Computer Abstractions and Technology — 컴퓨터 추상화와 기술
컴퓨터는 어떻게 구성되고, 성능은 어떻게 측정하는가. 컴퓨터 구조론의 첫 번째 챕터에서 다루는 핵심 개념들을 정리한다.
컴퓨터의 분류
컴퓨터는 용도에 따라 크게 네 가지로 나뉜다.
| 분류 | 특징 |
|---|---|
| 개인용 컴퓨터(PC) | 범용, 비용/성능 트레이드오프 |
| 서버 | 네트워크 기반, 높은 용량·성능·신뢰성 |
| 슈퍼컴퓨터 | 서버의 일종, 고성능 과학/공학 연산 특화 |
| 임베디드 컴퓨터 | 시스템 내부에 내장, 전력/성능/비용 제약 엄격 |
Post-PC 시대
스마트폰과 태블릿 같은 개인 휴대 장치(PMD, Personal Mobile Device)가 PC를 대체하고 있다. 소프트웨어의 일부는 PMD에서, 나머지는 클라우드(Cloud)에서 실행되는 구조가 보편화되었다. Amazon, Google 같은 기업이 운영하는 창고 규모 컴퓨터(WSC, Warehouse Scale Computer)가 이를 뒷받침한다.
컴퓨터 구조의 7가지 핵심 아이디어
- 추상화(Abstraction)를 통한 설계 단순화
- 공통 경우를 빠르게(Make the common case fast)
- 병렬성(Parallelism)을 통한 성능 향상
- 파이프라이닝(Pipelining) — 단계별 처리로 처리량 증가
- 예측(Prediction) — 분기 예측 등을 통한 성능 향상
- 메모리 계층(Hierarchy of memories) — 빠르고 비싼 메모리 + 크고 싼 메모리 조합
- 중복(Redundancy)을 통한 신뢰성 확보
이 7가지 아이디어는 컴퓨터 구조 전반에 걸쳐 반복적으로 등장한다.
프로그램 아래의 세계
컴퓨터 시스템은 세 개의 층으로 구성된다.
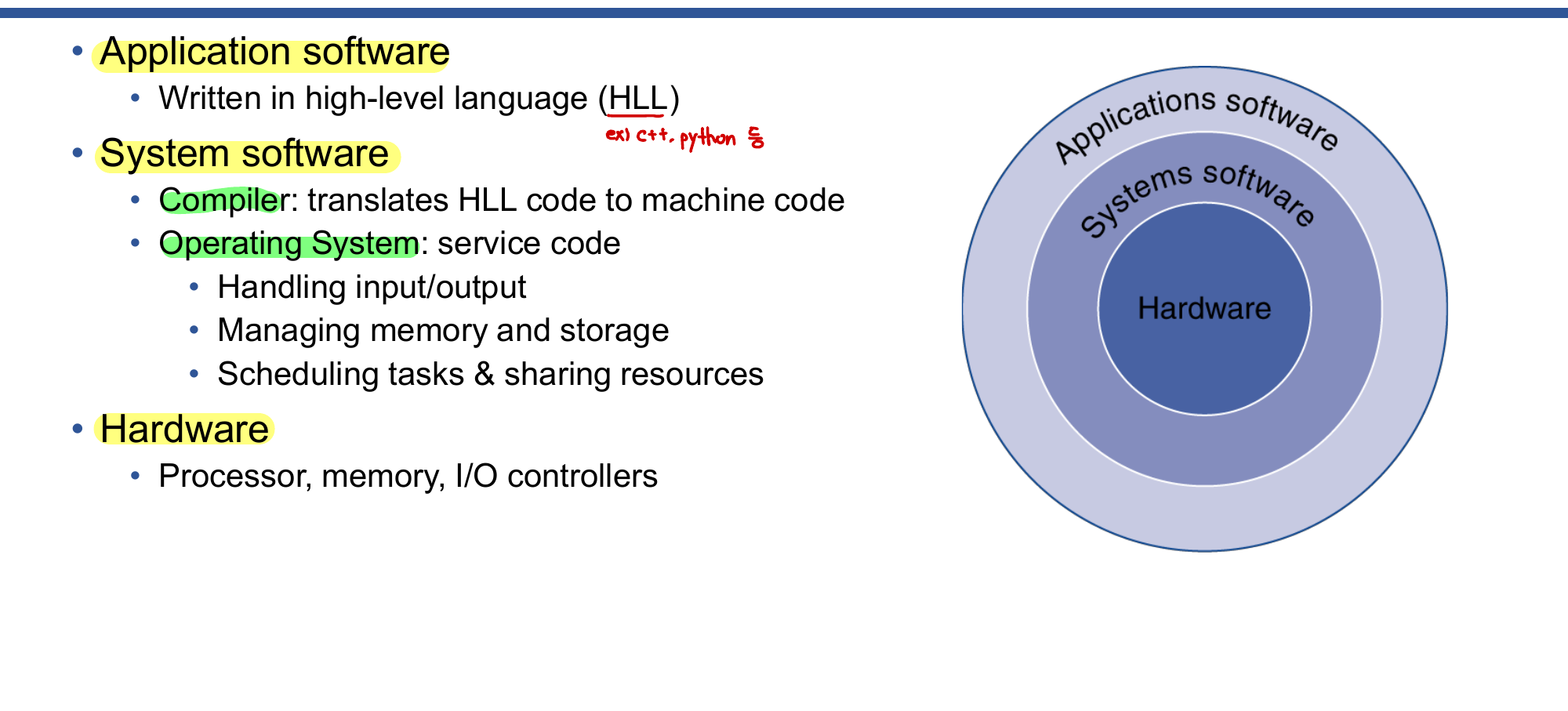
- 응용 소프트웨어(Application Software): 고급 언어(HLL)로 작성
- 시스템 소프트웨어(System Software): 컴파일러(HLL → 기계어 변환), 운영체제(I/O 관리, 메모리 관리, 태스크 스케줄링)
- 하드웨어(Hardware): 프로세서, 메모리, I/O 컨트롤러
