Introduction to SQL — SQL 기초 문법 정리
관계 대수는 데이터베이스 이론의 언어이고, SQL은 그 이론이 실제 시스템에서 쓰이는 언어이다. 관계 대수의 연산 하나하나가 SQL 구문 하나하나에 대응된다.
SQL의 역사
SQL은 1970년대 IBM San Jose 연구소의 System R 프로젝트에서 Sequel이라는 이름으로 처음 설계됐다. 이후 Structured Query Language로 이름이 바뀌었고, ANSI/ISO 표준으로 자리잡았다.
- SQL-86, SQL-89, SQL-92, SQL:1999, SQL:2003, SQL:2008, SQL:2011, SQL:2016, SQL:2023
상용 DBMS는 대부분 SQL-92 기능을 지원하고, 그 위에 자체 확장을 얹는 식이다. 따라서 동일한 SQL이 모든 시스템에서 똑같이 동작하지는 않는다.
예제 대학 데이터베이스
이 글 전체에서 사용할 스키마는 전형적인 대학 데이터베이스다.
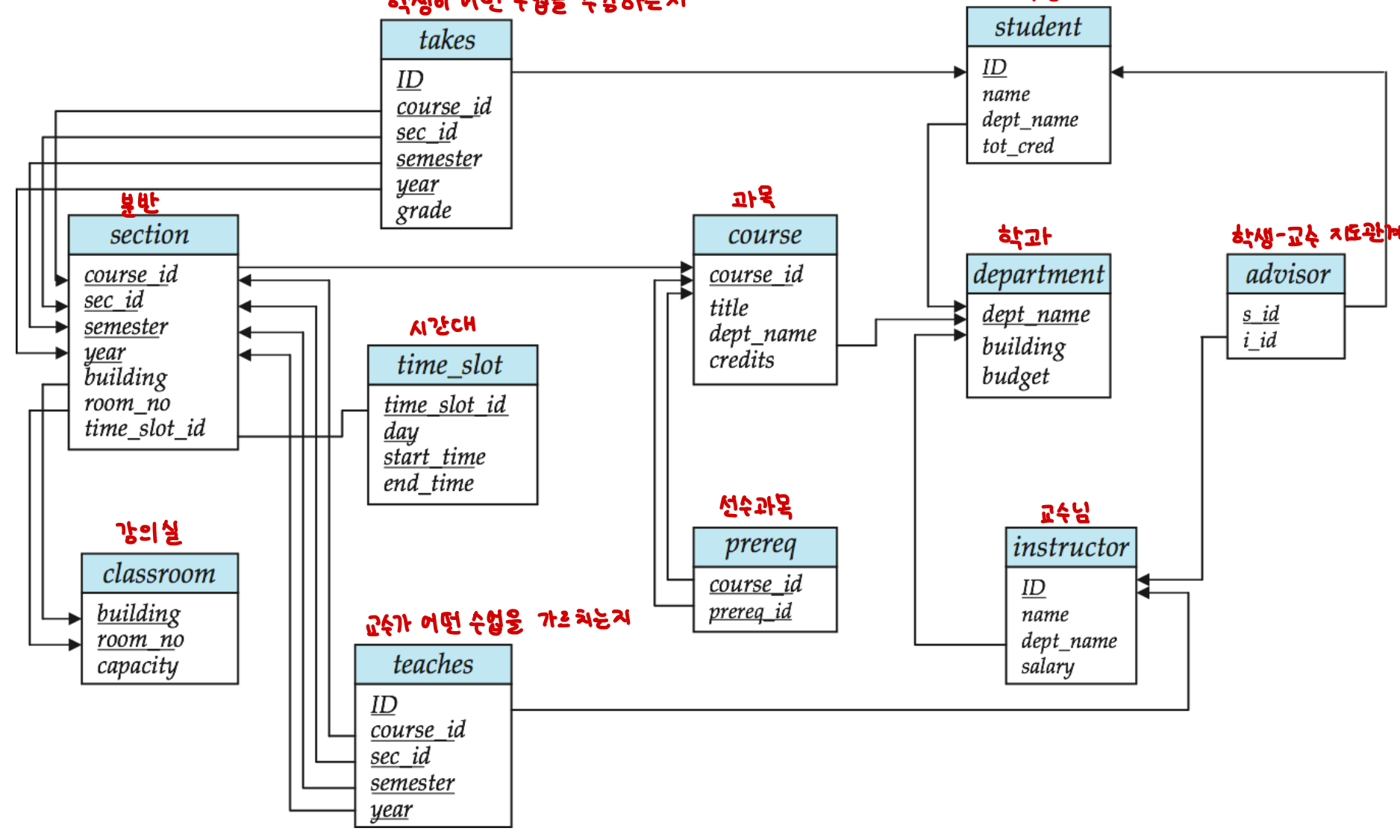
주요 릴레이션은 다음과 같다.
