I/O Systems and Multiprocessor — I/O 통신 기법과 멀티프로세서 구조
CPU가 아무리 빨라도 외부 장치와 데이터를 주고받지 못하면 쓸모가 없다. I/O 장치는 CPU보다 훨씬 느리고, 이 속도 차이를 어떻게 처리하느냐가 시스템 성능의 핵심이다.
I/O 모듈과 버스
I/O 모듈(I/O Module)은 컴퓨터와 외부 세계를 연결하는 통로이다. 키보드, 마우스, 디스플레이, 디스크 드라이브 등 다양한 I/O 장치로 구성된다. 입력 없는 프로그램은 매번 같은 결과만 내고, 출력 없는 프로그램은 실행할 이유가 없다.
버스(Bus)는 주소(address), 데이터(data), 제어(control) 신호를 전달하는 병렬 배선의 집합이다. 고정 크기의 바이트 묶음인 워드(word) 단위로 데이터를 전송한다. 현재 대부분의 시스템에서 워드 크기는 4바이트 또는 8바이트이다.
버스 아키텍처
I/O 장치는 CPU와 메모리에 비해 클럭 주파수를 따라가지 못한다. 이 속도 차이를 해결하기 위해 버스를 계층적으로 분리한다.
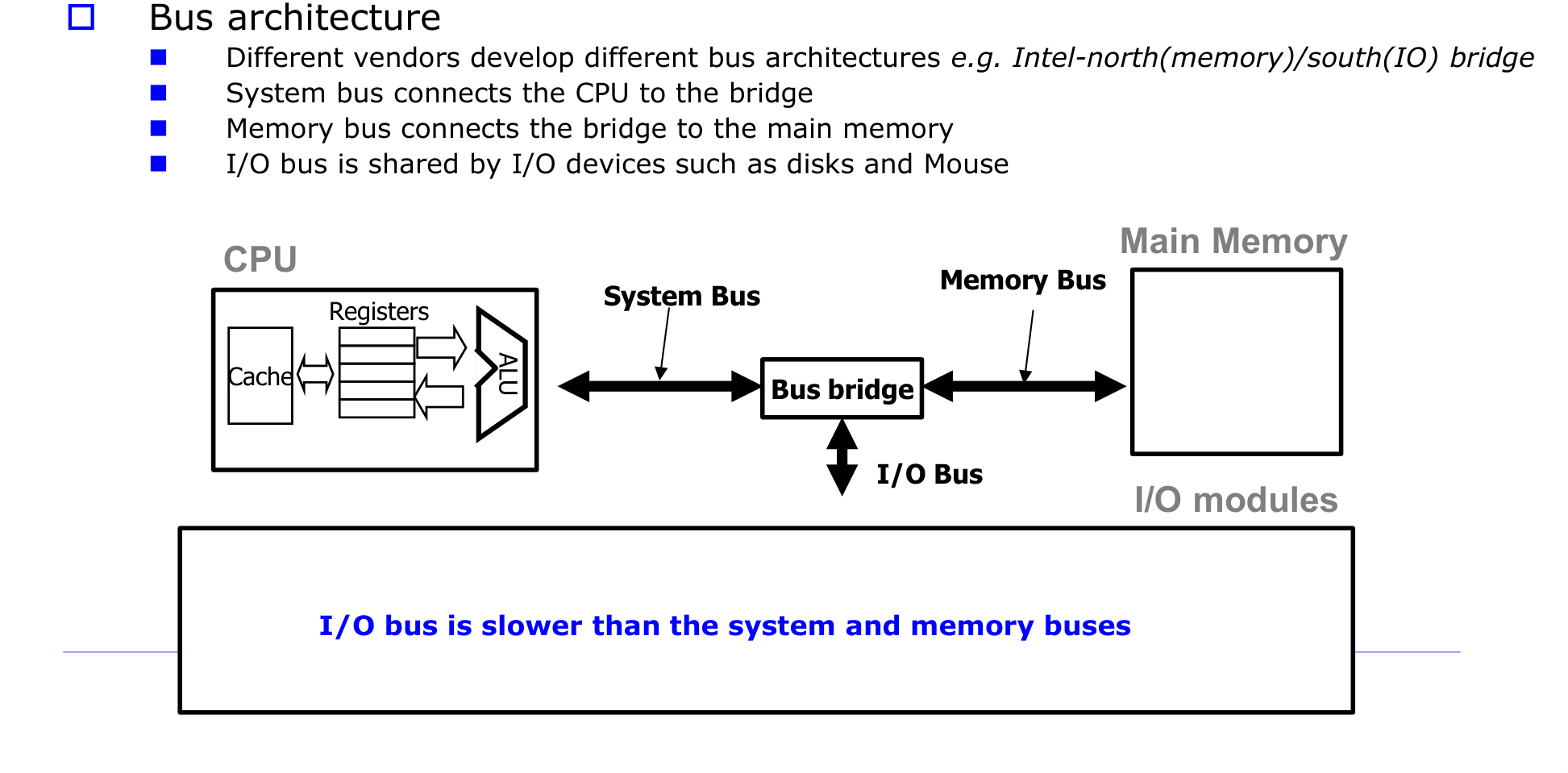
버스 브리지(Bus Bridge)는 서로 다른 버스를 연결하는 부품이다. 시스템 버스의 전기 신호를 각 버스에 맞게 변환한다. Intel의 North Bridge(메모리 연결)와 South Bridge(I/O 연결) 구조가 대표적이다.
| 버스 | 연결 대상 | 속도 |
|---|---|---|
| 시스템 버스(System Bus) | CPU ↔ 버스 브리지 | 가장 빠름 |