프로그램 코드의 수준
고급 언어로 작성된 코드가 실제 하드웨어에서 실행되기까지 여러 단계의 변환을 거친다.

고급 언어 (C, Python 등)
↓ 컴파일러
어셈블리 언어 (MIPS 등)
↓ 어셈블러
기계어 (이진수)
- 고급 언어(HLL): 문제 영역에 가까운 추상화, 생산성과 이식성 제공
- 어셈블리 언어: 기계어를 사람이 읽을 수 있는 형태로 표현한 것
- 기계어: 하드웨어가 직접 처리하는 이진 표현
컴퓨터의 구성 요소
데스크톱, 서버, 임베디드 — 종류와 무관하게 모든 컴퓨터는 동일한 구성 요소를 갖는다.

- 입출력(I/O): 사용자 인터페이스(디스플레이, 키보드, 마우스), 저장 장치(HDD, SSD), 네트워크 어댑터
- 프로세서(CPU):
- 데이터패스(Datapath): 데이터에 대한 연산 수행
- 제어(Control): 데이터패스, 메모리 등의 순서를 조율
- 캐시 메모리(Cache): 빠른 SRAM 기반의 임시 저장소
- 메모리(Memory): 실행 중인 프로그램과 데이터를 보관
추상화 계층
복잡성을 다루기 위해 추상화를 사용한다. 핵심 추상화 인터페이스는 다음과 같다.
- 명령어 집합 구조(ISA, Instruction Set Architecture): 하드웨어/소프트웨어 경계의 인터페이스
- 응용 이진 인터페이스(ABI, Application Binary Interface): ISA + 시스템 소프트웨어 인터페이스
- 구현(Implementation): 인터페이스 아래의 실제 구현 세부사항
ISA가 동일하면, 다른 구현(implementation)을 사용하더라도 같은 소프트웨어를 실행할 수 있다.
프로세서와 메모리 기술
전자 기술의 발전은 컴퓨터 성능 향상의 근본 동력이다.
| 연도 | 기술 | 상대 성능/비용 |
|---|---|---|
| 1951 | 진공관 | 1 |
| 1965 | 트랜지스터 | 35 |
| 1975 | 집적 회로(IC) | 900 |
| 1995 | VLSI | 2,400,000 |
| 2013 | ULSI | 250,000,000,000 |
IC 제조 공정
실리콘(Silicon)은 반도체로서, 재료를 추가하여 도체·절연체·스위치 특성을 만들 수 있다. IC 제조 과정은 다음과 같다.
