Memory Hierarchy and Caches — 지역성부터 캐시 사상·성능·가상 메모리까지
메모리는 빠를수록 비싸고, 클수록 느리다. 이상적인 메모리는 SRAM의 접근 속도에 디스크의 용량과 단가를 갖지만 그런 물건은 존재하지 않는다. 이 모순을 정면으로 깨는 대신 여러 종류의 메모리를 계층으로 쌓아 빠른 메모리처럼 보이게 속이는 것이 메모리 계층(memory hierarchy)의 발상이다.
메모리 기술과 계층의 동기
메모리 소자는 속도-가격 축에서 줄을 세울 수 있다.
| 기술 | 접근 속도 | 단가 |
|---|---|---|
| SRAM (Static RAM) | 가장 빠름 | 가장 비쌈 |
| DRAM (Dynamic RAM) | SRAM보다 느림 | SRAM보다 쌈 |
| 자기 디스크(Magnetic disk) | DRAM보다 느림 | 가장 쌈 |
원하는 것은 SRAM의 속도 + 디스크의 용량/단가다. 둘 다 가진 단일 소자는 없으므로, 자주 쓰는 데이터는 빠르고 작은 메모리에, 나머지는 느리고 큰 메모리에 두고 필요할 때 끌어올린다.
이 전략이 통하는 근거가 지역성의 원리(principle of locality)다. 프로그램은 임의의 순간에 자기 주소 공간의 작은 일부만 접근한다.
- 시간 지역성(temporal locality): 최근 접근한 항목은 곧 다시 접근될 가능성이 높다. 예: 루프 안의 명령어.
- 공간 지역성(spatial locality): 최근 접근한 항목 근처는 곧 접근될 가능성이 높다. 예: 순차적 명령어 실행, 배열 데이터.
자주 쓰는 작은 영역만 빠른 메모리에 올려두면 대부분의 접근이 빠른 메모리에서 끝난다. 계층이 동작하는 이유가 여기에 있다.
계층의 동작과 용어
데이터를 계층 간에 옮기는 단위를 블록(block) 또는 라인(line)이라 한다. 한 블록은 여러 워드일 수 있다.
CPU가 어떤 데이터를 요청했을 때:
- 적중(hit): 데이터가 상위 계층에 있어 바로 처리된다. 전체 접근 중 적중 비율이 적중률(hit ratio)이다.
- 실패(miss): 데이터가 없어서 하위 계층에서 블록을 복사해 온다. 이때 걸리는 시간이 실패 페널티(miss penalty)다. 실패율(miss ratio)은 $1 - \text{hit ratio}$이고, 블록을 올린 뒤 상위 계층에서 데이터를 공급한다.
가장 위, CPU에 가장 가까운 계층이 캐시 메모리(cache memory)다. 여기서 두 가지 질문이 생긴다. 데이터가 캐시에 있는지 어떻게 아는가. 있다면 어디를 봐야 하는가. 이 질문의 답이 캐시 사상(mapping) 방식이다.
직접 사상 캐시 (Direct Mapped Cache)
가장 단순한 답은 각 메모리 블록이 들어갈 캐시 위치를 주소로 딱 하나 정하는 것이다. 위치는 다음으로 결정된다.
\[\text{Cache index} = (\text{Block address}) \bmod (\text{캐시의 블록 수})\]캐시 블록 수가 2의 거듭제곱이면 modulo 연산은 주소의 하위 비트(low-order bits)를 그대로 인덱스로 쓰는 것과 같다.
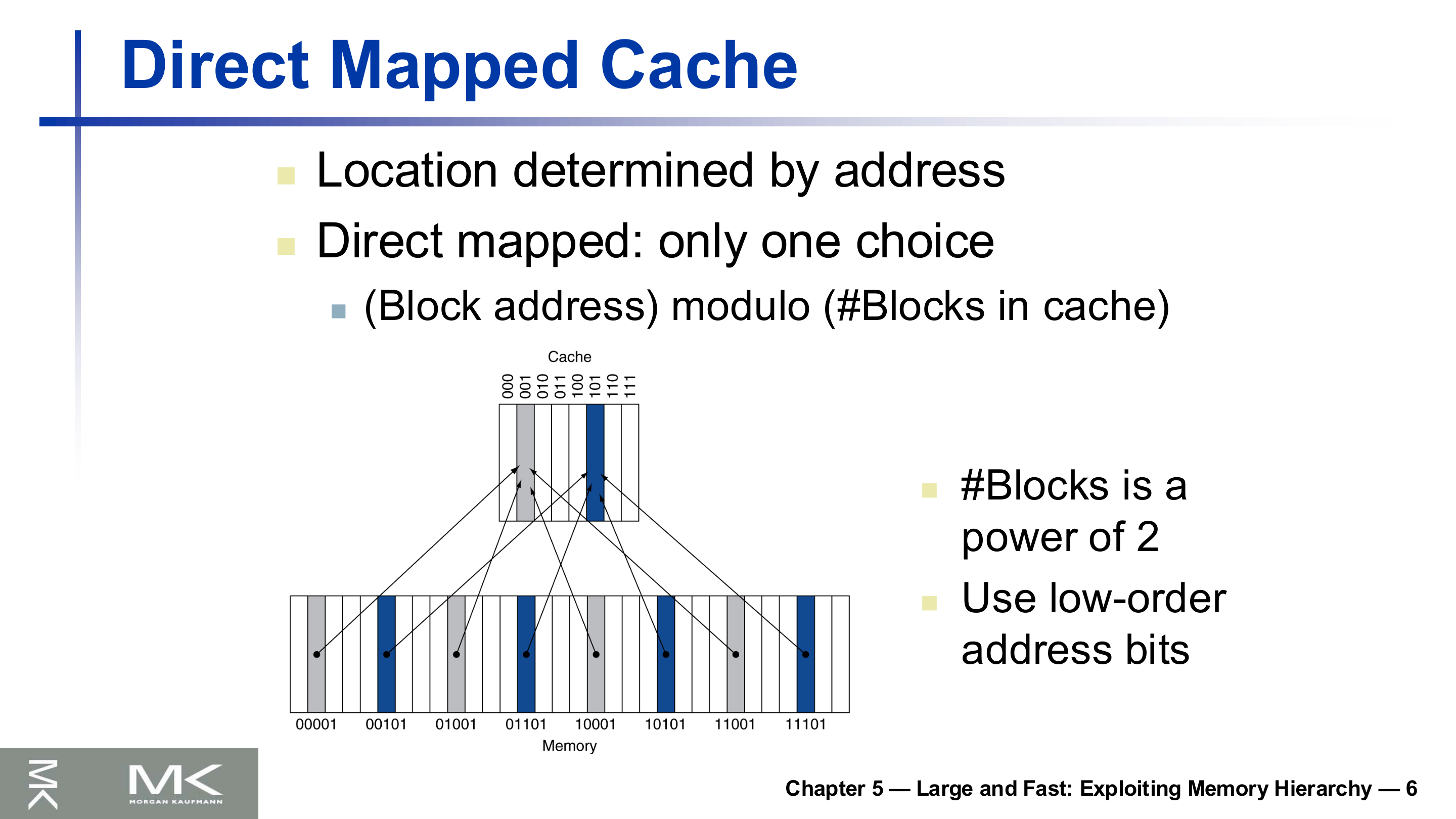
위 그림에서 메모리 블록 00001, 01001, 10001, 11001은 모두 하위 3비트가 001이라 같은 캐시 슬롯으로 사상된다. 즉 여러 블록이 한 자리를 두고 경쟁한다.
