Data Abstraction and Basic Data Structures — 추상 자료형과 기본 자료구조
알고리즘을 설계하려면 데이터를 어떤 구조로 저장하고 접근할지 먼저 결정해야 한다. 구체적인 구현이 아니라 연산과 명세 수준에서 자료구조를 정의하는 것이 추상 자료형이다.
추상 자료형 (Abstract Data Type)
추상 자료형(ADT)은 데이터와 그 데이터에 적용할 수 있는 연산을 구현과 독립적으로 정의한 것이다. 구현 세부사항이나 성능은 ADT의 관심사가 아니다.
ADT는 두 가지로 구성된다:
- Structures: 자료구조 선언 (어떤 데이터를 저장하는가)
- Functions: 연산 정의 (어떤 작업을 수행하는가)
C++이나 Java에서 ADT는 클래스(Class)로 구현된다. Structures는 멤버 변수, Functions는 멤버 함수에 대응한다.
알고리즘의 설계와 정확성 증명은 ADT의 연산과 명세에 기반한다. 특정 구현에 의존하지 않기 때문에, 같은 ADT를 다양한 방식으로 구현할 수 있고 알고리즘은 그대로 유효하다.
트리 (Tree)
계층적 관계를 표현하는 대표적인 비선형 자료구조다. 파일 시스템, 조직도, 수식 파싱 등 다양한 곳에서 사용된다.
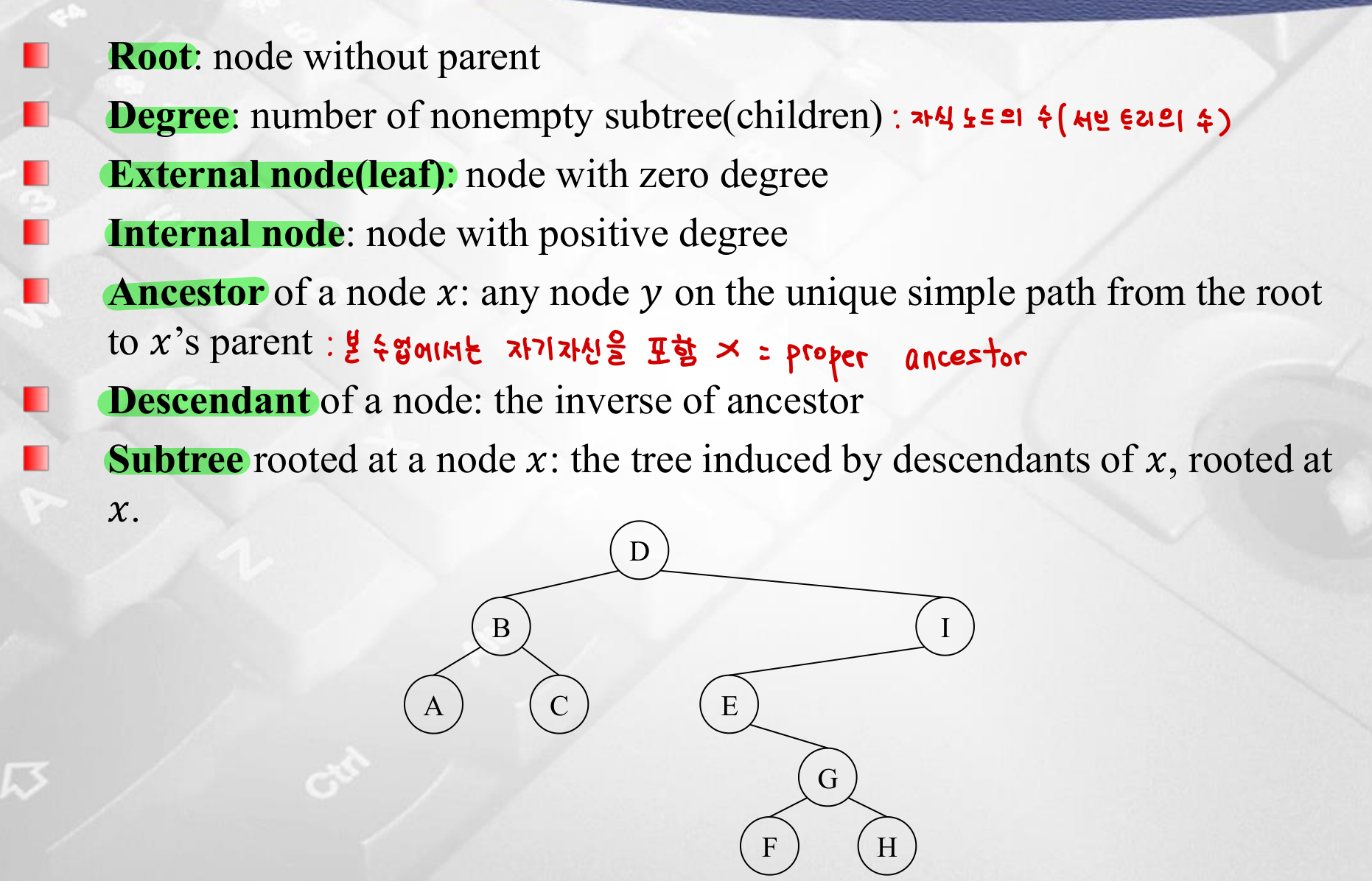
트리 용어
| 용어 | 정의 |
|---|---|
| 루트(Root) | 부모가 없는 노드 |
| 차수(Degree) | 한 노드의 자식 노드(비어 있지 않은 서브트리) 수 |
| 외부 노드(External Node, Leaf) | 차수가 0인 노드 |
| 내부 노드(Internal Node) | 차수가 1 이상인 노드 |
| 조상(Ancestor) | 루트에서 해당 노드까지의 경로에 있는 모든 노드. 자기 자신을 포함하지 않으면 proper ancestor |
| 자손(Descendant) | 조상의 역관계 |