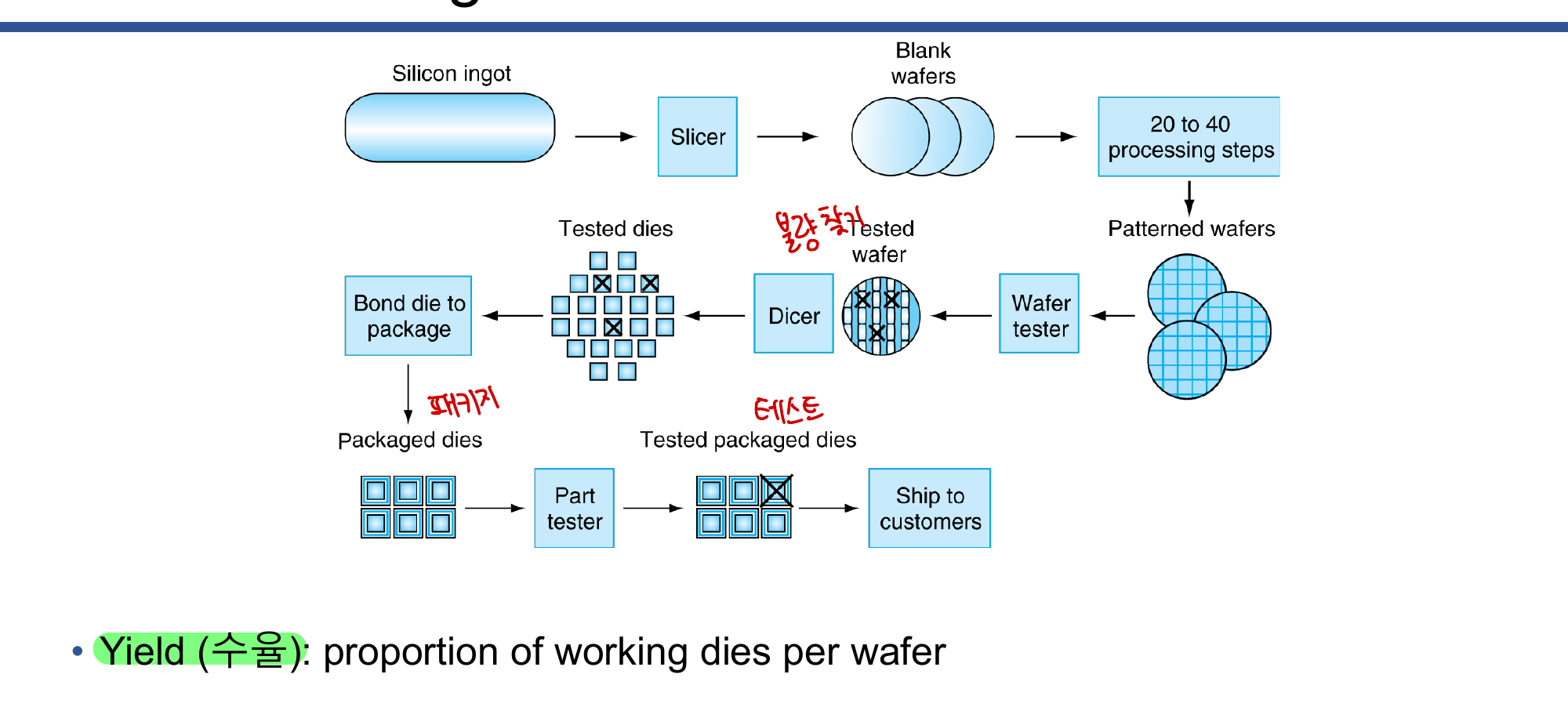
실리콘 잉곳 → 슬라이서 → 빈 웨이퍼 → 20~40단계 가공 → 패턴 웨이퍼
→ 웨이퍼 테스트 → 다이서(절단) → 테스트된 다이 → 패키징 → 최종 테스트 → 출하
수율(Yield)은 웨이퍼 당 정상 작동하는 다이의 비율이다. 예를 들어 Intel Core 10세대의 경우, 300mm 웨이퍼에서 506개의 칩을 생산하며 10nm 공정을 사용한다.
성능
응답 시간과 처리량
- 응답 시간(Response Time): 하나의 작업을 완료하는 데 걸리는 시간
- 처리량(Throughput): 단위 시간당 처리하는 작업의 총량
프로세서를 더 빠른 것으로 교체하면 응답 시간이 줄어든다. 프로세서를 더 추가하면 처리량이 늘어난다(응답 시간은 변하지 않을 수도 있다).
상대 성능
Performance = 1 / Execution Time
“X가 Y보다 n배 빠르다”는 다음을 의미한다:
Performance_X / Performance_Y = Execution Time_Y / Execution Time_X = n
예: 프로그램 실행에 A는 10초, B는 15초 걸린다면, A는 B보다 1.5배 빠르다 (15/10 = 1.5).
CPU 시간
- 경과 시간(Elapsed Time): 처리, I/O, OS 오버헤드, 유휴 시간 포함한 전체 시간
- CPU 시간(CPU Time): 해당 작업의 처리에만 소요된 시간 (I/O, 다른 작업 제외)
클럭
디지털 하드웨어는 일정한 주기의 클럭(Clock)에 의해 동작한다.