태그와 유효 비트
한 캐시 위치에 들어올 수 있는 블록이 여럿이므로, 지금 들어있는 게 어떤 블록인지 구분해야 한다.
- 태그(tag): 블록 주소에서 인덱스로 쓰지 않은 상위 비트. 캐시에 데이터와 함께 저장해 두고 비교한다.
- 유효 비트(valid bit): 그 자리에 의미 있는 데이터가 있는지 표시한다.
1이면 present,0이면 비어 있음. 초기값은0이다.
동작 예시
8블록, 1워드/블록 직접 사상 캐시를 빈 상태에서 시작해 워드 주소를 차례로 접근한다고 하자. 주소의 하위 3비트가 인덱스, 상위 2비트가 태그다.
| 워드 주소 | 2진 주소 | 인덱스 | 태그 | 결과 |
|---|---|---|---|---|
| 22 | 10 110 |
110 | 10 | Miss → 적재 |
| 26 | 11 010 |
010 | 11 | Miss → 적재 |
| 22 | 10 110 |
110 | 10 | Hit |
| 26 | 11 010 |
010 | 11 | Hit |
| 16 | 10 000 |
000 | 10 | Miss → 적재 |
| 3 | 00 011 |
011 | 00 | Miss → 적재 |
| 16 | 10 000 |
000 | 10 | Hit |
| 18 | 10 010 |
010 | 10 | Miss → 교체 |
마지막 접근이 핵심이다. 주소 18(10 010)은 인덱스 010으로 가는데, 그 자리에는 이미 주소 26(11 010, 태그 11)이 있다. 태그가 10과 11로 다르므로 실패가 나고, 기존 블록을 쫓아내고 새 블록을 채운다. 직접 사상에서는 선택지가 없으므로 무조건 그 자리를 덮어쓴다.
주소의 분할
블록이 여러 바이트/워드를 담으면 주소는 여러 필드로 나뉜다. 1워드(4바이트) 블록이면 하위 2비트는 워드 안에서 바이트를 고르는 바이트 오프셋(byte offset)이고, 그 위가 인덱스, 나머지 상위가 태그다.
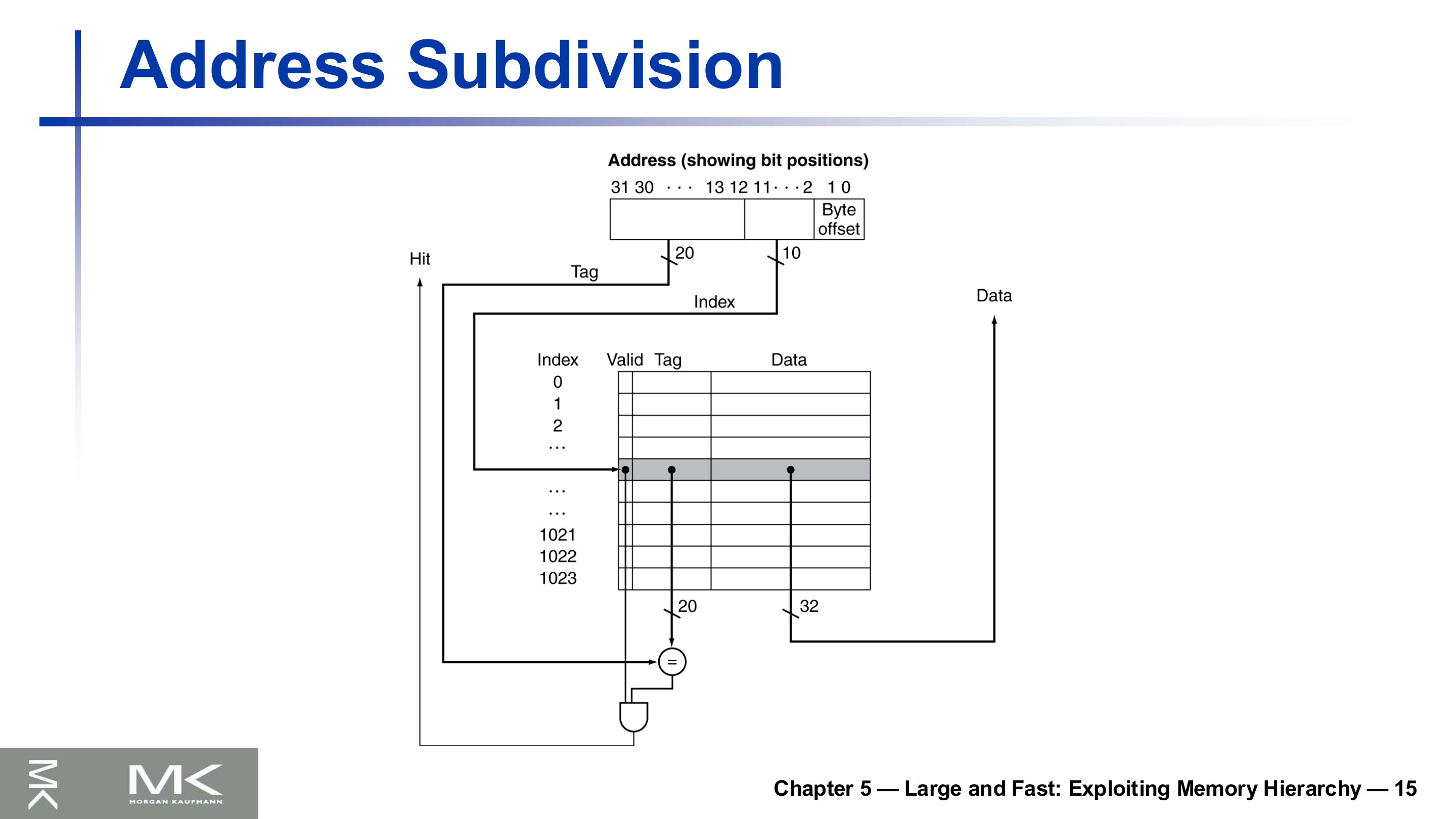
위는 1024(=$2^{10}$)개 엔트리, 1워드 블록인 캐시다. 32비트 주소에서 하위 2비트는 바이트 오프셋, 다음 10비트는 인덱스(어느 줄을 볼지), 상위 20비트는 태그다. 인덱스로 한 줄을 고른 뒤, 그 줄의 태그와 주소의 태그가 같고 유효 비트가 1이면 적중이다. 이 둘을 AND로 묶은 것이 최종 Hit 신호다.
블록이 여러 워드면 인덱스와 바이트 오프셋 사이에 블록 오프셋(block offset)이 추가되어 블록 안의 어느 워드인지 고른다.
블록 크기와 실패율
블록을 키우면 한 번 실패할 때 주변 데이터까지 함께 끌어와 공간 지역성을 더 활용한다. 그래서 처음에는 실패율이 떨어진다. 하지만 블록을 무한정 키울 수는 없다.
