Threads and Synchronization — 스레드 모델과 레이스 컨디션
지금까지 프로세스는 하나의 실행 흐름만 가진다고 가정했다. 하지만 웹 서버가 클라이언트를 한 명씩만 처리한다면 나머지는 무한정 기다려야 한다. 하나의 프로세스 안에서 여러 실행 흐름을 두는 것 — 그것이 스레드(thread)다.
프로세스와 스레드
프로세스(process)는 두 가지 성격을 동시에 가진다.
- 실행의 단위(unit of execution): OS가 스케줄링하는 대상이며 자신만의 실행 상태(execution state)를 가진다
- 자원 소유의 단위(unit of resource ownership): 메인 메모리, I/O 장치, 페이지 테이블, 열린 파일 같은 자원의 소유권을 가진다
이 두 성격을 분리하는 것이 핵심이다. 실행의 단위를 스레드로, 자원 소유의 단위를 프로세스로 떼어 놓으면, 하나의 프로세스가 여러 실행 흐름을 가질 수 있다.
멀티스레딩(multithreading)은 하나의 프로세스가 그 안에서 여러 실행 흐름을 갖는 능력이다. 대부분의 현대 OS가 멀티스레딩을 지원한다(TinyOS, FreeRTOS 같은 일부 경량 OS 제외).
- 메인 스레드(main thread): 프로세스가 시작될 때 생성되는 최초의 실행 흐름
- 피어 스레드(peer thread): 메인 스레드가 추가로 만든 스레드
여기서 중요한 것은 무엇을 공유하고 무엇을 따로 갖는가이다.
| 영역 | 스레드 간 | 비고 |
|---|---|---|
| Code, Data, Heap | 공유 | 전역 변수, 동적 할당 메모리, 열린 파일 |
| Stack | 개별 | 스레드마다 자신의 실행 스택 |
| 레지스터, PC | 개별 | 스레드마다 독립적인 실행 상태 |
스레드는 같은 프로세스 안의 다른 스레드와 자원을 공유한다. 이 공유가 멀티스레딩의 강점이자, 동시에 레이스 컨디션(race condition)의 출발점이다.
동시성과 병렬성
두 개념은 자주 혼동되지만 다르다.
- 동시성(concurrency): 여러 스레드가 논리적으로 동시에 진행되는 것. 명령 실행이 시간상 인터리빙(interleaving)되거나 겹치면(overlap) 동시적이다. 단일 코어에서도 가능하다.
- 병렬성(parallelism): 여러 스레드가 물리적으로 동시에 실행되는 것. 서로 다른 프로세서나 코어에서 실제로 같은 시각에 진행된다. 멀티 코어가 필수다.
포함 관계로 보면 $\text{Parallelism} \subset \text{Concurrency}$ 다. 즉 병렬성 없는 동시성은 가능하지만, 그 반대는 성립하지 않는다. 단일 코어에서 스레드를 번갈아 실행하면 동시적이지만 병렬적이지는 않다.
정도(degree)를 따로 정의한다.
- 동시성의 정도(degree of concurrency): 동시에 실행될 수 있는 스레드 수
- 병렬성의 정도(degree of parallelism): 병렬로 실행될 수 있는 스레드 수
예를 들어 CPU 4개에서 스레드 6개를 돌리면, 병렬성의 정도는 4(물리적 코어 수에 묶인다), 동시성의 정도는 6이다.
병렬성은 다시 둘로 나뉜다.
- 데이터 병렬성(data parallelism): 같은 연산을 서로 다른 데이터에 나눠 각 코어에서 실행
- 태스크 병렬성(task parallelism): 서로 다른 연산을 각 코어에 분배. 서로 다른 스레드가 같은 데이터를 다룰 수도 있다
멀티스레딩은 왜 필요한가
전형적인 단일 스레드 서버를 보자.
void main() {
...
while(1) {
int sock = accept();
service(sock); // 한 번에 한 클라이언트만 처리
// 길게 걸리는 작업이면 다른 클라이언트는 계속 대기
}
}
클라이언트 N개가 동시에 접속해도 한 번에 하나밖에 처리하지 못한다. 해결책은 두 가지다.