| 서브트리(Subtree) | 노드 $x$와 $x$의 모든 자손으로 구성된 트리 |
깊이, 레벨, 높이
- 깊이(Depth): 루트의 깊이는 0이다. 다른 노드의 깊이는 부모의 깊이 + 1이다
- 레벨(Level): 같은 깊이에 있는 모든 노드의 집합이다
- 높이(Height): 트리의 높이는 리프 노드 중 가장 큰 깊이 값이다. 임의의 노드의 높이는 그 노드를 루트로 하는 서브트리의 높이이다

위 트리에서 루트 D의 깊이는 0, 높이는 4이다. 노드 E의 깊이는 2, 높이는 2이다.
이진 트리 (Binary Tree)
이진 트리 $T$는 노드의 집합으로, 공집합이거나 다음을 만족한다:
- 루트(root)라 불리는 특별한 노드 $r$이 존재한다
- 나머지 노드는 두 개의 서로소 부분집합 $L$, $R$로 나뉘며, 각각이 이진 트리이다. $L$은 $T$의 왼쪽 서브트리, $R$은 오른쪽 서브트리이다
핵심은 각 노드의 자식이 최대 2개라는 점이다. 일반 트리와 달리 왼쪽/오른쪽이 구분된다.
이진 트리의 성질
| 성질 | 설명 |
|---|---|
| 깊이 $d$에서 최대 노드 수 | $2^d$ |
| 높이 $h$인 이진 트리의 최대 노드 수 | $2^{h+1} - 1$ |
| $n$개 노드를 가진 이진 트리의 최소 높이 | $\lceil \log(n+1) \rceil - 1$ |
첫 번째 성질은 각 깊이에서 노드가 최대 2배씩 늘어나기 때문이다. 두 번째는 모든 깊이가 꽉 찬 포화 이진 트리(Full Binary Tree)의 경우이며, 등비급수의 합 $\sum_{i=0}^{h} 2^i = 2^{h+1} - 1$로 유도된다. 세 번째는 두 번째의 역이다.
스택 (Stack)
스택(Stack)은 삽입과 삭제가 한쪽 끝(top)에서만 이루어지는 선형 자료구조다. LIFO(Last In, First Out) 정책을 따른다. 마지막에 들어간 원소가 가장 먼저 나온다.