| 메모리 버스(Memory Bus) | 버스 브리지 ↔ 메인 메모리 | 빠름 |
| I/O 버스(I/O Bus) | 버스 브리지 ↔ I/O 모듈 | 가장 느림 |
I/O 버스는 시스템 버스와 메모리 버스보다 느리다. 다양한 I/O 장치들이 이 I/O 버스를 공유한다.
디바이스 컨트롤러와 디바이스 드라이버
디바이스 컨트롤러(Device Controller)
각 I/O 장치는 컨트롤러(Controller) 또는 어댑터(Adapter)를 통해 I/O 버스에 연결된다. 컨트롤러는 특정 유형의 장치를 담당하며, 하나의 컨트롤러에 여러 장치가 연결될 수도 있다. USB 컨트롤러, 그래픽 어댑터, 디스크 컨트롤러 등이 있다.
컨트롤러는 메인보드에 내장(built-in)되거나 장치 자체에 포함된다. 복잡한 장치의 컨트롤러는 자체적으로 간단한 CPU를 포함하기도 한다.
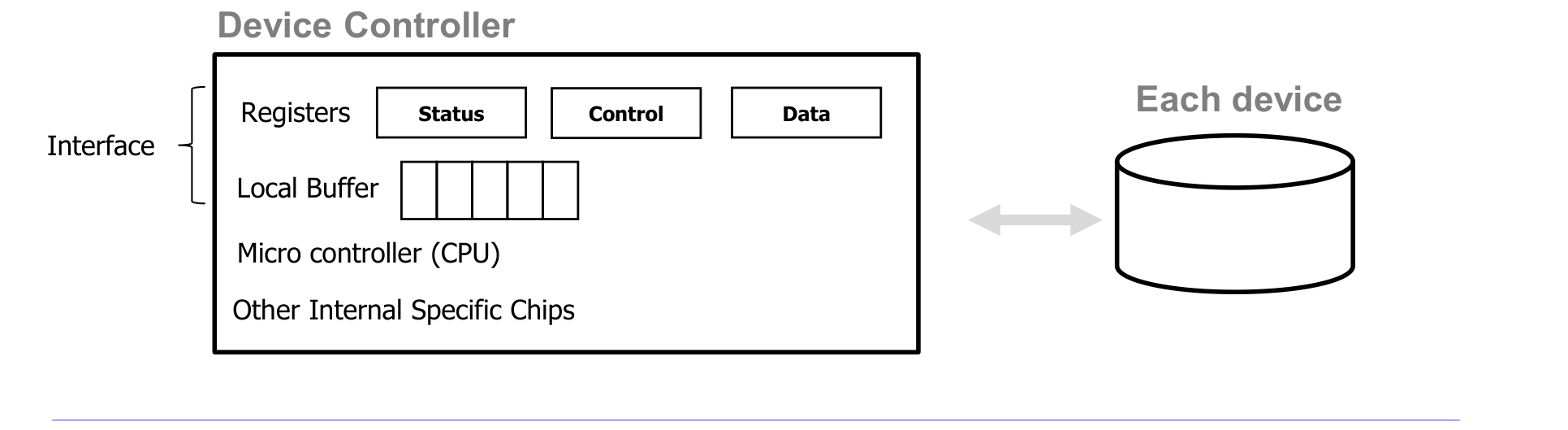
디바이스 컨트롤러의 구성:
- 인터페이스(Interface): 디바이스 드라이버가 컨트롤러를 제어할 수 있는 부분이다
- Status 레지스터: 장치의 현재 상태를 나타낸다
- Control 레지스터: 장치에 명령을 내리는 데 사용된다
- Data 레지스터: 데이터를 주고받는 데 사용된다
- 로컬 버퍼(Local Buffer): 장치와 주고받는 데이터를 임시 저장한다
- 마이크로 컨트롤러(Micro Controller): 컨트롤러 내부의 간단한 CPU이다
- 기타 내부 칩: 장치 고유의 하드웨어 로직이다