student(ID, name, dept_name, tot_cred)— 학생instructor(ID, name, dept_name, salary)— 교수course(course_id, title, dept_name, credits)— 과목section(course_id, sec_id, semester, year, ...)— 분반takes(ID, course_id, sec_id, semester, year, grade)— 수강teaches(ID, course_id, sec_id, semester, year)— 강의 담당department(dept_name, building, budget)— 학과prereq(course_id, prereq_id)— 선수과목
이 스키마를 머리에 담아두면 이후 등장하는 모든 예제 쿼리가 쉽게 읽힌다.
도메인 타입
SQL이 제공하는 기본 데이터 타입은 다음과 같다.
| 타입 | 의미 |
|---|---|
char(n) |
고정 길이 문자열, 길이 $n$ |
varchar(n) |
가변 길이 문자열, 최대 길이 $n$ |
int |
정수 (구현 의존) |
smallint |
작은 정수 |
numeric(p,d) |
고정 소수점, 전체 $p$자리 중 소수점 아래 $d$자리 |
real, double precision |
부동 소수점 |
float(n) |
최소 $n$자리 정밀도의 부동 소수점 |
char과 varchar의 차이는 저장 방식에 있다. char(10)에 "abc"를 넣으면 뒤쪽이 공백으로 채워지고, varchar(10)은 실제 길이만 저장한다.
테이블 정의 — Create Table
릴레이션은 create table 문으로 정의한다.
create table r (
A1 D1,
A2 D2,
...
An Dn,
(integrity-constraint1),
...
(integrity-constraintk)
);
r은 릴레이션 이름, $A_i$는 속성 이름, $D_i$는 속성의 도메인(타입)이다. 뒤에 무결성 제약조건(integrity constraint)을 나열할 수 있다.
create table instructor (
ID char(5),
name varchar(20) not null,
dept_name varchar(20),
salary numeric(8,2),
primary key (ID),
foreign key (dept_name) references department
);
무결성 제약조건
가장 기본적인 제약조건은 세 가지다.
primary key (A1, ..., An): 기본키 선언. 기본키에 포함된 속성은 자동으로not null이 적용된다foreign key (Am, ..., An) references r: 외래키 선언. 참조 대상은 항상 다른 릴레이션의 기본키여야 한다not null: 해당 속성에 null 값을 허용하지 않음
삽입 시 제약조건을 위반하면 해당 연산은 실패한다.
insert into instructor values ('10211', 'Smith', 'Biology', 66000); -- OK
insert into instructor values ('10211', null, 'Biology', 66000); -- 실패: name이 not null
복합 기본키
여러 속성이 모여서 기본키를 구성할 수도 있다. takes 릴레이션은 한 학생이 같은 과목을 여러 학기에 수강할 수 있으므로, (ID, course_id, sec_id, semester, year)의 조합이 기본키가 된다.