멀티 프로세싱(multi-processing): 요청마다 fork()로 새 프로세스를 만든다. 단순하지만 PCB 전체를 새로 만들어야 해서 무겁고 느리다.
while(1) {
int sock = accept();
if ((pid = fork()) == 0) {
// 자식 프로세스가 요청 처리
}
}
멀티 스레딩(multi-threading): 요청마다 프로세스가 아니라 스레드를 만들고, 곧바로 다음 요청을 받는다. 자원 공유가 쉽고 생성 비용이 작다. 현대 서버는 스레드를 미리 만들어 두는 스레드 풀(thread pool) 구조를 쓴다.
void *mythread(void *arg) { ... }
void main() {
while(1) {
int sock = accept();
create_thread(mythread); // 자식 스레드가 요청 처리
}
}
멀티스레딩의 이점
빠른 응답성(responsiveness): 프로그램의 일부가 블록되거나 긴 작업 중이어도 다른 부분이 계속 실행될 수 있다. RPC(Remote Procedure Call, 다른 머신의 함수를 네트워크로 호출)를 예로 들면, 단일 스레드는 각 서버 응답을 순차적으로 기다리지만, 멀티 스레드는 두 응답을 동시에 기다린다.
효율적인 생성과 자원 공유: 스레드 생성은 PCB 전체가 아니라 TCB(Thread Control Block)와 스택만 추가하면 된다. 프로세스 간 통신은 커널이 개입해 보호·통신 메커니즘을 제공해야 하고(모드 스위치 발생), 자원 공유도 shm_open() 같은 공유 메모리 기법을 프로그래머가 명시적으로 설정해야 한다. 반면 스레드는 전역 변수와 열린 파일을 그냥 공유한다. 단, 공유에는 반드시 동기화 기법을 함께 고려해야 한다.
병렬 처리: 스레드는 여러 작업을 동시에 실행해 병렬성의 정도를 높인다. 멀티 코어 아키텍처에서 그 이점이 더 커진다.
암달의 법칙
병렬화로 얻는 속도 향상에는 한계가 있다. 프로그램에는 반드시 순차적으로 실행해야 하는 부분(serial component)이 있기 때문이다.
\[\text{Speedup} = \frac{\text{단일 프로세서 실행 시간}}{N \text{개 병렬 프로세서 실행 시간}} \leq \frac{1}{S + \frac{1-S}{N}}\]여기서 $S$는 순차적으로 실행되어야 하는 비율, $N$은 프로세서(코어) 수다. $S = 0$인 이상적인 경우에만 속도 향상이 $1/(1/N) = N$에 도달한다. 순차 비율이 조금만 있어도(2%, 5%, 10%) 코어를 늘려도 속도 향상은 금세 정체된다.
실제 측정에서도 스레드 수를 무한정 늘린다고 좋아지지 않는다. 행렬 곱셈과 FFT를 측정하면, 프로세서 수를 넘어서는 지점부터 스레드 간 컨텍스트 스위칭 오버헤드가 커져 오히려 속도 향상이 떨어진다.
멀티스레드 프로세스 모델
스레드를 두려면 무엇이 필요한가. 먼저 스레드마다 독립된 실행 스택이 필요하다. Code/Data/Heap은 공유하지만 Stack은 스레드별로 따로 둔다.
스택만으로는 부족하다. 스레드의 실행 상태를 저장할 TCB(Thread Control Block)가 필요하다. TCB는 스레드의 상태, 프로그램 카운터, 레지스터, 스케줄링 정보를 담는다.