디바이스 드라이버(Device Driver)
OS는 각 디바이스 컨트롤러에 대응하는 디바이스 드라이버(Device Driver)를 가진다. 드라이버는 OS 코드로, 컨트롤러의 레지스터를 조작하여 장치를 제어한다.
- I/O 시작: 드라이버가 컨트롤러의 적절한 레지스터에 값을 로드한다
- I/O 완료: 컨트롤러가 인터럽트를 통해 완료를 알린다
버스 트랜잭션
버스 트랜잭션(Bus Transaction)은 읽기 또는 쓰기 작업을 수행하기 위한 일련의 단계이다. 두 개의 장치가 참여한다.
- 버스 마스터(Bus Master): 트랜잭션을 시작하는 장치이다. 버스 요청 신호를 보낸다. 예: CPU
- 버스 슬레이브(Bus Slave): 마스터의 명령을 받아 처리하는 장치이다. 예: 메모리
여러 마스터가 동시에 버스를 사용하려 하면 충돌이 발생한다. 버스 아비터(Bus Arbiter)가 이를 중재한다. 버스 요청 신호를 받아 하나의 마스터에만 grant 신호를 보내 버스 접근을 허용한다.
메모리 접근
메모리 접근은 load와 store 명령어로 수행된다. x86에서 movq %rax, A(레지스터 %rax의 값을 주소 A에 저장)를 실행하면 CPU가 write 트랜잭션을 시작한다.
- CPU가 주소 A를 시스템 버스에 올린다. 메인 메모리가 이를 읽고 데이터를 기다린다
- CPU가 데이터 워드 y를 버스에 올린다
- 메인 메모리가 버스에서 데이터 워드 y를 읽어 주소 A에 저장한다
I/O 통신 기법
장치에서 데이터 블록을 읽어 메모리에 저장하는 세 가지 방법이 있다.