create table takes (
ID varchar(5),
course_id varchar(8),
sec_id varchar(8),
semester varchar(6),
year numeric(4,0),
grade varchar(2),
primary key (ID, course_id, sec_id, semester, year),
foreign key (ID) references student,
foreign key (course_id, sec_id, semester, year) references section
);
테이블 삭제·변경 — Drop & Alter
drop table r; -- 테이블 자체를 삭제
alter table r add A D; -- 속성 A 추가. 기존 튜플은 null로 채워짐
alter table r drop A; -- 속성 A 제거 (일부 DBMS는 지원하지 않음)
drop table은 테이블 자체를 없애는 반면, delete from r은 튜플만 지우고 스키마는 남겨둔다. 이 둘을 혼동하면 안 된다.
기본 질의 구조
SQL 질의는 다음 세 절(clause)로 이루어진다.
select A1, A2, ..., An
from r1, r2, ..., rm
where P
각 절은 관계 대수의 연산에 대응된다.
select→ 프로젝션 $\Pi$from→ 카티션 곱 $\times$where→ 셀렉션 $\sigma$
그리고 SQL 질의의 결과는 항상 릴레이션이다. 이 사실이 중첩 질의(nested query)를 가능하게 한다.
The select Clause
select는 결과에 포함할 속성을 지정한다. 관계 대수의 프로젝션 연산에 해당한다.
select name
from instructor;
SQL 식별자는 대소문자를 구분하지 않는다. Name, NAME, name은 모두 같은 이름이다.
distinct와 all
SQL은 릴레이션에 중복을 허용한다. 집합이 아닌 다중집합(multiset, bag) 의미론을 따른다는 뜻이다. 중복을 제거하려면 distinct 키워드를 쓴다.
select distinct dept_name from instructor; -- 중복 제거
select all dept_name from instructor; -- 중복 허용 (기본값)
와일드카드와 산술식
*는 모든 속성을 의미하고, select 절에는 산술 연산식도 올 수 있다.