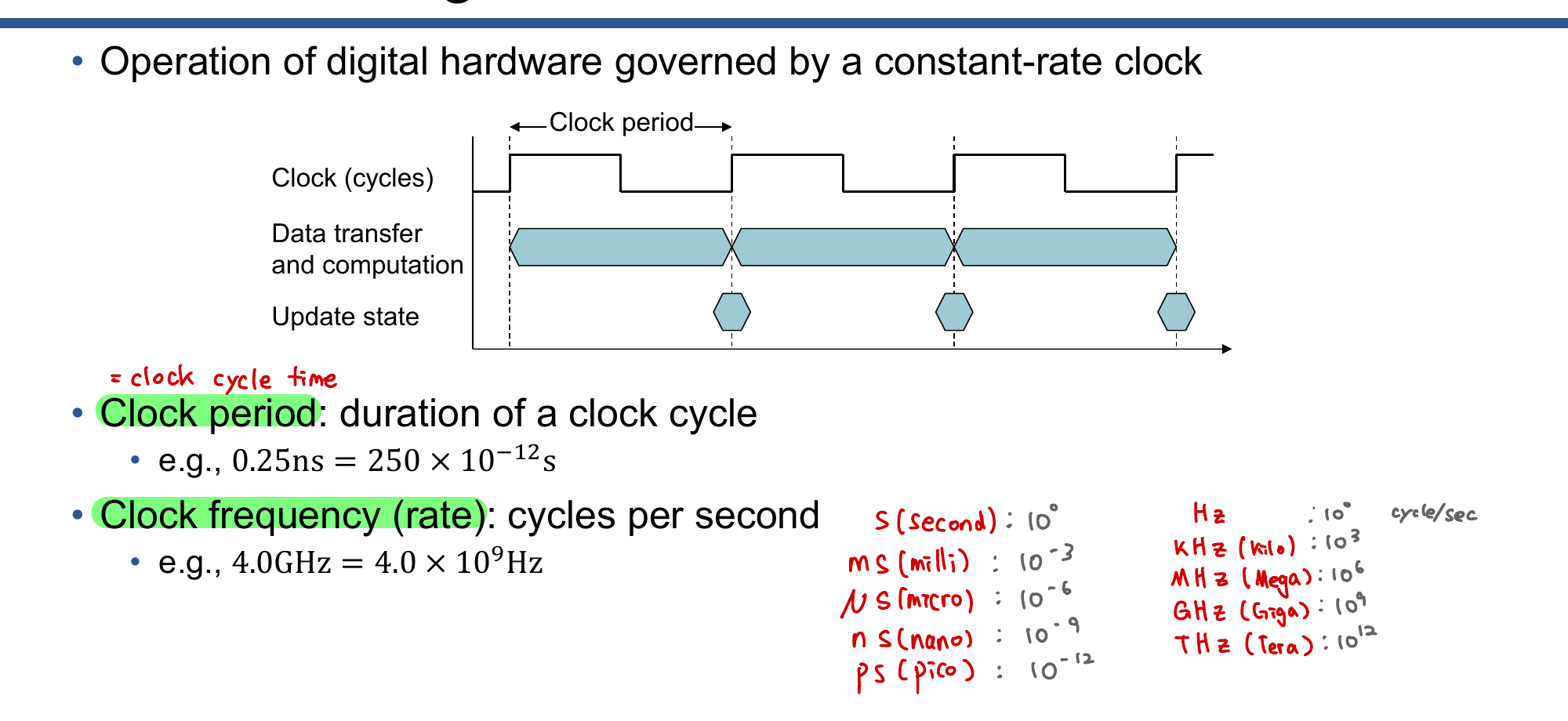
- 클럭 주기(Clock Period): 한 클럭 사이클의 지속 시간. 예: 0.25ns = 250ps
- 클럭 주파수(Clock Rate): 초당 사이클 수. 예: 4.0GHz = 4.0 × 10⁹ Hz
단위 정리:
| 시간 단위 | 값 | 주파수 단위 | 값 |
|---|---|---|---|
| ms (밀리) | 10⁻³ | KHz (킬로) | 10³ |
| μs (마이크로) | 10⁻⁶ | MHz (메가) | 10⁶ |
| ns (나노) | 10⁻⁹ | GHz (기가) | 10⁹ |
| ps (피코) | 10⁻¹² | THz (테라) | 10¹² |
CPU Time 공식
CPU Time = CPU Clock Cycles × Clock Cycle Time
= CPU Clock Cycles / Clock Rate
성능을 올리는 두 가지 방법:
- 클럭 사이클 수 줄이기 — 같은 작업을 더 적은 사이클로
- 클럭 속도 올리기 — 각 사이클을 더 빠르게
여기서 핵심은 트레이드오프다. 클럭 속도를 올리면 한 사이클에 할 수 있는 일이 줄어들어 더 많은 사이클이 필요해진다. 반대로 사이클 수를 줄이면 한 사이클에 더 많은 일을 수행해야 하므로 클럭 속도가 낮아진다.