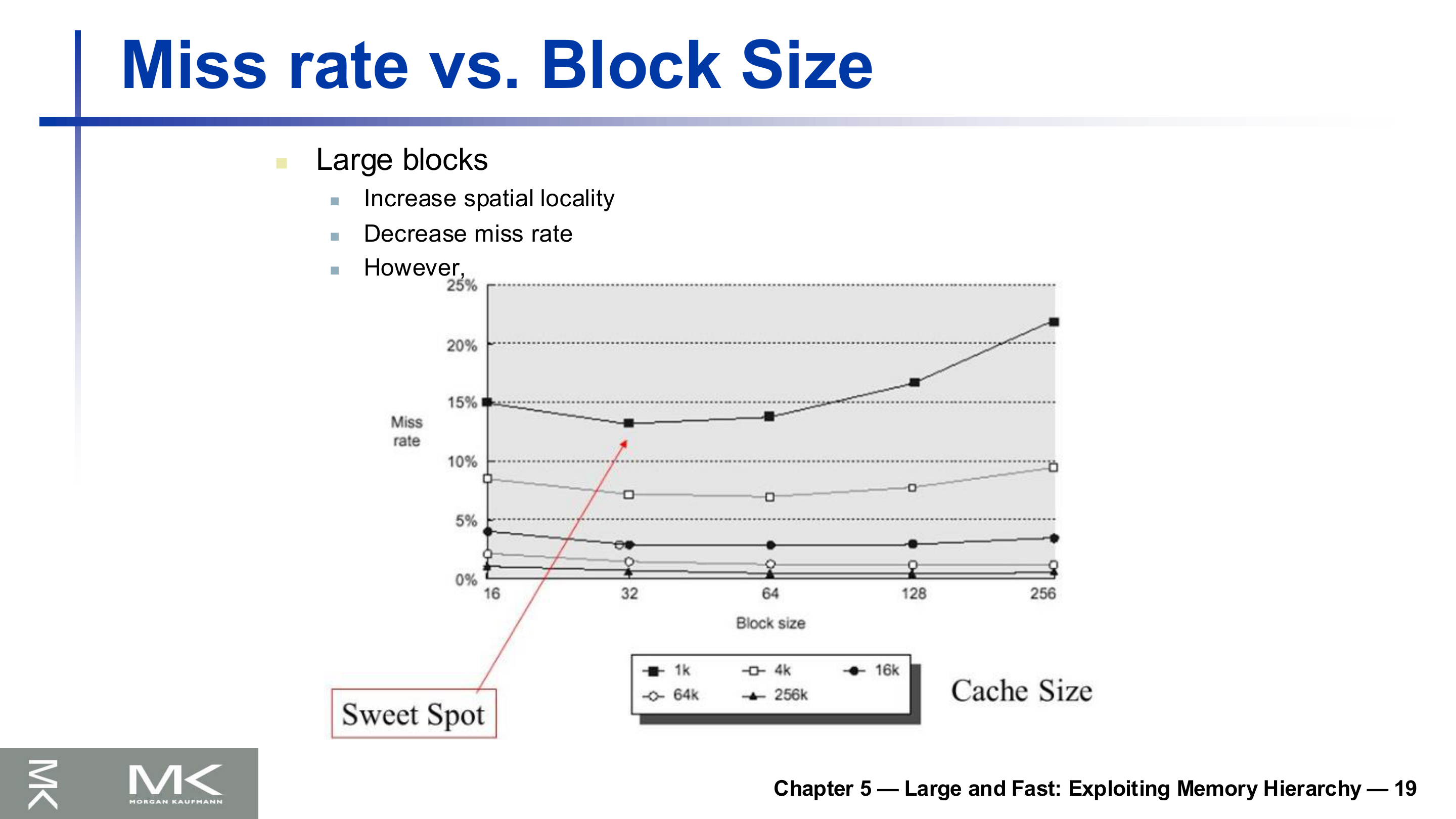
캐시 전체 크기가 고정된 상태에서 블록을 너무 키우면 캐시에 담기는 블록 수가 줄어, 서로 다른 데이터가 같은 슬롯을 두고 다투는 경쟁이 심해진다(오염, pollution). 그 결과 어느 지점을 지나면 실패율이 다시 올라간다. 그래프의 최저점이 sweet spot이다. 게다가 블록이 크면 실패 시 옮길 데이터가 많아 실패 페널티도 커진다.
쓰기 정책
읽기는 캐시 내용을 바꾸지 않지만, 쓰기는 캐시와 메모리의 내용을 어긋나게(inconsistent) 만들 수 있다. 두 가지 정책이 있다.
쓰기 통과(Write-through): 캐시에 쓸 때 메모리에도 동시에 쓴다. 항상 일관되지만 매 쓰기가 느린 메모리 접근을 동반한다. 해결책은 쓰기 버퍼(write buffer)다. 메모리에 쓸 데이터를 버퍼에 넣어두면 CPU는 즉시 다음 일을 진행하고, 버퍼가 가득 찰 때만 멈춘다.
쓰기 후 기록(Write-back): 쓰기 적중 시 캐시 블록만 갱신하고 더티 비트(dirty bit)를 세운다. 메모리 갱신은 미룬다. 더티 블록이 교체될 때 비로소 메모리에 기록한다. 이때도 쓰기 버퍼를 쓰면 들어올 블록을 먼저 읽고 쫓겨나는 블록은 나중에 써넣을 수 있다.
캐시 성능 측정
CPU 시간은 실행 사이클과 메모리 지연(stall) 사이클로 나뉜다.
\[\text{CPU time} = (\text{CPU 실행 사이클} + \text{메모리 stall 사이클}) \times \text{클럭 주기}\]메모리 stall 사이클은 주로 캐시 실패에서 온다.
\[\text{Memory stall cycles} = \frac{\text{Memory accesses}}{\text{Program}} \times \text{Miss rate} \times \text{Miss penalty}\]명령어 기준으로 다시 쓰면 다음과 같다.
\[= \frac{\text{Instructions}}{\text{Program}} \times \frac{\text{Misses}}{\text{Instruction}} \times \text{Miss penalty}\]여기서 중요한 경향이 나온다. CPU가 빨라지거나(base CPI 감소), 클럭이 올라갈수록 실패 페널티가 전체 성능에서 차지하는 비중이 커진다. 같은 실패 페널티라도 빠른 CPU에서는 더 많은 사이클을 까먹기 때문이다. 그래서 시스템 성능을 평가할 때 캐시 동작을 무시할 수 없다.
연관 사상 (Associative Cache)
직접 사상의 약점은 한 블록이 갈 자리가 하나뿐이라는 점이다. 서로 다른 블록이 같은 인덱스로 몰리면 캐시에 빈 자리가 남아도 계속 충돌한다. 이를 완화하는 것이 연관 사상이다.
- 완전 연관(fully associative): 블록이 캐시의 아무 자리에나 들어갈 수 있다. 찾을 때는 모든 엔트리를 동시에 비교해야 하므로 엔트리마다 비교기가 필요해 비싸다.
- n-way 집합 연관(set associative): 캐시를 여러 집합(set)으로 나누고, 각 집합에 $n$개의 엔트리를 둔다. 블록이 갈 집합은 정해지지만 집합 안에서는 어느 자리든 가능하다.