select * from instructor;
select ID, name, salary/12 from instructor; -- 월급 환산
The where Clause
where는 결과가 만족해야 할 조건(predicate)을 명시한다. 관계 대수의 셀렉션에 대응된다.
select name
from instructor
where dept_name = 'Comp. Sci.' and salary > 80000;
조건은 and, or, not으로 결합할 수 있고, 산술식 결과에도 비교가 가능하다.
The from Clause
from은 질의에 사용할 릴레이션을 나열한다. 여러 릴레이션을 쓰면 카티션 곱이 된다.
select *
from instructor, teaches;
이 쿼리는 instructor의 모든 튜플과 teaches의 모든 튜플을 조합한 모든 쌍을 만든다. 즉, 두 릴레이션의 튜플 수가 각각 $m$, $n$이면 결과는 $m \times n$개의 튜플을 갖는다.
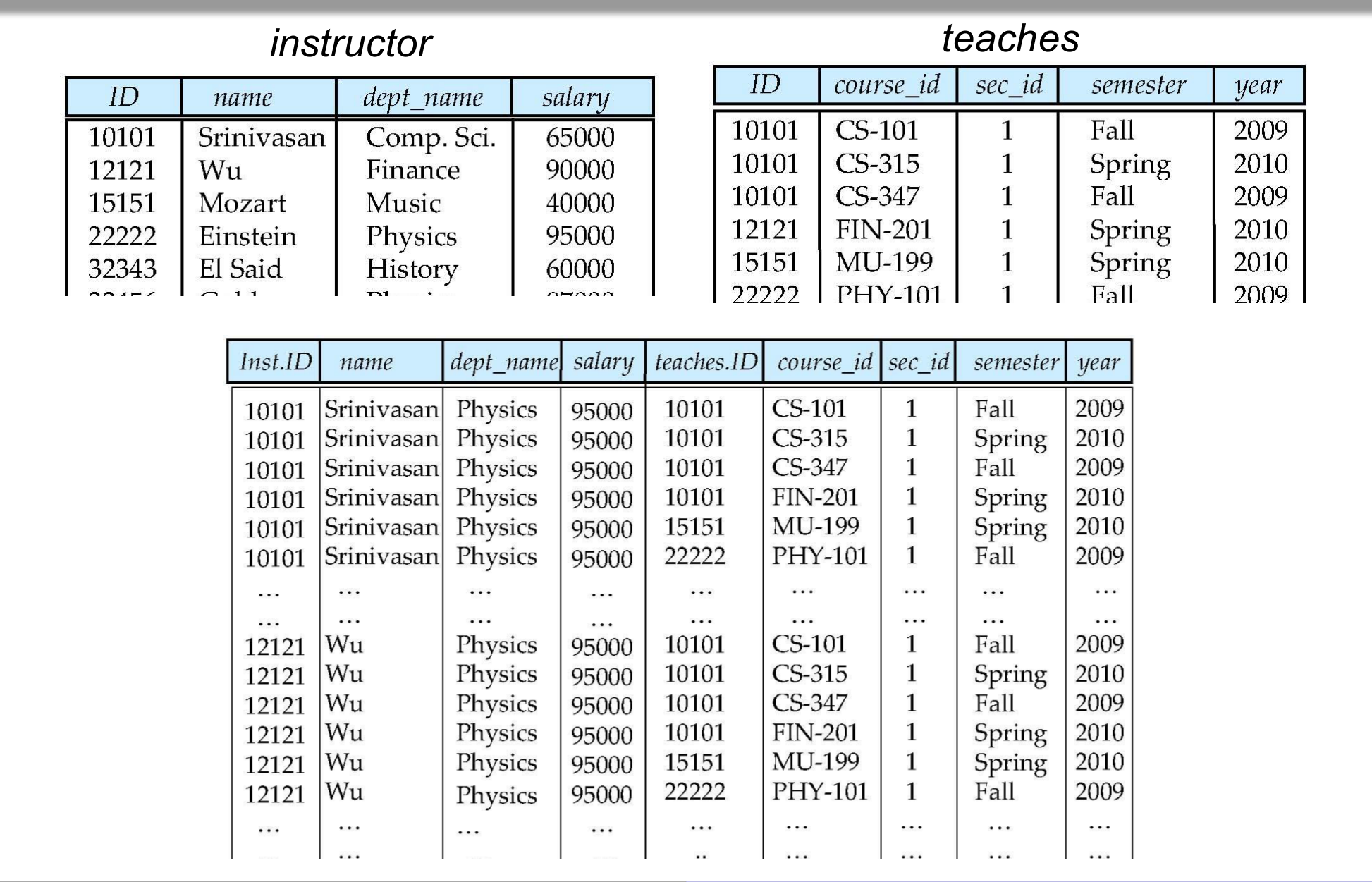
카티션 곱 자체는 직접적으로는 거의 쓸모가 없다. 그러나 where 절의 조건과 결합하면 조인이 된다.
조인 — Joins
Where 절로 하는 조인
“수업을 담당한 적이 있는 모든 교수의 이름과 강의한 과목 ID를 찾아라.”
select name, course_id
from instructor, teaches
where instructor.ID = teaches.ID;
카티션 곱으로 만든 모든 쌍 중에서 instructor.ID = teaches.ID를 만족하는 튜플만 남긴다. 이것이 관계 대수에서 말하는 세타 조인(theta join)이다.
Natural Join
두 릴레이션에서 이름이 같은 모든 속성의 값이 같은 튜플끼리 매칭하는 연산이 natural join이다. 공통 속성은 결과에 한 번만 등장한다.
select name, course_id
from instructor natural join teaches;
instructor와 teaches는 둘 다 ID 속성을 갖고 있으므로, natural join은 두 릴레이션의 ID가 같은 튜플끼리 자동으로 연결한다.
Natural Join의 함정
natural join은 같은 이름의 모든 속성에 대해 등호 조건을 건다. 여기에 위험이 있다.