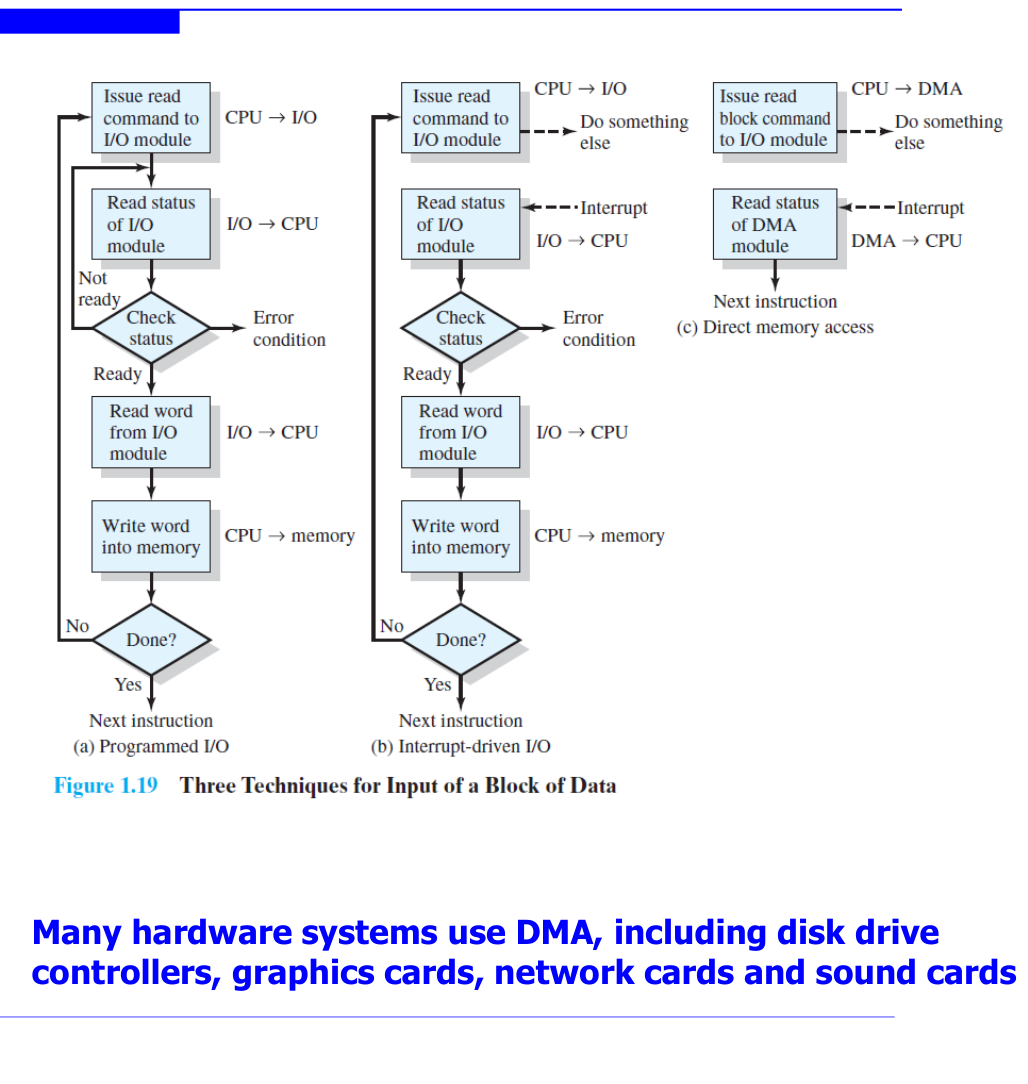
Programmed I/O (폴링)
CPU가 직접 I/O 작업의 모든 과정을 관장하는 방식이다.
- CPU가 I/O 모듈에 read 명령을 내린다 (CPU → I/O)
- CPU가 I/O 컨트롤러의 status 레지스터를 반복적으로 확인(Polling)한다 (I/O → CPU)
- 준비 완료 시 CPU가 I/O 컨트롤러의 data 레지스터에서 데이터를 읽는다 (I/O → CPU)
- CPU가 데이터를 메모리에 저장한다 (CPU → Memory)
- 전체 블록이 완료될 때까지 반복한다
문제: CPU가 I/O 완료를 기다리며 계속 상태를 확인하느라 다른 작업을 하지 못한다. 장치가 매우 빠른 경우에만 합리적이다.
Interrupt-Driven I/O
폴링의 CPU 낭비 문제를 해결한다.