집합 안의 $n$개만 동시에 비교하면 되므로 비교기가 $n$개로 줄어 완전 연관보다 싸다.
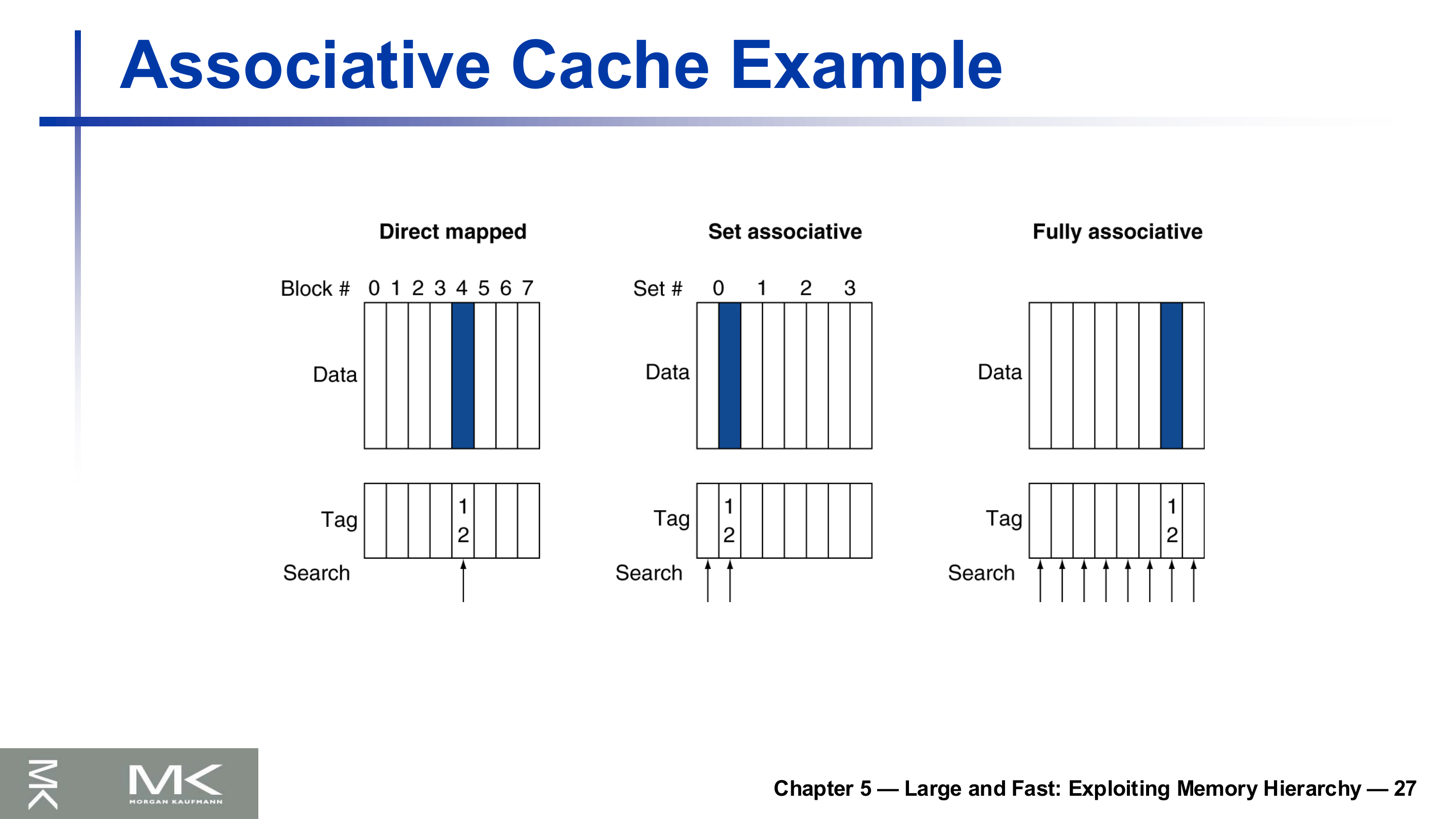
같은 블록을 찾을 때, 직접 사상은 한 곳만, 집합 연관은 한 집합 안만, 완전 연관은 전체를 탐색한다. 직접 사상은 1-way 집합 연관, 완전 연관은 (엔트리 수)-way 집합 연관으로 볼 수 있다. 즉 세 방식은 연속된 스펙트럼의 양 끝과 중간이다.
충돌 실패 비교
블록 접근 순서가 0, 4, 0, 4, ...이고, 4블록 캐시에서 블록 0과 4가 같은 자리(또는 같은 집합)로 사상된다고 하자.
- 직접 사상: 0과 4가 같은 슬롯을 두고 매번 서로를 쫓아낸다. 8번 요청에 8번 실패.
- 2-way 집합 연관: 0과 4가 같은 집합 안의 서로 다른 두 자리에 공존한다. 8번 요청에 2번 실패(처음 두 번의 강제 실패뿐).
빈 공간이 있는데도 자리 경쟁으로 발생하는 이런 실패를 충돌 실패(conflict miss)라 한다. 연관도를 높이면 충돌 실패가 줄어든다. 다만 효과는 체감한다 — 64KB 데이터 캐시, 16워드 블록 기준 시뮬레이션에서 실패율은 1-way 10.3% → 2-way 8.6% → 4-way 8.3% → 8-way 8.1%로, 연관도를 올릴수록 개선폭이 작아진다.