예제: Computer A (2GHz, 10초 CPU Time) → Computer B (6초 CPU Time, 1.2배 사이클 수) 설계
Clock Cycles_A = 10s × 2GHz = 20 × 10⁹
Clock Rate_B = (1.2 × 20 × 10⁹) / 6s = 24 × 10⁹ / 6s = 4GHz
명령어 수와 CPI
CPI(Cycles Per Instruction)는 명령어 하나당 평균 클럭 사이클 수이다.
Clock Cycles = Instruction Count × CPI
CPU Time = Instruction Count × CPI × Clock Cycle Time
- 명령어 수(Instruction Count): 프로그램, ISA, 컴파일러에 의해 결정
- CPI: CPU 하드웨어에 의해 결정. 명령어 종류마다 CPI가 다를 수 있으므로 가중 평균을 사용
CPI 예제: 같은 ISA를 사용하는 두 컴퓨터 비교
| Cycle Time | CPI | |
|---|---|---|
| Computer A | 0.25ns (250ps) | 2.0 |
| Computer B | 0.5ns (500ps) | 1.2 |
CPU Time_A = I × 2.0 × 250ps = I × 500ps
CPU Time_B = I × 1.2 × 500ps = I × 600ps
CPU Time_B / CPU Time_A = 600/500 = 1.2
