.
전략 A: 비정렬 배열 + 순차 탐색
앞서 분석한 seqSearch이다. $W(n) = n$, $A(n) = q \cdot (n+1)/2 + (1-q) \cdot n$.
비정렬 배열에서 $F(n) = n$이다. 배열이 정렬되지 않았으면 최악의 경우 모든 원소를 확인해야 하므로. 따라서 전략 A는 최적이다.
전략 B: 정렬 배열 + 순차 탐색
입력을 비감소 순서(nondecreasing order)로 정렬된 배열로 바꾸되, 알고리즘은 동일한 순차 탐색을 사용한다.
$W(n) = n$, $A(n) = q \cdot (n+1)/2 + (1-q) \cdot n$. 전략 A와 동일하다. 정렬되어 있다는 정보를 전혀 활용하지 못하고 있다.
전략 C: 정렬 배열 + 개선된 순차 탐색
정렬된 배열에서 K보다 큰 원소를 만나면 즉시 탐색을 종료할 수 있다.
int seqSearchMod(int[] E, int n, int K)
1. int ans, index;
2. ans = -1;
3. for (index = 0; index < n; index++)
4. if (K > E[index])
5. continue;
6. if (K < E[index])
7. break; // K보다 큰 원소 → 이후에 없음
8. // K == E[index]
9. ans = index;
10. break;
11. return ans;
- 기본 연산:
>,<비교 - $W(n) = n + 1 \in O(n)$: 최악의 경우 $K$가 배열의 최대 원소보다 클 때
- $A(n) \approx n/2$: 실패 시에도 평균적으로 절반만 탐색한다
전략 A, B의 최악 복잡도와 동일하게 $O(n)$이다. 그렇다면 $O(n)$보다 빠를 수 있는가?
전략 D: 정렬 배열 + 이진 탐색(Binary Search)
분할 정복(Divide and Conquer) 전략이다. K를 배열의 중간 원소와 비교하여, 한 번의 비교로 탐색 범위를 절반으로 줄인다. 이를 재귀적으로 반복한다.
int binarySearch(int[] E, int first, int last, int K)
1. if (last < first) // base case
2. index = -1;
3. else // recursive case
4. int mid = (first + last) / 2;
5. if (K == E[mid])
6. index = mid;
7. else if (K < E[mid])
8. index = binarySearch(E, first, mid-1, K);
9. else // K > E[mid]
10. index = binarySearch(E, mid+1, last, K);
11. return index;
최악 복잡도
기본 연산은 K와 배열 원소의 비교이다. 한 번의 비교(three-way branch: <, >, ==)로 범위가 절반으로 줄어든다.
$n$을 2로 몇 번 나눌 수 있는가? $n/2^d \geq 1$이면 $d \leq \log n$이다. 재귀 호출을 따라 $\lfloor \log n \rfloor$번 비교하고, 첫 비교를 포함하면:
\[W(n) = \lfloor \log n \rfloor + 1 = \lceil \log(n+1) \rceil \in \Theta(\log n)\]$O(n)$에서 $O(\log n)$으로, 극적인 개선이다.
평균 복잡도
$n = 2^d - 1$로 놓으면(완전 이진 트리), 탐색 실패 시 항상 $d = \log(n+1)$번 비교하므로 $A_{fail} = \log(n+1)$.
탐색 성공 시, $t$번 비교가 필요한 원소는 $2^{t-1}$개이다 (트리의 깊이 $t$에 있는 노드 수). 성공 확률이 균등하다면:
\[A_{succ}(n) = \lg(n+1) - 1 + \frac{\lg(n+1)}{n}\] \[A(n) \approx \lg(n+1) - q\]여기서 $q$는 탐색 성공 확률이다.
이진 탐색의 최적성
$O(n)$에서 $O(\log n)$으로 개선했다. 더 나은 알고리즘이 가능한가?
결정 트리(Decision Tree)
알고리즘 A와 입력 크기 n에 대한 결정 트리는, 알고리즘이 수행하는 비교를 이진 트리로 표현한 것이다.
- 루트: 알고리즘이 처음 비교하는 배열 인덱스
- 노드 X의 라벨이 i일 때:
- 왼쪽 자식: $K < E[i]$일 때 다음 비교할 인덱스
- 오른쪽 자식: $K > E[i]$일 때 다음 비교할 인덱스
- $K = E[i]$이면 탐색 성공이므로 분기 없음

$n=10$인 이진 탐색의 결정 트리이다. 루트 인덱스는 $(0+9)/2 = 4$이다. $K < E[4]$이면 왼쪽(인덱스 1), $K > E[4]$이면 오른쪽(인덱스 7)으로 이동한다.
하한 증명
최악 비교 횟수는 결정 트리의 루트에서 리프까지의 최장 경로 길이 $p$이다.
결정 트리의 노드 수를 $N$이라 하면, 깊이 $p$인 이진 트리의 노드 수는 최대 $1 + 2 + 4 + \cdots + 2^{p-1} = 2^p - 1$이므로:
\[N \leq 2^p - 1 \implies 2^p \geq N + 1\]핵심 주장: 올바른 알고리즘의 결정 트리는 최소 $N \geq n$개의 노드를 가져야 한다.
귀류법으로 증명: 라벨 $i$ ($0 \leq i \leq n-1$)가 없는 노드가 있다고 가정하자. 두 배열 $E1$과 $E2$를 만든다. $E1[i] = K$이고 $E2[i] = K’ > K$이며, 나머지 위치는 동일하게 정렬된 값으로 채운다. 알고리즘은 인덱스 $i$를 한 번도 비교하지 않으므로 $E1$과 $E2$에 대해 같은 결과를 낸다. 하지만 $E1$에서는 $i$를 반환해야 하고 $E2$에서는 아니다. 모순이다. 따라서 $N \geq n$이다.
이를 결합하면:
\[2^p \geq N + 1 \geq n + 1 \implies p \geq \log(n+1) \implies p \geq \lceil \log(n+1) \rceil\]정리: 비교 기반으로 크기 $n$인 배열에서 $K$를 탐색하는 모든 알고리즘은, 어떤 입력에 대해 최소 $\lceil \log(n+1) \rceil$번의 비교를 수행해야 한다.
따름정리: 이진 탐색(알고리즘 D)의 최악 비교 횟수가 $\lceil \log(n+1) \rceil$이므로, 이진 탐색은 최적이다.