집합 연관 캐시의 구조
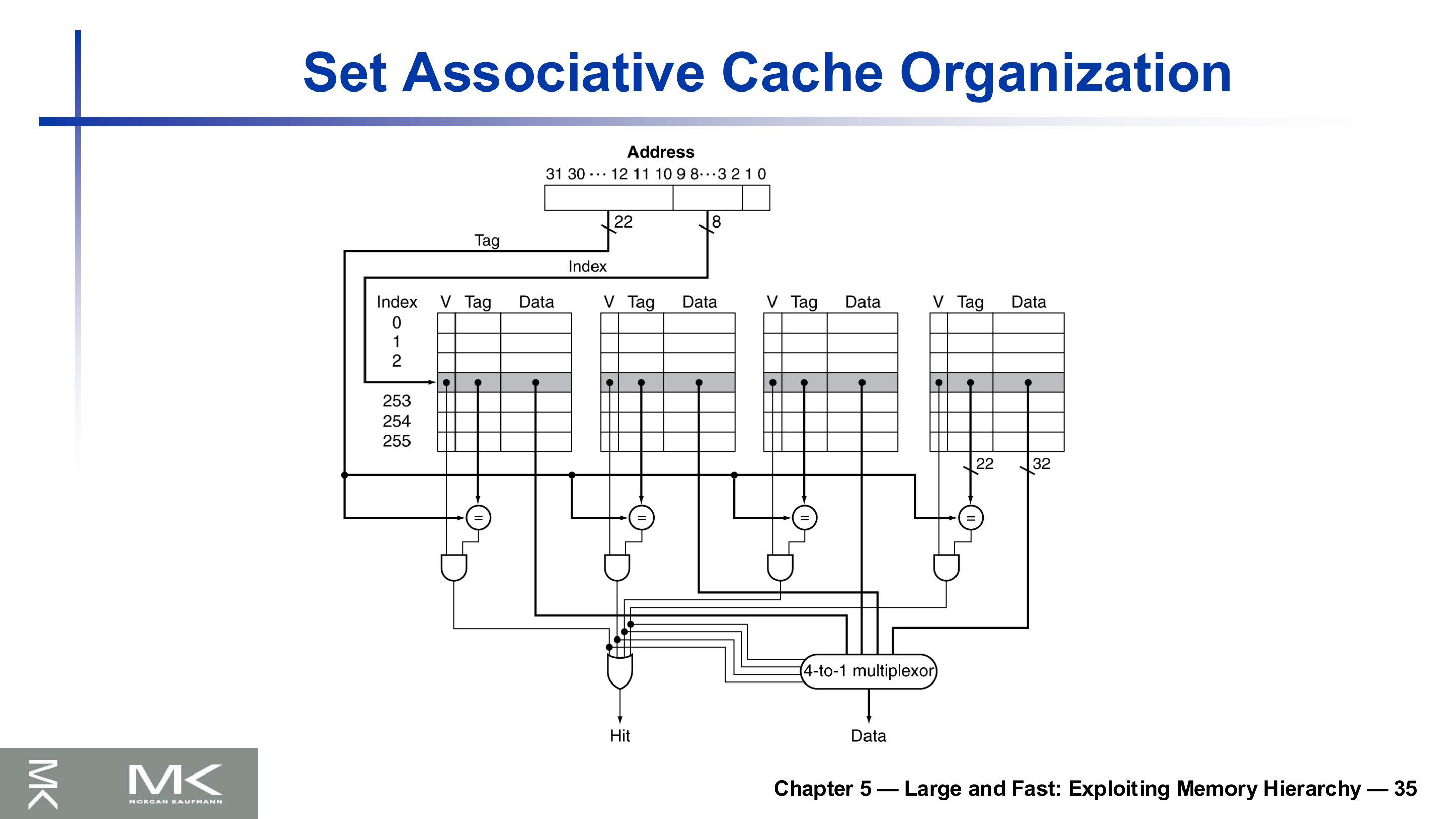
4-way 집합 연관의 구조다. 인덱스로 각 way에서 한 줄씩 고른 뒤, 네 way의 태그를 주소 태그와 동시에 비교한다. 일치하면서 유효한 way가 있으면 적중이고, 그 way의 데이터를 멀티플렉서로 골라 내보낸다. 비교기가 way 수만큼 병렬로 동작하는 것이 직접 사상과의 차이다.
교체 정책
직접 사상은 갈 자리가 하나라 교체할 게 없다. 집합 연관은 집합 안에서 누구를 쫓아낼지 골라야 한다.
- 우선 유효하지 않은(빈) 엔트리가 있으면 그곳을 쓴다.
- 다 차 있으면 LRU(Least Recently Used), 즉 가장 오래 안 쓰인 엔트리를 교체한다. 2-way는 구현이 간단하고 4-way까지는 관리할 만하지만, 그 이상은 추적 비용이 너무 커진다.
- Random: 무작위 교체. 연관도가 높으면 LRU와 성능이 거의 비슷해 구현이 쉬운 쪽을 택할 수 있다.
다단계 캐시 (Multilevel Cache)
빠른 CPU에서는 단일 캐시만으로 실패 페널티를 감당하기 어렵다. 그래서 캐시를 여러 단계로 둔다.
- L1(primary) 캐시: CPU에 붙어 있고 작지만 빠르다. 적중 시간(hit time) 최소화에 집중한다. 그래서 작게, 블록도 작게 만들어 실패 페널티를 줄인다.
- L2 캐시: L1 실패를 처리한다. 더 크고 느리지만 메인 메모리보다는 빠르다. 실패율을 낮춰 메인 메모리 접근을 피하는 것에 집중한다. 적중 시간의 영향은 상대적으로 작다.
- 고급 시스템은 L3 캐시까지 둔다.
설계 방향이 단계마다 다르다는 점이 핵심이다. L1은 속도, L2는 낮은 실패율. 그래서 보통 L1 블록이 L2 블록보다 작다.
성능 효과 예시
base CPI = 1, 클럭 4GHz(주기 0.25ns), 명령어당 실패율 2%, 메인 메모리 접근 100ns인 시스템을 보자.
L1만 있을 때: 실패 페널티 = $100\text{ns} / 0.25\text{ns} = 400$ 사이클.
\[\text{Effective CPI} = 1 + 0.02 \times 400 = 9\]L2 추가(접근 5ns, 메인 메모리까지 가는 전역 실패율 0.5%): L1 실패하고 L2 적중하면 페널티 = $5\text{ns}/0.25\text{ns} = 20$ 사이클, L2까지 실패하면 추가로 400 사이클.
\[\text{CPI} = 1 + 0.02 \times 20 + 0.005 \times 400 = 3.4\]성능비는 $9 / 3.4 \approx 2.6$배. L2 하나를 끼워 넣는 것만으로 2.6배 빨라진다.
메모리 대역폭 높이기
실패 페널티는 메모리에서 블록을 끌어오는 시간이 좌우한다. 메모리 1버스 사이클(주소 전송) + DRAM 접근 15사이클 + 1사이클(워드 전송), 4워드 블록 조건에서:
- 1워드 폭 메모리: 4워드를 한 워드씩 가져온다. 페널티 = $1 + 4 \times 15 + 4 \times 1 = 65$ 사이클.
- 4워드 폭 메모리: 4워드를 한 번에 접근. 페널티 = $1 + 15 + 1 = 17$ 사이클.
- 4뱅크 인터리브 메모리: 뱅크를 병렬 접근하고 워드는 순차 전송. 페널티 = $1 + 15 + 4 \times 1 = 20$ 사이클.
폭을 넓히거나 뱅크를 나눠 병렬화하면 같은 블록을 훨씬 적은 사이클에 옮겨 실패 페널티를 줄인다.
가상 메모리 (Virtual Memory)
같은 계층 아이디어를 한 단계 더 적용한 것이 가상 메모리다. 메인 메모리를 디스크(보조 저장장치)의 캐시처럼 쓴다. CPU 하드웨어와 OS가 함께 관리하며, 실제보다 큰 물리 메모리를 가진 듯한 환상을 준다.
- 각 프로그램은 자신만의 가상 주소 공간을 가져 다른 프로그램으로부터 보호된다.
- CPU와 OS가 가상 주소를 물리 주소로 변환한다.
- 가상 메모리의 “블록”을 페이지(page)라 하고, 변환 “실패”를 페이지 폴트(page fault)라 한다.