A가 B보다 1.2배 빠르다.
CPI 세부 계산
명령어 종류에 따라 CPI가 다를 때, 가중 평균 CPI를 계산한다.
CPI = Σ (CPI_i × Instruction Count_i / Instruction Count)
예제: 명령어 클래스 A(CPI=1), B(CPI=2), C(CPI=3)
| A | B | C | 총 명령어 | Clock Cycles | 평균 CPI | |
|---|---|---|---|---|---|---|
| Sequence 1 | 2 | 1 | 2 | 5 | 2×1+1×2+2×3=10 | 10/5=2.0 |
| Sequence 2 | 4 | 1 | 1 | 6 | 4×1+1×2+1×3=9 | 9/6=1.5 |
명령어 수는 Sequence 2가 더 많지만, CPI가 낮아서 오히려 Clock Cycles가 적다.
성능 요약
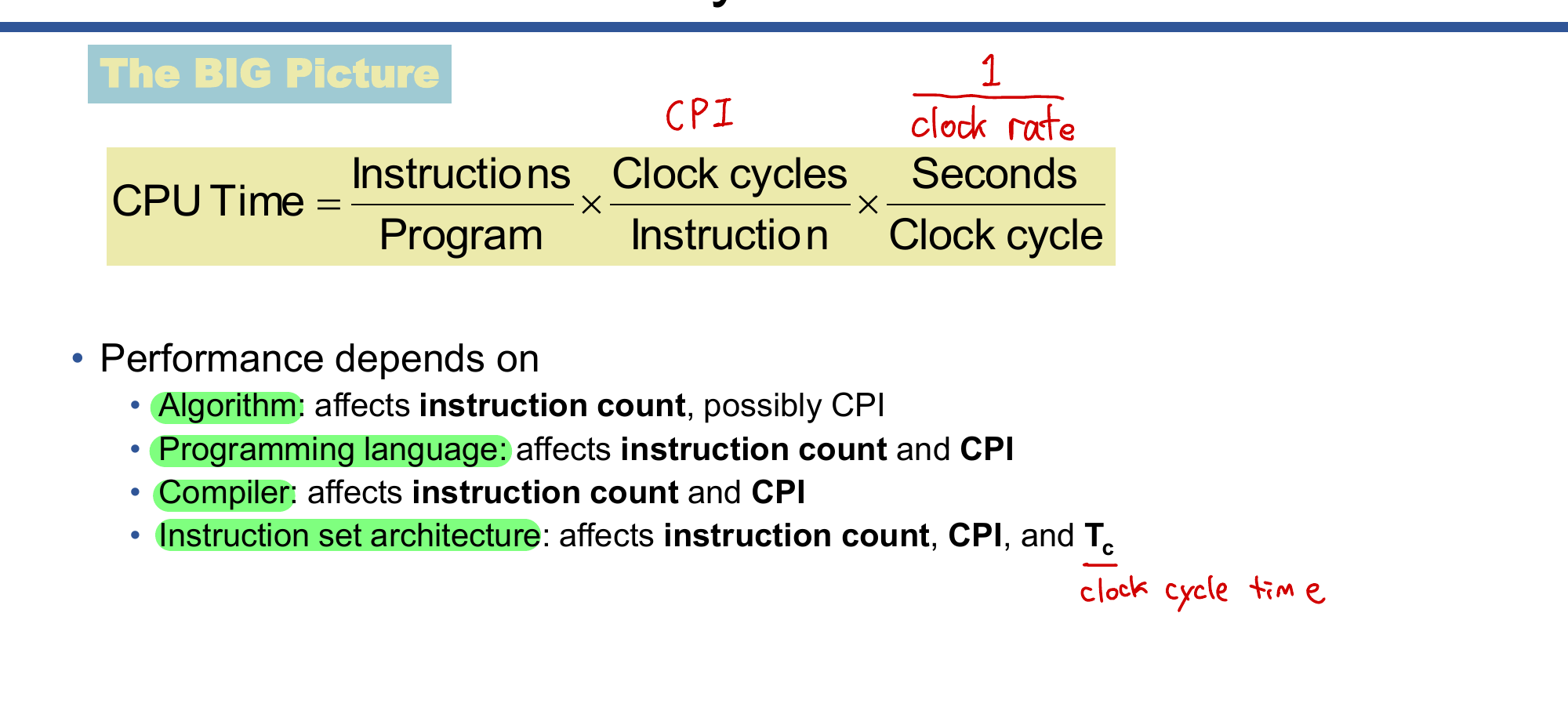
CPU Time = (Instructions / Program) × (Clock Cycles / Instruction) × (Seconds / Clock Cycle)
각 요소에 영향을 미치는 것:
| 요소 | 영향받는 항목 |
|---|---|
| 알고리즘 | 명령어 수, (CPI) |
| 프로그래밍 언어 | 명령어 수, CPI |
| 컴파일러 | 명령어 수, CPI |