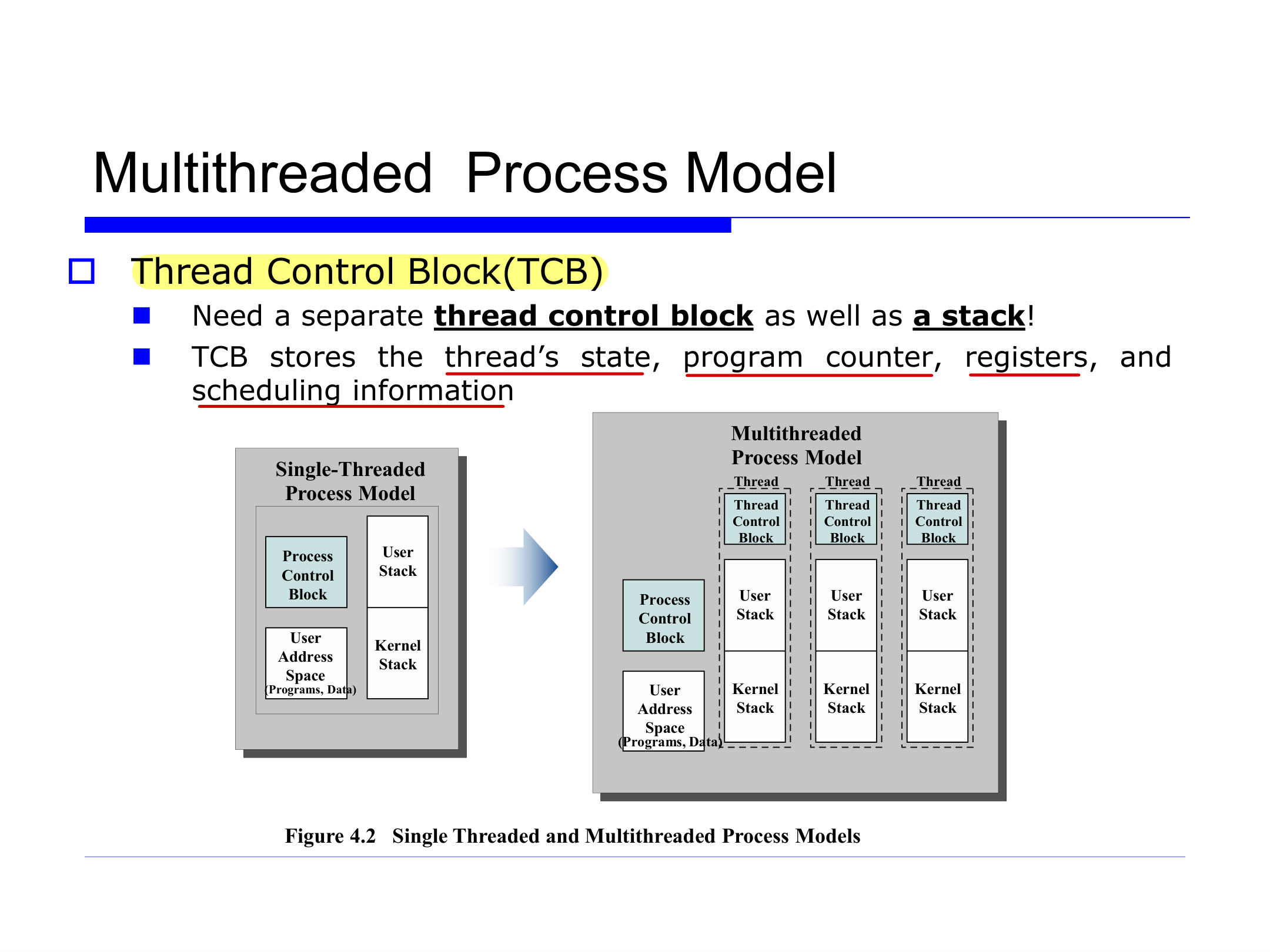
단일 스레드 모델에서는 PCB 하나, User Stack 하나, Kernel Stack 하나가 프로세스에 묶여 있다. 멀티스레드 모델에서는 PCB와 User Address Space(Code/Data)는 프로세스가 공유하고, TCB·User Stack·Kernel Stack은 스레드마다 따로 가진다.
이 때문에 스레드 생성은 프로세스 생성보다 훨씬 가볍다.
| 구분 | 생성 방식 | 비용 |
|---|---|---|
| Heavyweight process | fork() (Code/Data/Heap/Stack/PCB 전부 복사) |
큼 |
| Lightweight process(스레드) | pthread_create() (Stack + TCB만 추가) |
작음 |
스레드를 경량 프로세스(LWP, Lightweight Process)라고도 부른다. 같은 프로세스 내 스레드 간 전환은 프로세스 간 전환보다 성능이 좋다. 주소 공간을 공유하므로 캐시 히트율도 높다.
스레드 구현 모델
스레드 구현은 스레드 관리를 어디서 하는가에 따라 크게 세 가지로 나뉜다.