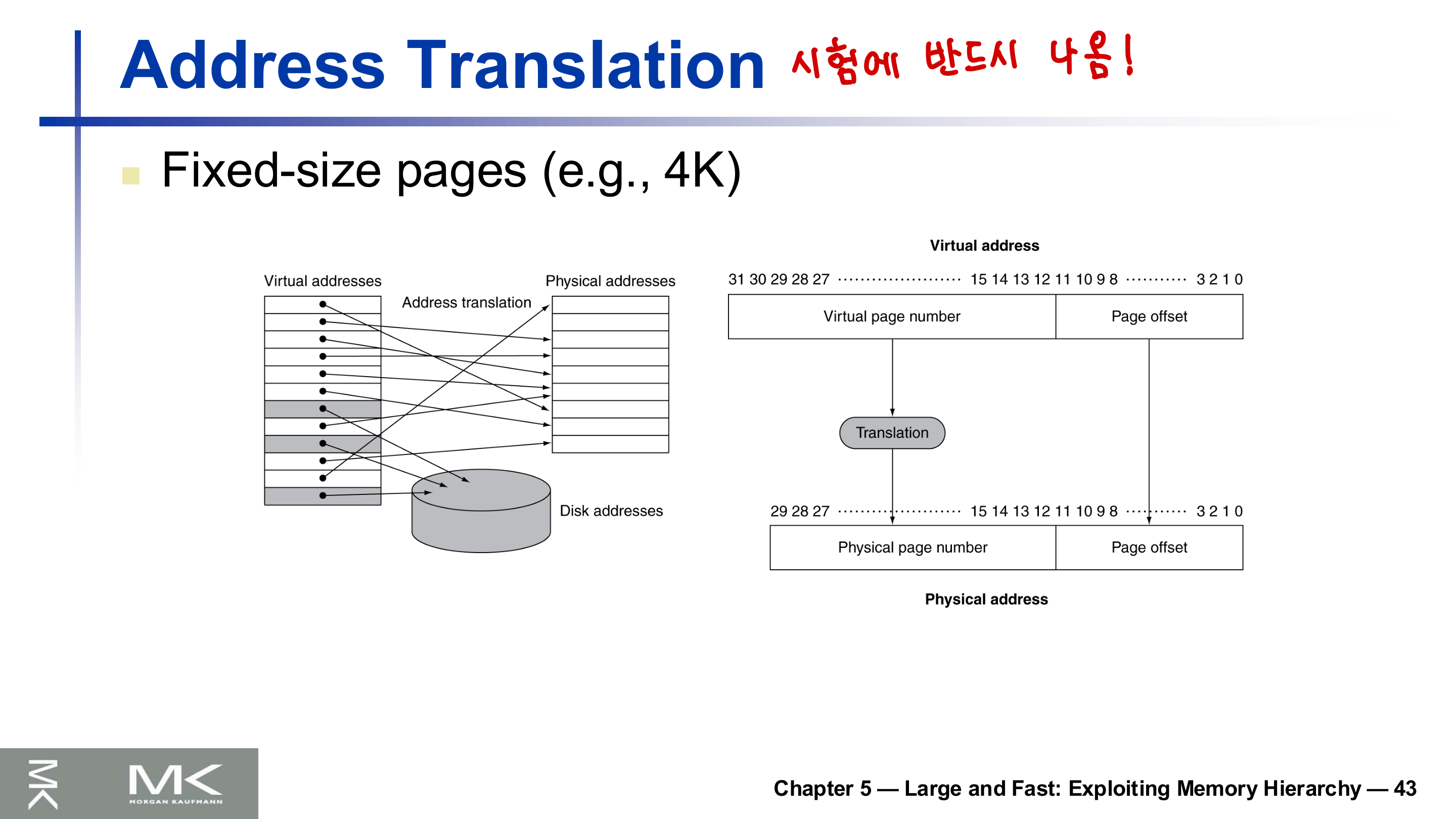
주소 변환
페이지는 고정 크기(예: 4KB)다. 가상 주소는 가상 페이지 번호(virtual page number)와 페이지 오프셋(page offset)으로 나뉜다. 변환은 페이지 번호만 물리 페이지 번호로 바꾸고, 오프셋은 그대로 둔다.
페이지 폴트는 데이터를 디스크에서 가져와야 하므로 수백만 사이클이 걸리고 OS 코드가 처리한다. 페널티가 워낙 커서, 폴트율을 최대한 낮추는 쪽으로 설계한다 — 완전 연관 배치를 쓰고(어떤 페이지든 어느 프레임에나) 똑똑한 교체 알고리즘을 둔다.
페이지 테이블
가상 페이지가 물리 메모리 어디에 있는지를 담는 자료구조가 페이지 테이블(page table)이다.
- 가상 페이지 번호로 인덱싱하는 페이지 테이블 엔트리(PTE) 배열이다.
- CPU의 페이지 테이블 레지스터가 물리 메모리에 있는 페이지 테이블의 위치를 가리킨다.
- 페이지가 메모리에 있으면 PTE는 물리 페이지 번호와 상태 비트(referenced, dirty 등)를 담는다.
- 없으면 PTE는 디스크 스왑 공간의 위치를 가리킨다.
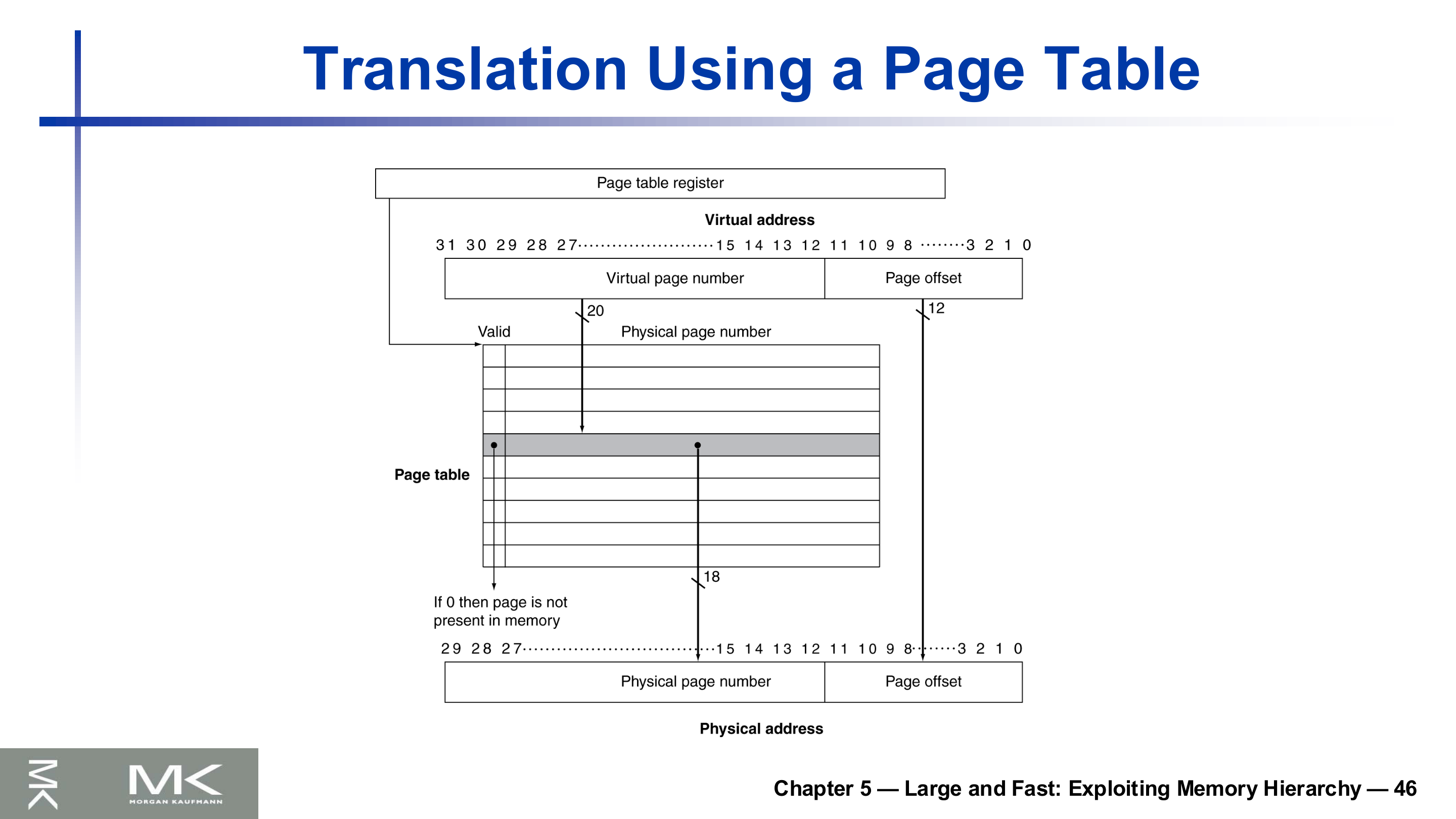
가상 페이지 번호로 페이지 테이블을 인덱싱해 PTE를 읽고, 유효 비트가 1이면 물리 페이지 번호를 꺼내 페이지 오프셋과 합쳐 물리 주소를 만든다. 유효 비트가 0이면 그 페이지는 메모리에 없다 — 페이지 폴트다.