“교수 이름과 해당 교수가 가르친 과목의 제목을 나열하라.”
-- 잘못된 버전
select name, title
from instructor natural join teaches natural join course;
이 쿼리는 instructor.dept_name과 course.dept_name이 같아야 한다는 조건까지 암묵적으로 거는 셈이다. 그러나 교수의 소속 학과와 과목이 개설된 학과가 반드시 같을 필요는 없다. 따라서 논리적으로 틀린 결과가 나온다.
올바른 버전은 다음 둘 중 하나이다.
-- 방법 1: 첫 natural join 후 course는 명시적으로 join
select name, title
from (instructor natural join teaches), course
where teaches.course_id = course.course_id;
-- 방법 2: join ... using으로 쓸 속성을 명시
select name, title
from (instructor natural join teaches) join course using (course_id);
join ... using(attr)은 “이 속성만 사용해서 조인하라”는 의미다. natural join과 달리 매칭에 쓸 속성을 지정할 수 있어 안전하다.
이름 변경 — Rename Operation
as 키워드로 릴레이션과 속성의 이름을 바꿀 수 있다. 관계 대수의 $\rho$에 대응된다.
select ID, name, salary/12 as monthly_salary
from instructor;
as는 같은 릴레이션을 두 번 참조해야 하는 경우에 특히 유용하다.
“어떤 Comp. Sci. 학과 교수보다 급여가 높은 모든 교수의 이름을 찾아라.”
select distinct T.name
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name = 'Comp. Sci.';
instructor를 두 번 참조하기 위해 T, S라는 별칭을 준다. as는 생략 가능해서 instructor T라고 써도 된다.
문자열 연산 — like
SQL은 문자열 패턴 매칭을 like 연산자로 제공한다. 두 개의 특수 문자를 사용한다.
%: 임의 길이의 부분 문자열 (0글자 이상)_: 임의의 한 문자
-- 이름에 'dar'가 포함된 교수
select name
from instructor
where name like '%dar%';
%나 _ 자체를 매칭하려면 escape를 쓴다.
where name like '100 \%' escape '\' -- "100 %" 매칭
이외에도 문자열 연결(||), 대소문자 변환, 길이 추출, 부분 문자열 같은 연산을 지원한다.
정렬 — order by
select distinct name
from instructor
order by name; -- 기본값은 오름차순(asc)
select * from instructor order by name desc; -- 내림차순
select * from instructor order by dept_name, name; -- 다중 정렬
order by는 select 절의 결과 릴레이션을 지정된 속성 기준으로 정렬한다.
where 절의 술어들
between
특정 범위를 검사할 때 사용한다.
select name
from instructor
where salary between 90000 and 100000;
-- 위는 salary >= 90000 and salary <= 100000과 동치
튜플 비교
여러 속성을 and로 묶는 대신 튜플 단위로 비교할 수 있다.
select name, course_id
from instructor, teaches
where (instructor.ID, dept_name) = (teaches.ID, 'Biology');
집합 연산 — union, intersect, except
두 질의 결과를 집합 연산으로 결합할 수 있다.
-- 2009년 가을 또는 2010년 봄에 개설된 과목
(select course_id from section where semester = 'Fall' and year = 2009)
union
(select course_id from section where semester = 'Spring' and year = 2010);
-- 두 학기 모두에 개설된 과목
... intersect ...
-- 2009년 가을에만 개설된 과목
... except ...
세 연산 모두 자동으로 중복을 제거한다. 중복을 유지하려면 union all, intersect all, except all을 쓴다. 튜플이 $r$에 $m$번, $s$에 $n$번 등장한다면 결과는 이렇다.
r union all s→ $m + n$번r intersect all s→ $\min(m, n)$번r except all s→ $\max(0, m - n)$번
Null 값과 3-값 논리
관계 대수에서 가장 까다로운 주제 중 하나가 null이다.
null은 값이 존재하지 않거나 알 수 없음을 나타낸다- null이 포함된 모든 산술식의 결과는 null이다. 예:
5 + null→null - null 검사에는
is null/is not null을 쓴다
select name
from instructor
where salary is null;
3-값 논리
null과 비교하면 결과는 unknown이다. SQL은 true, false에 더해 unknown을 포함하는 3-값 논리를 쓴다.