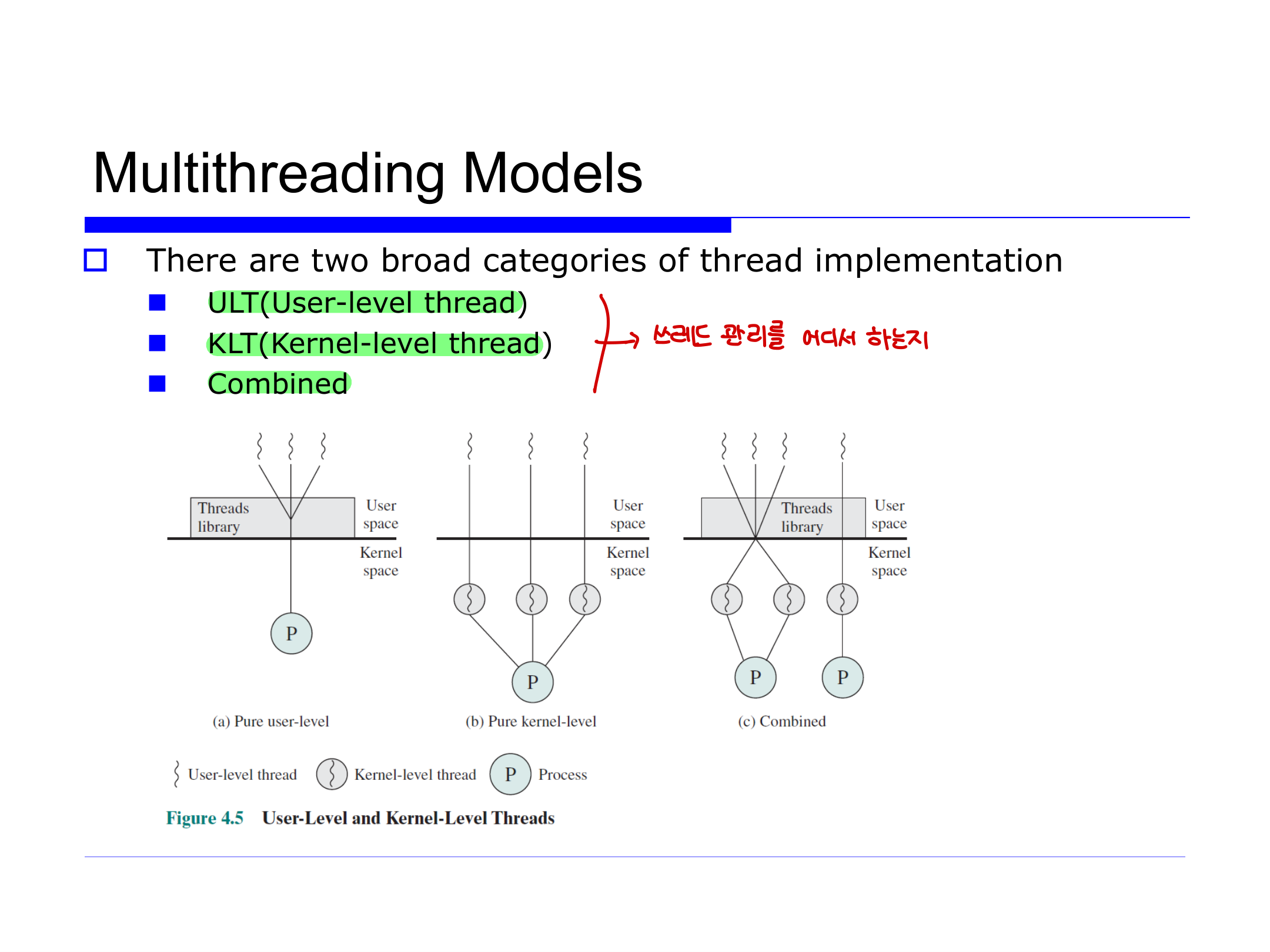
커널 레벨 스레드 (KLT)
순수 KLT에서는 스레드 관리의 모든 작업을 커널이 한다.
- 커널이 스레드마다 TCB를 직접 유지한다
- 스레드 1개 = 커널 스케줄링 단위 1개 (1:1 매핑)
- Windows NT, Linux Thread, POSIX Pthreads가 예시다
장점:
- 멀티프로세서에서 병렬성을 활용한다. 커널이 모든 스레드를 알기 때문에 각 코어에 분산할 수 있다
- 한 스레드가 I/O로 블록되어도 다른 스레드를 실행할 수 있어 CPU 활용도가 좋다
단점:
- 생성·종료·전환 비용이 ULT보다 크다. 스레드 전환 시 반드시 커널로의 모드 스위치(mode switch)가 발생한다
연산별 지연 시간을 비교하면 차이가 분명하다.
| Operation | User-Level Threads | Kernel-Level Threads | Processes |
|---|---|---|---|
| Null Fork (생성 비용) | $34\ \mu s$ | $948\ \mu s$ | $11{,}300\ \mu s$ |
| Signal Wait (동기화 비용) | $37\ \mu s$ | $441\ \mu s$ | $1{,}840\ \mu s$ |
ULT는 커널 개입 없이 유저 공간에서만 처리해 가장 빠르고, KLT는 전환마다 모드 스위치가 발생해 느리며, 프로세스는 PCB 생성·복사에 모드 스위치까지 겹쳐 가장 느리다.