TLB로 변환 가속
문제가 하나 있다. 주소 변환마다 페이지 테이블을 읽으려면 메모리 접근이 한 번 더 든다(PTE 읽기 + 실제 데이터 접근). 하지만 페이지 테이블 접근에도 지역성이 있다. 그래서 최근 사용한 PTE를 CPU 안의 작고 빠른 캐시에 둔다. 이것이 TLB(Translation Look-aside Buffer)다.
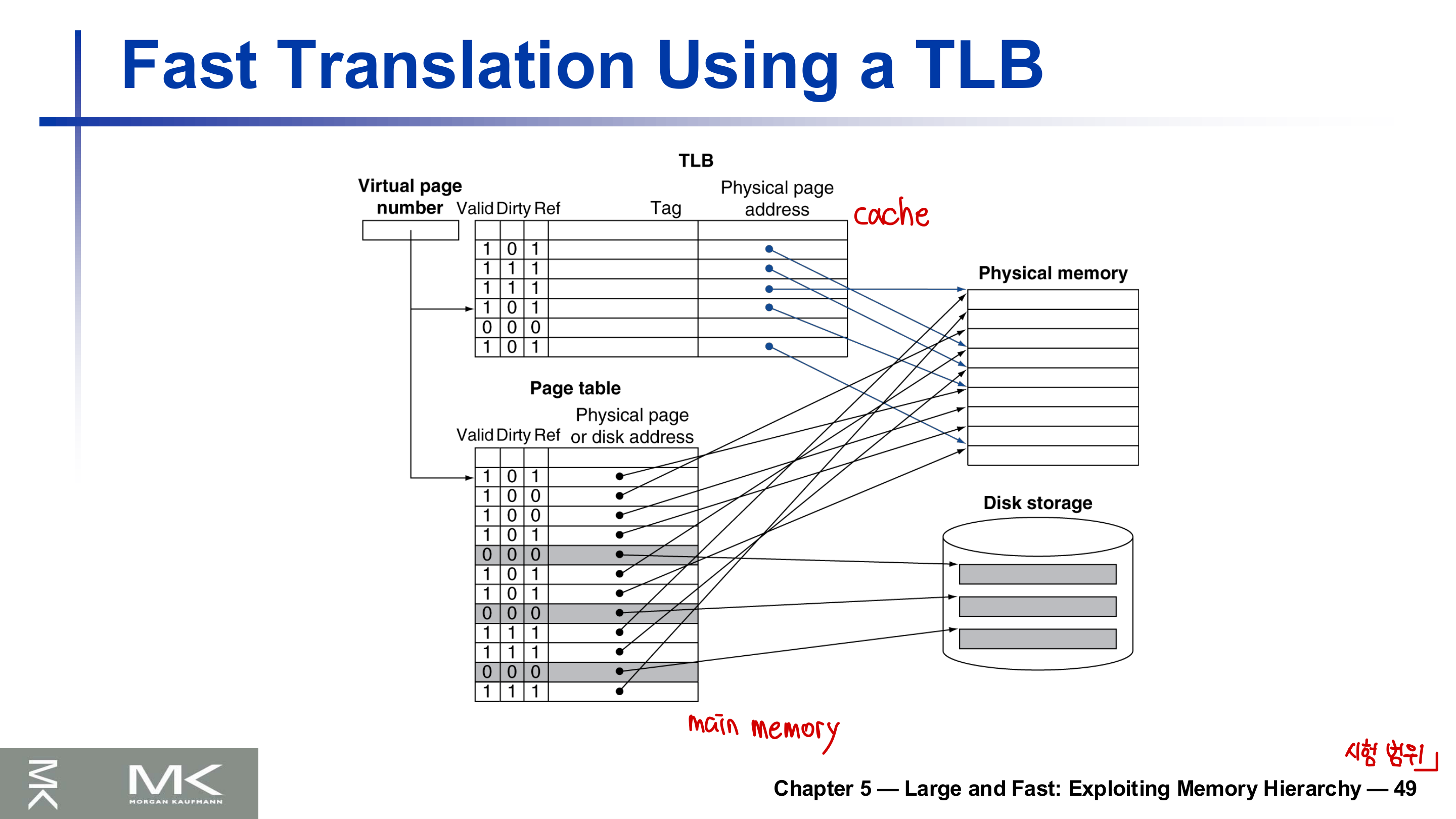
전형적으로 16~512개 PTE를 담고, 적중에 0.5~1사이클, 실패에 10~100사이클, 실패율 0.01~1% 수준이다. 변환할 때 먼저 TLB를 보고, 있으면(TLB hit) 즉시 물리 페이지 번호를 얻는다. TLB 실패 시:
- 페이지가 메모리에 있으면: 메모리의 페이지 테이블에서 PTE를 가져와 TLB에 채우고 재시도한다. 하드웨어로 처리할 수 있다.
- 페이지가 메모리에 없으면(페이지 폴트): OS가 디스크에서 페이지를 가져오고 페이지 테이블을 갱신한 뒤, 폴트를 낸 명령어부터 다시 실행한다.
페이지 폴트 핸들러는 폴트 가상 주소로 PTE를 찾고 → 디스크에서 페이지 위치를 알아내고 → 쫓아낼 페이지를 고르고(더티면 디스크에 먼저 기록) → 페이지를 메모리에 읽어 페이지 테이블을 갱신하고 → 프로세스를 다시 실행 가능하게 만든다.