5 < null→unknownnull = null→unknown(주의:true가 아니다)
연산 규칙은 다음과 같다.
| 연산 | 규칙 |
|---|---|
| OR | unknown or true = true, unknown or false = unknown, unknown or unknown = unknown |
| AND | true and unknown = unknown, false and unknown = false, unknown and unknown = unknown |
| NOT | not unknown = unknown |
where 절의 결과가 unknown이면 false로 취급되어 해당 튜플은 결과에서 제외된다. “P is unknown”은 $P$가 unknown으로 평가될 때 true이다.
집계 함수 — Aggregate Functions
릴레이션의 한 열에 대해 집계 결과를 반환하는 함수들이다.
avg: 평균 (숫자 타입에만 가능)min,max: 최솟값/최댓값sum: 합 (숫자 타입에만 가능)count: 개수
-- Comp. Sci. 학과 교수의 평균 급여
select avg(salary)
from instructor
where dept_name = 'Comp. Sci.';
-- 2010년 봄에 강의한 교수의 수 (중복 제거)
select count(distinct ID)
from teaches
where semester = 'Spring' and year = 2010;
-- course 릴레이션의 튜플 수
select count(*)
from course;
Group By
특정 속성으로 그룹을 묶은 뒤, 각 그룹에 대해 집계 함수를 적용한다.
-- 학과별 평균 급여
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name;
group by 뒤에 나열한 속성이 같은 튜플들이 하나의 그룹이 되고, 그룹별로 avg(salary)를 계산한다.
중요한 제약: select 절에 집계 함수가 아닌 형태로 등장하는 속성은 반드시 group by에 포함되어야 한다.
-- 잘못된 질의
select dept_name, ID, avg(salary)
from instructor
group by dept_name;
ID가 group by에 없으므로 그룹 내에서 어떤 ID를 대표값으로 보여줄지 애매하다. 이 경우 max(ID)나 count(ID) 같은 집계로 감싸야 한다.
Having Clause
having은 그룹 단위의 조건을 건다. where와 달리 그룹 형성 이후에 적용된다.
-- 평균 급여가 42000을 초과하는 학과
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name
having avg(salary) > 42000;
where는 그룹이 만들어지기 전에 각 튜플에 대해 필터링하고, having은 그룹이 만들어진 후에 그룹을 필터링한다. 적용 시점이 다르다.
집계와 Null
count(*)를 제외한 모든 집계 함수는 null 값을 무시한다- 집계 대상이 모두 null이거나 빈 집합이면
sum,avg등은null을 반환한다 count는 0을 반환한다
중첩 질의 — Nested Subqueries
select-from-where 표현은 다른 질의 내부에 중첩될 수 있다. 흔히 쓰이는 용도는 세 가지다.
- 집합 소속 검사 (
in,not in) - 집합 비교 (
some,all) - 집합 크기 검사 (
exists,unique)
Set Membership — in / not in
-- 2009년 가을과 2010년 봄에 모두 개설된 과목
select distinct course_id
from section
where semester = 'Fall' and year = 2009 and
course_id in (select course_id
from section
where semester = 'Spring' and year = 2010);
-- 2009년 가을에만 개설되고 2010년 봄에는 없었던 과목
select distinct course_id
from section
where semester = 'Fall' and year = 2009 and
course_id not in (select course_id
from section
where semester = 'Spring' and year = 2010);
튜플 단위의 in 검사도 가능하다.
-- ID 10101 강사가 가르친 강의 섹션을 수강한 학생 수
select count(distinct ID)
from takes
where (course_id, sec_id, semester, year) in
(select course_id, sec_id, semester, year
from teaches
where teaches.ID = 10101);
Set Comparison — some / all
> some은 “적어도 하나보다 크다”는 의미다.