| ISA | 명령어 수, CPI, Clock Cycle Time |
전력 장벽 (Power Wall)
CMOS IC에서 전력 소비 공식:
Power = Capacitive Load × Voltage² × Frequency
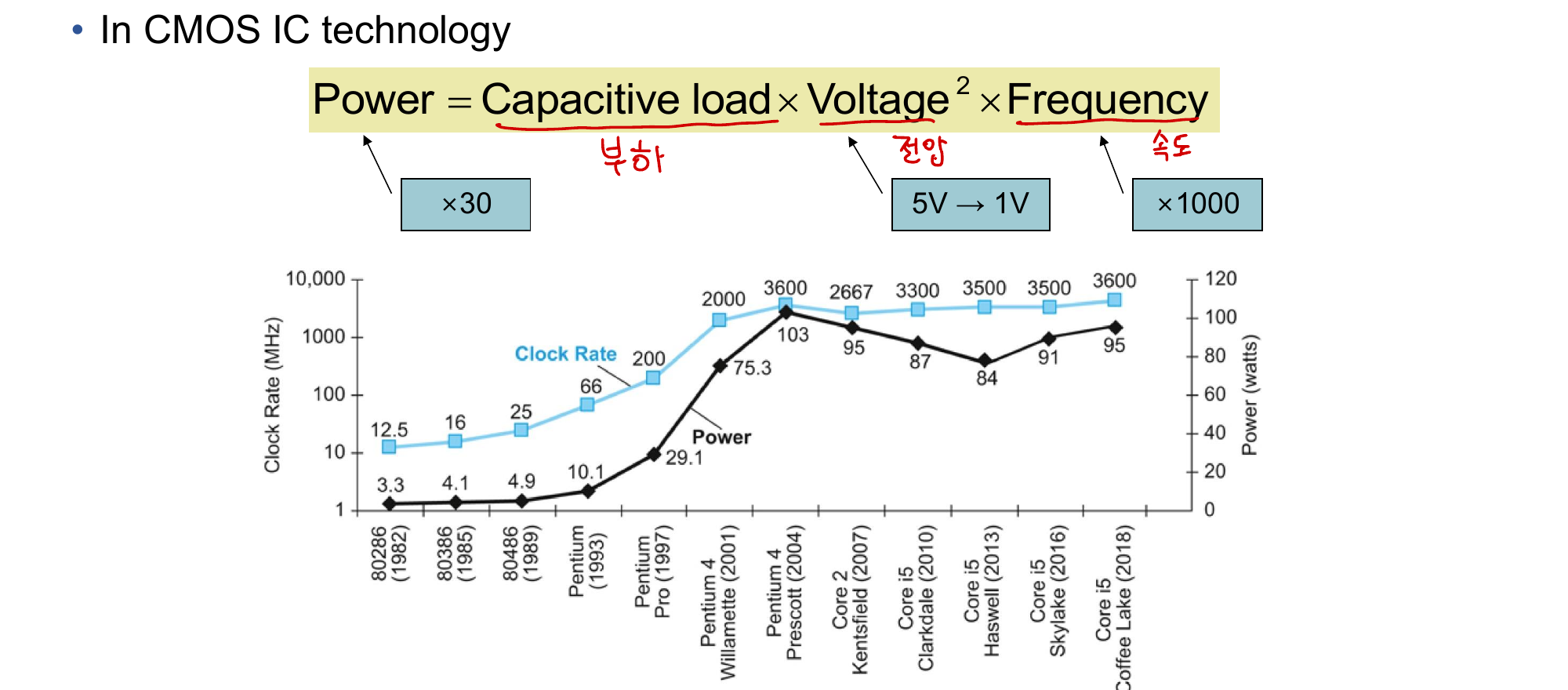
지난 수십 년간 클럭 속도는 약 ×1000 증가했지만, 전압을 5V에서 1V로 낮추고(×30) 전력 소비를 억제해왔다. 하지만 이제 전압을 더 낮출 수 없고, 열을 더 이상 제거할 수 없는 한계에 도달했다. 이것이 전력 장벽(Power Wall)이다.
예제: 새 CPU가 기존 대비 용량 부하 85%, 전압·주파수 각각 15% 감소했다면:
P_new / P_old = 0.85 × 0.85² × 0.85 = 0.85⁴ = 0.52
전력을 약 절반으로 줄일 수 있다. 하지만 이것만으로는 부족하다.
멀티프로세서로의 전환
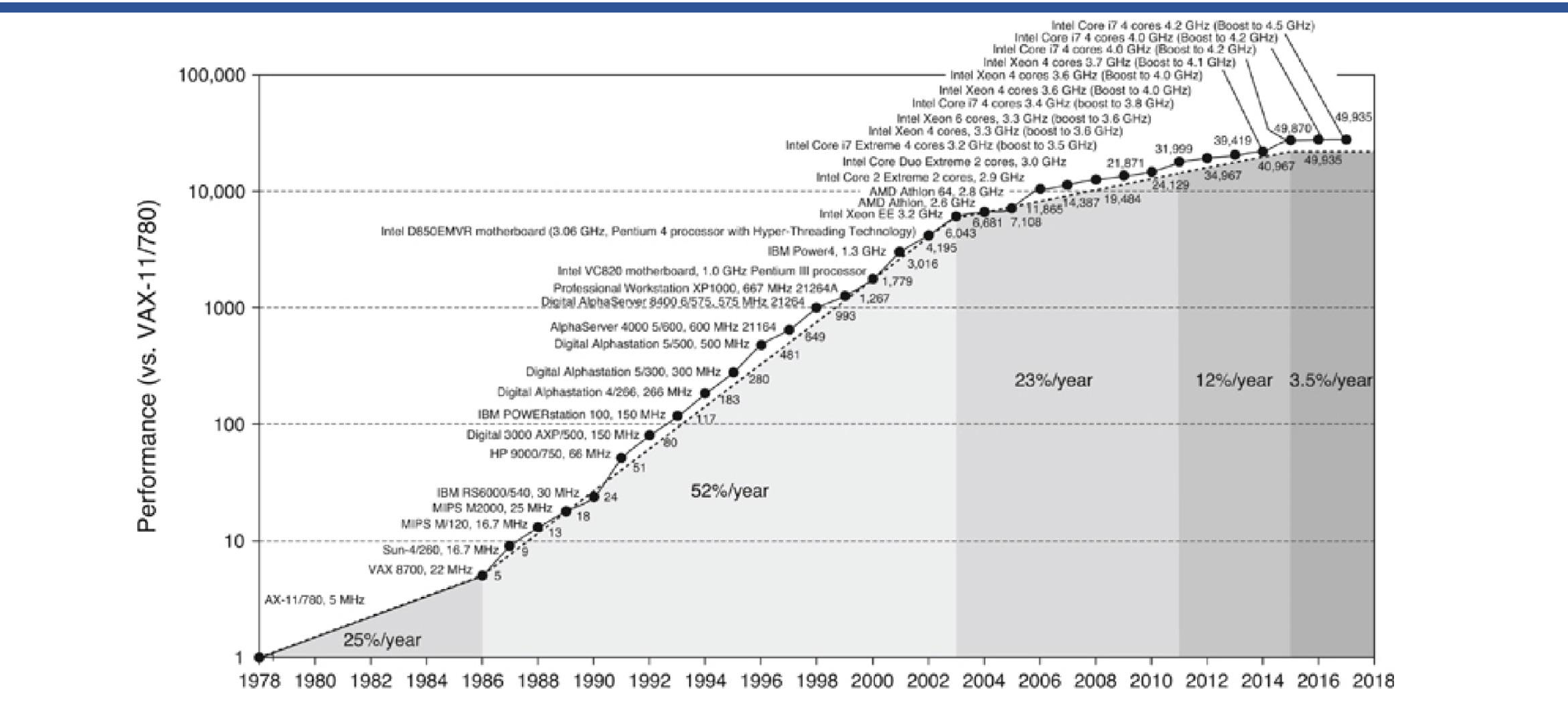
단일 프로세서의 성능 증가율은 시대에 따라 급격히 둔화되었다:
- 1986~2003: 연 52% 증가
- 2003~2011: 연 23% 증가
- 2011~2015: 연 12% 증가
- 2015 이후: 연 3.5% 증가
전력 장벽으로 인해 클럭 속도를 더 올릴 수 없게 되자, 멀티코어 프로세서로 방향을 전환했다. 하나의 칩에 여러 개의 프로세서를 넣는 것이다.