TLB와 캐시의 상호작용
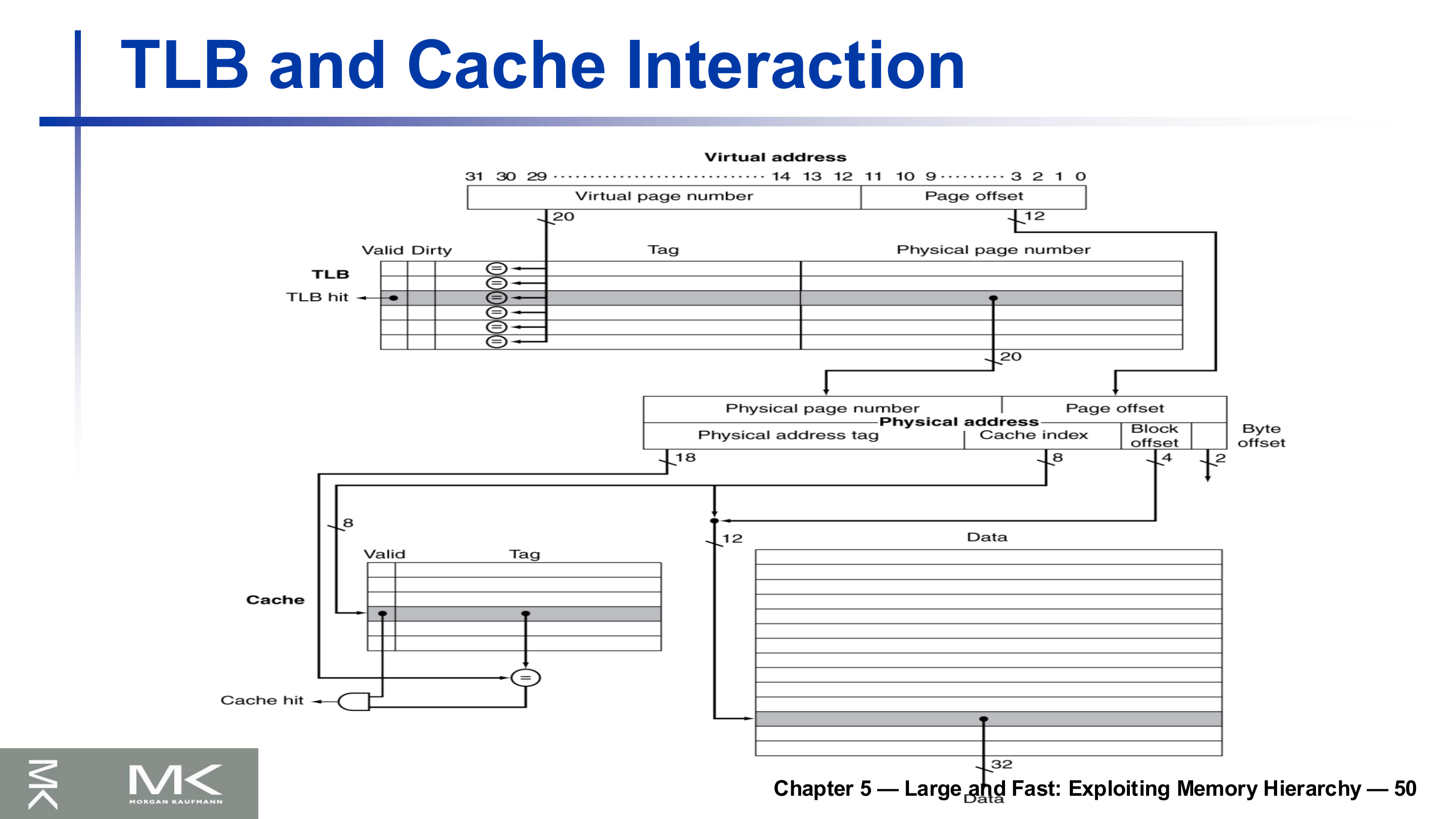
실제 접근은 두 단계를 거친다. 가상 주소 → (TLB) → 물리 주소 → (캐시) → 데이터. 가상 페이지 번호로 TLB를 조회해 물리 페이지 번호를 얻어 물리 주소를 완성하고, 그 물리 주소로 캐시를 인덱싱해 태그를 비교한다. TLB 적중과 캐시 적중이 모두 맞아야 메모리까지 가지 않고 데이터를 얻는다.
계층을 관통하는 네 가지 질문
캐시든 가상 메모리든 메모리 계층은 같은 네 가지 질문으로 정리된다.
블록을 어디에 두는가 / 어떻게 찾는가.
| 사상 방식 | 탐색 방법 | 태그 비교 횟수 |
|---|---|---|
| 직접 사상 | 인덱스로 한 곳 | 1 |
| n-way 집합 연관 | 집합 인덱스 후 집합 내 탐색 | $n$ |
| 완전 연관 | 전체 탐색 | 엔트리 수 |
하드웨어 캐시는 비교 횟수를 줄여 비용을 낮추므로 직접/집합 연관을 쓴다. 반면 가상 메모리는 페이지 테이블이라는 전체 룩업 테이블이 있어 완전 연관이 가능하고, 그만큼 실패(폴트)율을 낮추는 이득이 크다.
교체는 누구를. LRU가 이상적이지만 연관도가 높으면 하드웨어가 복잡하고 비싸다. 그래서 캐시는 Random으로 근사하기도 한다. 가상 메모리는 하드웨어 지원(reference 비트 등)으로 LRU를 근사한다.
쓰기는 어떻게. 쓰기 통과(상하위 동시 갱신, 쓰기 버퍼 필요)와 쓰기 후 기록(상위만 갱신, 교체 시 하위 기록, 상태 더 보관)이 있다. 가상 메모리는 디스크 쓰기 지연이 커서 쓰기 후 기록만 현실적이다.
실패의 세 가지 원인
실패율을 분석할 때 원인을 셋으로 나눈다(3C).
- 강제 실패(compulsory miss, cold start): 블록에 처음 접근할 때. 피할 수 없다.
- 용량 실패(capacity miss): 캐시가 유한해서, 쫓겨난 블록을 나중에 다시 찾을 때.
- 충돌 실패(conflict miss, collision): 완전 연관이 아닌 캐시에서 같은 집합을 두고 다툴 때. 같은 크기의 완전 연관 캐시였다면 안 났을 실패다.
이 분류는 설계 선택과 직결된다.
| 설계 변경 | 실패율 효과 | 부작용 |
|---|---|---|
| 캐시 크기 ↑ | 용량 실패 ↓ | 적중 시간 ↑ 가능 |
| 연관도 ↑ | 충돌 실패 ↓ | 적중 시간 ↑ 가능 |
| 블록 크기 ↑ | 강제 실패 ↓ | 실패 페널티 ↑, 너무 크면 오염으로 실패율 ↑ |
어느 하나를 공짜로 개선할 수 없고 항상 다른 비용을 치른다는 점이 캐시 설계의 본질이다.
정리
빠르고 큰 메모리는 없지만, 작고 빠른 메모리(L1 ↔ L2 ↔ DRAM ↔ disk)를 계층으로 쌓고 지역성을 활용하면 그런 메모리가 있는 것처럼 동작한다. 캐시는 사상 방식(직접/집합 연관/완전 연관), 쓰기 정책(통과/후기록), 교체 정책(LRU/Random)으로 설계되고, 그 효과는 실패율과 실패 페널티로 정량화된다. 가상 메모리는 같은 원리를 메인 메모리-디스크 사이에 적용한 것이며, 페이지 테이블과 TLB가 변환을 담당한다. 멀티프로세서로 갈수록 이 메모리 시스템 설계의 중요성은 더 커진다.