-- Biology 학과 어떤 교수보다도 급여가 높은 교수
select distinct T.name
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name = 'Biology';
-- 동일한 질의를 > some으로
select name
from instructor
where salary > some (select salary
from instructor
where dept_name = 'Biology');
F <comp> some r은 존재($\exists$) 의미다. “관계 $r$의 어떤 튜플 $t$에 대해 $F$가 $t$와의 비교를 만족”하면 참이 된다. 비교 연산자는 $<, \le, >, \ge, =, \ne$ 중 아무거나 가능하다.
= some은 in과 동치이다. 하지만 <> some은 not in과 동치가 아니다.
> all은 “모든 것보다 크다”는 의미로, 전칭($\forall$)에 대응된다.
-- Biology 학과 모든 교수보다 급여가 높은 교수
select name
from instructor
where salary > all (select salary
from instructor
where dept_name = 'Biology');
마찬가지로 <> all은 not in과 동치이지만, = all은 in과 동치가 아니다.
exists
exists r은 서브쿼리 $r$이 비어있지 않으면 true를 반환한다.
-- 2009년 가을과 2010년 봄에 모두 개설된 과목 (exists 버전)
select course_id
from section as S
where semester = 'Fall' and year = 2009 and
exists (select *
from section as T
where semester = 'Spring' and year = 2010
and S.course_id = T.course_id);
여기서 내부 쿼리의 S.course_id처럼 외부 쿼리의 변수를 참조하는 서브쿼리를 상관 서브쿼리(correlated subquery)라고 한다. 외부 튜플 하나하나에 대해 내부 쿼리가 재실행되는 셈이다.
not exists로 표현하는 전칭
“Biology 학과의 모든 과목을 수강한 학생을 찾아라.” 이 질의는 “모든 X에 대해 P(X)”라는 전칭 명제인데, SQL에는 for all 같은 직접적 구문이 없다. 대신 집합 포함 관계로 바꿔서 표현한다.
select distinct S.ID, S.name
from student as S
where not exists ((select course_id
from course
where dept_name = 'Biology')
except
(select T.course_id
from takes as T
where S.ID = T.ID));
내부의 의미는 이렇다. “Biology 전체 과목 집합 − 이 학생이 수강한 과목 집합”이 공집합이면, 이 학생은 Biology의 모든 과목을 수강한 것이다. = all 계열로는 이 질의를 표현할 수 없다는 점이 재미있다.
unique
unique r은 서브쿼리 $r$에 중복 튜플이 없는지 검사한다.
-- 2009년에 한 번만 개설된 과목
select T.course_id
from course as T
where unique (select R.course_id
from section as R
where T.course_id = R.course_id and R.year = 2009);
다만 unique는 표준에 있지만 실제 DBMS에서 구현된 경우가 드물다.
From 절 서브쿼리 — Derived Relations
from 절에도 서브쿼리를 넣을 수 있다. 결과 릴레이션을 임시 테이블처럼 쓰는 방식이다.
-- 평균 급여가 42000 초과인 학과
select dept_name, avg_salary
from (select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name)
where avg_salary > 42000;
서브쿼리가 먼저 실행되어 (dept_name, avg_salary) 릴레이션을 만들고, 외부 쿼리가 이 결과에 대해 필터링한다. 같은 질의를 having으로도 쓸 수 있지만, from-절 서브쿼리는 더 복잡한 조합에 유연하게 대응할 수 있다.
With Clause
with는 질의 전용의 임시 뷰를 정의한다. 해당 뷰는 그 쿼리 안에서만 유효하다.
-- 예산이 최대인 학과 찾기
with max_budget (value) as
(select max(budget)
from department)
select budget
from department, max_budget
where department.budget = max_budget.value;
with는 복잡한 쿼리를 여러 단계로 나눠서 가독성을 높이는 도구다. 중첩 서브쿼리보다 “단계를 명명”하는 방식이 이해하기 쉬운 경우가 많다.