- CPU가 I/O 모듈에 read 명령을 내린다
- CPU는 다른 유용한 작업을 계속 수행한다
- I/O 작업이 완료되면 컨트롤러가 인터럽트 신호를 CPU에 보낸다
- CPU가 현재 작업을 중단하고 인터럽트 핸들러를 실행한다
- 핸들러가 I/O 컨트롤러에서 데이터를 읽어 메모리에 저장한다
I/O 대기 시간 동안 CPU가 다른 일을 할 수 있으므로 폴링보다 효율적이다. 하지만 여전히 I/O 모듈에서 메모리로의 모든 데이터 이동이 CPU를 거쳐야 한다는 한계가 있다. 대용량 데이터 전송에서는 CPU의 적극적인 개입이 부담이 된다.
DMA(Direct Memory Access)
대용량 데이터 전송에 적합한 방식이다. 장치가 CPU의 지속적인 개입 없이 메모리에 직접 접근할 수 있다.
- CPU가 I/O 모듈에 블록 전송 명령을 내린다 (소스/목적 주소, 바이트 수 지정)
- CPU는 다른 작업을 수행한다
- I/O 컨트롤러가 장치에서 데이터를 읽어 메인 메모리에 직접 전송(DMA)한다
- 전송 완료 시 컨트롤러가 CPU에 인터럽트로 알린다
핵심은 데이터가 CPU를 거치지 않고 I/O 컨트롤러에서 메모리로 바로 간다는 점이다. 디스크 드라이브 컨트롤러, 그래픽 카드, 네트워크 카드, 사운드 카드 등 많은 하드웨어 시스템이 DMA를 사용한다.
세 기법 비교
| 기법 | CPU 관여도 | I/O 중 CPU 활용 | 데이터 경로 | 적합한 상황 |
|---|---|---|---|---|
| Programmed I/O | 매우 높음 (폴링) | 불가 | I/O → CPU → Memory | 매우 빠른 장치 |
| Interrupt-Driven I/O | 중간 (인터럽트) | 가능 | I/O → CPU → Memory | 일반적인 I/O |
| DMA | 낮음 (시작/완료만) | 가능 | I/O → Memory (직접) | 대용량 데이터 |
I/O 주소 공간
I/O 장치도 주소를 가진다. 이 주소를 포트(Port)라 한다. 포트에 접근하는 방식은 두 가지이다.
Port-mapped I/O
I/O 장치가 메모리와 별도의 주소 공간을 사용한다. I/O 주소 공간은 메모리 주소 공간과 격리(isolated)되어 있다. x86 아키텍처의 in, out 같은 전용 I/O 명령어를 사용한다. I/O 포트 번호가 메모리 주소와 겹치더라도, 명령어가 다르기 때문에 구분된다.
Memory-mapped I/O
장치 레지스터를 메인 메모리 주소 공간의 일부로 취급한다. 일반적인 load, store 명령어로 장치에 접근할 수 있다. 단, I/O에 할당된 주소는 일반 물리 메모리로 사용할 수 없다.
멀티프로세서 시스템
AMP vs SMP
멀티프로세서 시스템은 두 가지 유형으로 나뉜다.