주요 연산:
| 연산 | 설명 |
|---|---|
push(e) |
top에 원소 $e$를 삽입 |
pop() |
top의 원소를 제거하고 반환 |
함수 호출 스택, 괄호 매칭, DFS 등에서 사용된다.
큐 (Queue)
큐(Queue)는 삽입은 한쪽 끝(rear/back)에서, 삭제는 반대쪽 끝(front)에서 이루어지는 선형 자료구조다. FIFO(First In, First Out) 정책을 따른다. 먼저 들어간 원소가 먼저 나온다.
주요 연산:
| 연산 | 설명 |
|---|---|
enqueue(e) |
rear에 원소 $e$를 삽입 |
dequeue() |
front의 원소를 제거하고 반환 |
BFS, 작업 스케줄링, 버퍼 등에서 사용된다.
우선순위 큐 (Priority Queue)
우선순위 큐(Priority Queue)는 FIFO 큐와 유사하지만, 원소의 순서가 도착 시간이 아닌 우선순위(priority)에 의해 결정된다. 꺼낼 수 있는 원소는 현재 큐에서 가장 중요한(우선순위가 높은) 원소이다.
관점에 따라 두 가지로 나뉜다:
- 비용 관점(cost viewpoint): 우선순위가 가장 작은 원소를 먼저 꺼낸다 → Min-Priority Queue
- 이익 관점(profit viewpoint): 우선순위가 가장 큰 원소를 먼저 꺼낸다 → Max-Priority Queue
구현별 시간 복잡도 비교
| 연산 | 비정렬 시퀀스 | 정렬 시퀀스 | 이진 힙 |
|---|---|---|---|
insert() |
$O(1)$ | $O(n)$ | $O(\log n)$ |
removeMin() |
$O(n)$ | $O(1)$ | $O(\log n)$ |
getMin() |
$O(n)$ | $O(1)$ | $O(1)$ |
비정렬 시퀀스는 삽입이 빠르지만 최솟값을 찾으려면 전체를 탐색해야 한다. 정렬 시퀀스는 반대다. 이진 힙(Binary Heap)은 삽입과 삭제 모두 $O(\log n)$으로, 두 연산 간 균형을 이룬다.
Union-Find (서로소 집합)
Union-Find는 서로소 집합(Disjoint Sets)을 관리하는 ADT다. 비방향 그래프(Undirected Graph)에서 연결 요소(Connected Component)를 찾는 문제 등에 활용된다.
각 집합은 고유한 set id로 구별되며, 이 set id는 집합 내 특정 원소인 대표(leader, representative)가 된다.
연산
| 연산 | 설명 |
|---|---|
create(n) |
$n$개의 싱글턴 서로소 집합 ${1}, {2}, \ldots, {n}$을 생성 |
find(sets, e) |
원소 $e$가 속한 집합의 set id를 반환 |
makeSet(sets, e) |
싱글턴 집합 ${e}$를 생성하여 기존 집합에 추가 ($e$는 기존에 없는 원소) |
union(sets, s, t) |
set id가 $s$인 집합과 $t$인 집합을 합친다. 새 set id는 $s$ 또는 $t$ (경우에 따라 $\min(s, t)$) |
union 연산에서 두 set id $s$와 $t$는 반드시 서로 달라야 한다. 합쳐진 집합의 새 set id는 둘 중 하나가 된다.
딕셔너리 (Dictionary)
딕셔너리(Dictionary)는 키(key)와 값(value = element)의 쌍 $\langle key, value \rangle$을 저장하는 연관 저장 구조(associative storage structure)이다. 키 간에 순서가 정의되지 않는다는 점이 특징이다.
주요 구현 방법으로 해싱(Hashing)과 이진 탐색 트리(Binary Search Tree)가 있다. 해싱은 평균 $O(1)$ 접근을 제공하고, 이진 탐색 트리는 키의 순서를 유지하면서 $O(\log n)$ 접근을 보장한다. 문제의 요구사항에 따라 적절한 구현을 선택한다.