유저 레벨 스레드 (ULT)
순수 ULT에서는 모든 스레드 관리를 스레드 라이브러리가 유저 공간에서 한다. 스레드 생성·소멸, 스케줄링, 컨텍스트 저장·복원을 라이브러리가 담당하고, 제어는 프로시저 호출로 넘어간다. 커널은 개입하지 않는다. 초기 Java의 그린 스레드(green thread), GNU Pth가 예시다.
장점:
- 빠른 컨텍스트 스위칭: 스레드 전환에 커널이 개입하지 않는다
- 효율적인 스레드 관리: 라이브러리가 유저 공간에서 직접 처리한다
- 이식성: 어떤 OS에서도 동작한다
단점:
- 멀티 코어를 온전히 활용하지 못한다. 커널은 프로세스를 하나의 스케줄링 단위로 보므로 여러 코어에 분산하지 못한다
- 블로킹 문제(blocking problem): 한 스레드가 블로킹 시스템 콜(예: I/O)을 호출하면 프로세스 전체, 따라서 모든 스레드가 블록된다. 해결책은 블로킹 시스템 콜을 논블로킹으로 변환하는 것이다
스레드 스케줄링: ULT vs KLT
같은 시나리오를 ULT와 KLT로 돌리면 차이가 드러난다. 프로세스 1(스레드 A, B)과 프로세스 2(스레드 C, D)가 있고, A와 C는 15ms 실행 → 15ms I/O 대기 → 5ms 실행, B와 D는 5ms 실행이라 하자. 시간 양자 $q = 10ms$.
ULT: A가 I/O로 블록되면 프로세스 1 전체가 블록된다. 한 스레드의 블로킹 I/O 콜이 프로세스 전체를 멈춰 CPU 자원이 낭비된다(underutilization).
KLT: A가 I/O로 블록되어도 커널이 같은 프로세스의 B나 다른 프로세스의 스레드를 스케줄링할 수 있다. CPU가 놀지 않는다.
Combined ULT/KLT
일부 OS는 둘을 결합한다. 한 애플리케이션의 여러 ULT를 그보다 적거나 같은 수의 KLT에 매핑한다. 프로그래머가 KLT 수를 조절할 수 있다. Solaris가 대표적인 예다.
스레드 API
대표적인 스레드 API는 세 가지다.
| 플랫폼 | 생성 | 종료 |
|---|---|---|
| POSIX (Linux) | pthread_create(f, arg) |
pthread_exit(status) |
| Win32 | CreateThread(f, arg) |
ExitThread(status) |
| Java | t = new MyThread(); t.start() |
run() 종료 |
Pthreads 인터페이스
POSIX Threads(Pthreads)는 스레드를 다루는 약 60개 함수의 표준 인터페이스다. 기본 함수는 다음과 같다.
| 함수 | 역할 |
|---|---|
pthread_create |
자식 스레드 생성 |
pthread_exit |
스레드 종료 |
pthread_join |
스레드 종료 대기 |
pthread_self |
호출 스레드 ID 반환 |
pthread_mutex_lock |
임계 구역 잠금 |
pthread_mutex_unlock |
임계 구역 잠금 해제 |
pthread_cond_wait |
조건 시그널 대기 |
pthread_cond_signal |
대기 스레드 하나 깨움 |
스레드 생성:
#include <pthread.h>
typedef void *(func)(void *);
int pthread_create(pthread_t *tid, pthread_attr_t *attr,
func *f, void *arg);
// Returns: 0 if OK, nonzero on error
f를 새 스레드의 컨텍스트에서 인자 arg로 실행한다. attr로 스케줄링 우선순위 등 기본 속성을 바꿀 수 있다. 반환되면 tid에 새 스레드의 ID가 담긴다.
스레드 수거(reaping):
#include <pthread.h>
int pthread_join(pthread_t tid, void **thread_return);
// Returns: 0 if OK, nonzero on error
pthread_join은 스레드 tid가 종료될 때까지 블록되고, 종료된 스레드가 점유한 메모리 자원을 회수한다. 메인 스레드가 피어 스레드를 기다리는 기본 패턴이다.