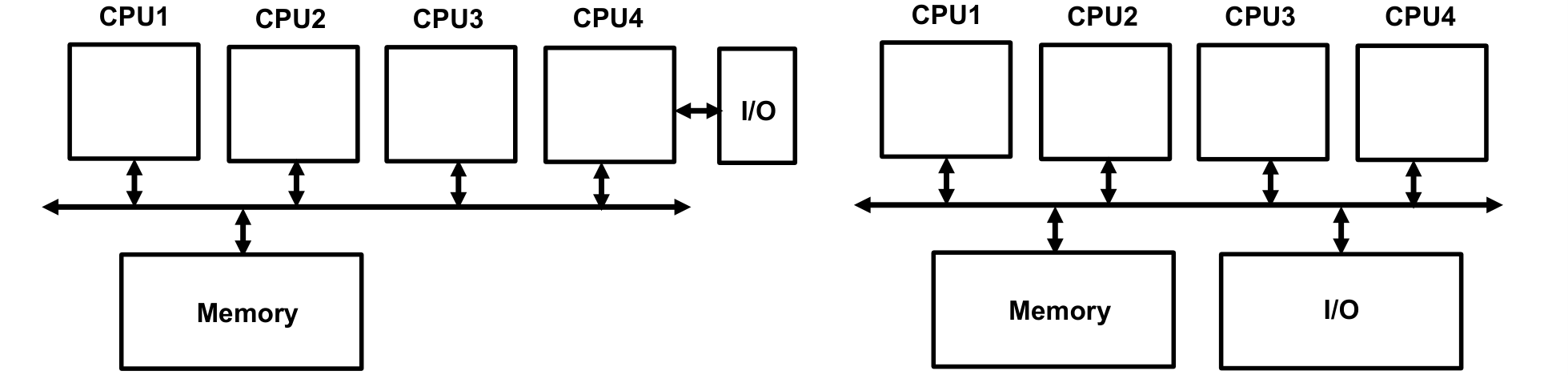
비대칭 멀티프로세싱(AMP, Asymmetric Multiprocessing)
- 모든 프로세서가 동등하게 취급되지 않는다
- 하나의 프로세서만 OS 코드를 실행하거나(마스터), 하나의 CPU만 I/O를 수행하는 식이다
대칭 멀티프로세싱(SMP, Symmetric Multiprocessing)
- 각 프로세서가 독립적으로 작업을 수행할 수 있다
- 마스터-슬레이브 관계가 없다
- 모든 프로세서가 메모리와 I/O 자원을 공유한다
UMA vs NUMA
SMP에서 모든 프로세서가 하나의 공유 메모리에 접근하면, 프로세서 수가 늘어날수록 메모리가 병목이 된다. 이를 해결하기 위한 것이 NUMA(Non-Uniform Memory Access)이다.
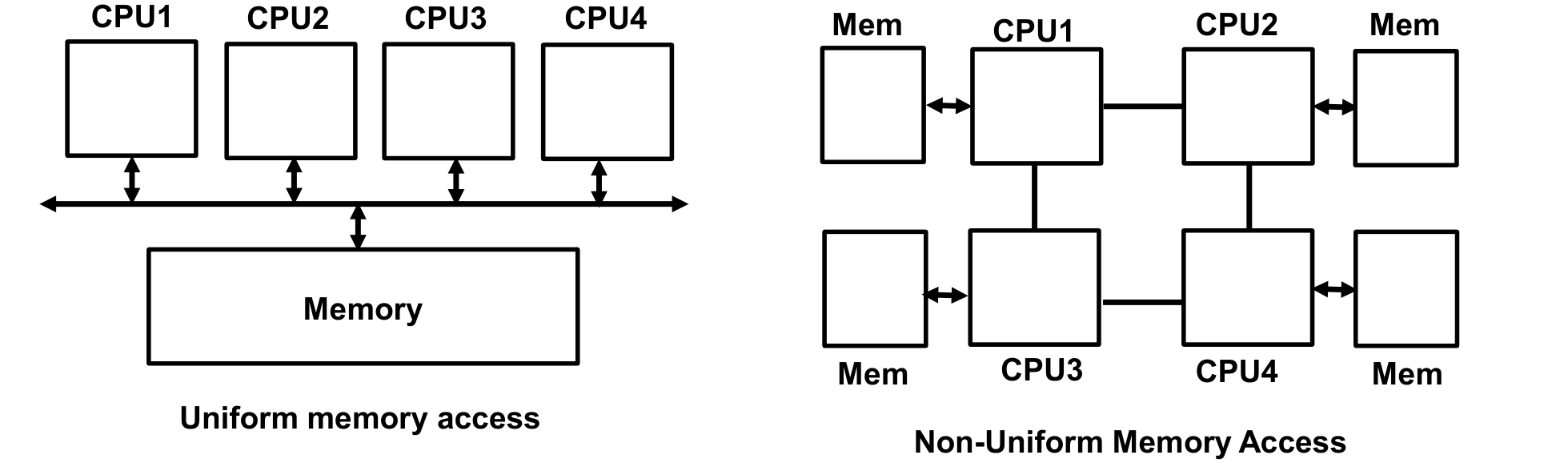
UMA(Uniform Memory Access)
- 모든 프로세서가 공유 메모리에 동일한 접근 시간으로 접근한다
- SMP의 기본 구조이다
- 프로세서 수가 많아지면 메모리 버스가 병목이 된다
NUMA(Non-Uniform Memory Access)
- 각 프로세서가 로컬 메모리를 가진다
- 자신의 로컬 메모리 접근은 빠르고, 다른 프로세서의 메모리(원격 메모리) 접근은 느리다
- 메모리 접근 시간이 메모리 위치에 따라 균일하지 않다(Non-Uniform)
- 대규모 멀티프로세서 시스템에서 메모리 병목을 완화한다
멀티코어 시스템
하나의 칩에 여러 컴퓨팅 코어를 넣는 것이 현대 CPU 설계의 흐름이다.