하지만 멀티코어는 명시적 병렬 프로그래밍을 요구한다. 로드 밸런싱, 통신 및 동기화 최적화 등의 난제가 뒤따른다. 명령어 수준 병렬성(ILP)처럼 하드웨어가 알아서 처리해주는 것과는 다르다.
SPEC 벤치마크
실제 성능을 측정하기 위해 SPEC(Standard Performance Evaluation Corporation)에서 벤치마크를 개발한다.
- SPEC CPU2017: 선별된 프로그램들의 실행 시간을 측정. I/O를 최소화하여 CPU 성능에 집중
- 기준 머신 대비 성능 비율의 기하 평균(Geometric Mean)으로 요약
Geometric Mean = ⁿ√(∏ Execution Time Ratio_i) (i = 1 ~ n)
SPEC Power 벤치마크
전력 효율도 중요한 지표다. 다양한 부하 수준(0%~100%)에서의 성능 대비 전력 소비를 측정한다.
Overall ssj_ops per Watt = Σ ssj_ops_i / Σ power_i (i = 0 ~ 10)
함정과 오류
Amdahl’s Law (암달의 법칙)
시스템의 일부를 개선했을 때, 전체 성능 향상은 개선되지 않은 부분에 의해 제한된다.
T_improved = T_affected / improvement factor + T_unaffected
예제: 전체 100초 중 곱셈이 80초를 차지한다. 전체 성능을 5배로 올리려면 곱셈을 얼마나 개선해야 하는가?
20 = 80/n + 20
불가능하다. 곱셈 시간을 0으로 만들어도 20초가 남기 때문에, 최대 5배(100/20) 향상이 한계다. 여기서 핵심 교훈: 공통 경우를 빠르게 만들어라(Make the common case fast).
MIPS의 함정
MIPS(Million Instructions Per Second)는 성능 지표로 부적절하다.
MIPS = Instruction Count / (Execution Time × 10⁶)
= Clock Rate / (CPI × 10⁶)
문제점:
- ISA가 다른 컴퓨터 간 비교 불가 — 명령어의 복잡도가 다르다
- 같은 CPU에서도 프로그램마다 CPI가 달라 MIPS 값이 변한다
- 단순한 명령어를 많이 실행하면 MIPS는 높지만, 실제 작업 효율은 낮을 수 있다
Idle 상태의 전력 오류
SPEC Power 벤치마크 기준:
- 100% 부하: 347W
- 50% 부하: 183W (53%)
- 10% 부하: 115W (33%)
부하가 10%여도 전력 소비는 33%나 된다. 전력 소비가 부하에 비례하지 않는다. Google 데이터센터는 대부분 10~50% 부하로 운영되므로, 부하에 비례하는 전력 소비(power proportional) 설계가 중요하다.
정리
| 개념 | 핵심 |
|---|---|
| 추상화 계층 | HW/SW 복잡성을 계층적으로 분리 |
| ISA | 하드웨어/소프트웨어 경계의 핵심 인터페이스 |
| CPU Time 공식 | 명령어 수 × CPI × Clock Cycle Time |
| 전력 장벽 | 전압·발열 한계로 클럭 속도 증가 불가 |
| 멀티코어 | 전력 장벽의 대안, 병렬 프로그래밍 필요 |
| Amdahl’s Law | 부분 개선의 한계, 공통 경우 최적화가 핵심 |