간단한 예제. 인자로 받은 수까지 합을 구한다.
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
int sum;
void *runner(void *param);
int main(int argc, char *argv[]) {
pthread_t tid;
int status;
pthread_create(&tid, NULL, runner, argv[1]);
pthread_join(tid, &status); // 스레드 종료 대기
printf("sum = %d, status=%d\n", sum, status);
}
void *runner(void *param) {
int i, upper = atoi(param);
sum = 0;
for (i = 1; i <= upper; i++)
sum += i;
pthread_exit(0);
}
// $ gcc test.c -lpthread
// $ ./a.out 4 → sum = 10
레이스 컨디션
이제 공유의 대가를 본다. 다음은 잘못된 공유(bad sharing) 예제다. 전역 변수 x를 한 스레드는 1000번 증가, 다른 스레드는 1000번 감소시킨다.
int x; // 전역 변수, 두 스레드가 공유
void *thread_increment(void *arg) {
int i, val;
for (i = 0; i < ITER; i++) {
val = x;
x = val + 1;
}
return NULL;
}
void *thread_decrement(void *arg) {
int i, val;
for (i = 0; i < ITER; i++) {
val = x;
x = val - 1;
}
return NULL;
}
직관적으로는 +1을 1000번, -1을 1000번 했으니 x는 0이어야 한다. 그런데 실행하면 BOOM! counter=-84 같은 엉뚱한 값이 나온다. 왜 그런가.
X++는 원자적이지 않다
x++ 한 줄은 CPU 입장에서 한 번에 끝나는 연산이 아니다. 기계어로 풀면 세 단계다.
(1) lw $r0, x // 메모리의 x를 레지스터로 로드
(2) add $r1, $r0, 1 // 레지스터에서 +1
(3) sw x, $r1 // 결과를 메모리의 x로 저장
이 세 단계 사이에 컨텍스트 스위칭이 끼어들 수 있다는 것이 문제의 핵심이다.
단일 프로세서에서의 레이스 컨디션
x의 초기값을 10이라 하자. 스레드 A는 x++, 스레드 B는 x--를 수행한다. 다음 순서로 인터리빙되면:
| 순서 | 동작 | 결과 |
|---|---|---|
| (1) | A: Load X → R | $R = 10$ |
| (2) | A: R ← R + 1 | $R = 11$ |
| (3) | B: Load X → R | $R = 10$ (아직 X는 10) |
| (4) | B: R ← R − 1 | $R = 9$ |
| (5) | B: Store X | $X = 9$ |
| (6) | A: Store X | $X = 11$ |
x++와 x--를 한 번씩 했으니 x는 10이어야 한다. 그런데 결과는 11이다. B가 저장한 9를 A가 11로 덮어썼다. A와 B가 같은 시점의 x = 10을 각자 읽었기 때문에 한쪽의 갱신이 사라졌다(lost update).
멀티 프로세서에서의 레이스 컨디션
여러 CPU가 공유 메모리의 x를 동시에 다루면 같은 문제가 발생한다. CPU0이 x++를, CPU2가 x--를 각자의 로컬 레지스터에서 수행하다가 둘 다 옛 값을 읽고 따로 저장하면, 역시 한쪽 갱신이 사라진다. 공유 변수에 대한 접근이 보호되지 않으면 단일/멀티 프로세서 어디서든 결과가 어긋난다.
이렇게 여러 스레드가 공유 자원에 동시 접근해 실행 순서에 따라 결과가 달라지는 상황을 레이스 컨디션(race condition)이라 한다.
스레드 동기화
스레드는 멀티스레드 프로그램에서 공유 자원에 접근하며 협력한다. 공유 자원에 동시 접근하면 잘못된 결과가 나오고 — 그것이 레이스 컨디션이다.
스레드 동기화(thread synchronization)는 공유 자원을 쓰거나 실행 순서를 맞춰야 하는 스레드들을 올바르게 협력하도록 조율하는 방법이다. 목표는 협력하는 스레드의 정확한 동작을 보장하는 것이다.
x++가 원자적이지 않다는 것이 문제의 뿌리였다. 그렇다면 세 단계를 쪼개지 못하게 묶거나, 한 번에 한 스레드만 공유 자원에 들어가게 막아야 한다. 그 구체적인 메커니즘 — 임계 구역(critical section), 뮤텍스(mutex), 세마포어(semaphore) — 가 다음 주제다.