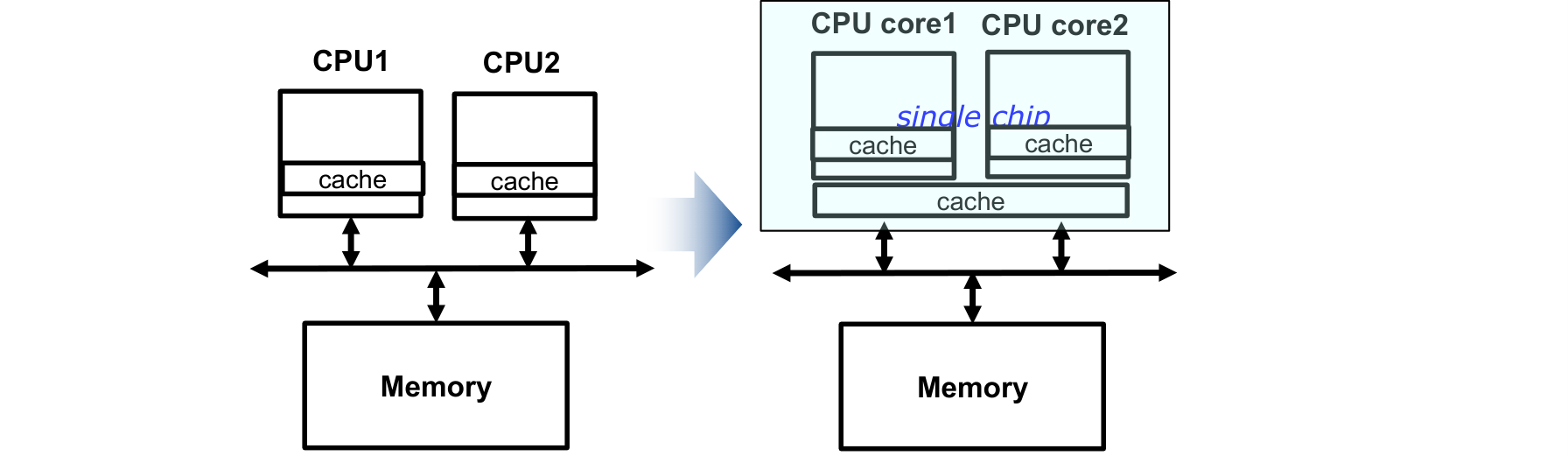
멀티코어의 장점:
- 칩 내부(on-chip) 통신이 칩 간(between-chip) 통신보다 빠르다
- 하나의 멀티코어 칩이 여러 싱글코어 칩보다 전력 소모가 적다
- 로컬 캐시와 공유 캐시를 조합하여 사용할 수 있다
멀티칩 구조에서는 CPU1과 CPU2가 각각 독립적인 캐시를 가지고 별도의 칩에 존재한다. 멀티코어 구조에서는 CPU core1과 core2가 하나의 칩(single chip) 안에 있으며, 각자의 L1 캐시와 공유 L2 캐시를 함께 사용한다.