-- 총 급여가 전체 학과 평균보다 높은 학과
with dept_total (dept_name, value) as
(select dept_name, sum(salary)
from instructor
group by dept_name),
dept_total_avg (value) as
(select avg(value)
from dept_total)
select dept_name
from dept_total, dept_total_avg
where dept_total.value >= dept_total_avg.value;
Scalar Subquery
결과가 단일 속성, 단일 튜플인 서브쿼리를 스칼라 서브쿼리라 부른다. 값 하나로 취급되므로 select 절 같은 곳에 직접 쓸 수 있다.
-- 학과별 교수 수
select dept_name,
(select count(*)
from instructor
where department.dept_name = instructor.dept_name) as num_instructors
from department;
내부 쿼리는 상관 서브쿼리라서 외부 department의 각 튜플마다 실행된다. 이 방식의 장점은 교수가 하나도 없는 학과도 결과에 나타난다는 점이다. group by로 짜면 해당 학과가 출력에서 빠져버린다.
데이터 수정 — Deletion
delete from은 튜플을 제거한다. 속성을 제거하는 alter table drop과 혼동하면 안 된다.
delete from instructor; -- 전체 삭제
delete from instructor where dept_name = 'Finance'; -- 조건 삭제
-- Watson 건물에 있는 학과 소속 교수 삭제
delete from instructor
where dept_name in (select dept_name
from department
where building = 'Watson');
Delete의 함정
“평균 급여보다 낮은 교수 삭제”를 이렇게 쓴다고 하자.
delete from instructor
where salary < (select avg(salary) from instructor);
문제가 있다. 튜플을 하나 지울 때마다 평균 급여가 바뀌기 때문이다. SQL 표준은 이 문제를 해결하기 위해 두 단계로 동작한다.
- 먼저
avg를 계산하고, 삭제 대상 튜플을 모두 찾는다 - 그 후 찾은 튜플을 삭제한다 (평균을 다시 계산하지 않음)
데이터 수정 — Insertion
insert into는 튜플을 추가한다.
-- 속성 순서대로 값 입력
insert into course
values ('CS-437', 'Database Systems', 'Comp. Sci.', 4);
-- 속성명을 명시 (순서 바꿔도 됨)
insert into course (course_id, title, dept_name, credits)
values ('CS-437', 'Database Systems', 'Comp. Sci.', 4);
-- null 값 삽입
insert into student
values ('3003', 'Green', 'Finance', null);
서브쿼리로 삽입
values 대신 select를 쓰면 다른 릴레이션의 튜플을 가져와서 삽입할 수 있다.
-- 모든 교수를 tot_cred=0으로 student에 추가
insert into student
select ID, name, dept_name, 0
from instructor;
주의할 점이 하나 있다. select-from-where 문은 삽입이 시작되기 전에 완전히 평가된다. 그렇지 않으면 다음과 같은 질의가 무한 루프에 빠진다.
insert into table1 select * from table1;
SQL은 먼저 select *의 스냅샷을 완전히 만들고, 그 결과를 table1에 삽입한다. 따라서 삽입 연산 중에 자기 자신을 참조해도 안전하다.
데이터 수정 — Updates
update는 기존 튜플의 값을 수정한다.
-- 급여 10만 초과면 3%, 그 외는 5% 인상
update instructor
set salary = salary * 1.03
where salary > 100000;
update instructor
set salary = salary * 1.05
where salary <= 100000;
순서가 중요하다. 만약 5% 인상을 먼저 수행하면, 원래 9만 8천이었던 교수가 5% 오른 후 10만을 넘어서 다시 3%를 또 받게 된다.
Case Statement
위 두 개의 update를 하나로 합칠 수 있다.
update instructor
set salary = case
when salary <= 100000 then salary * 1.05
else salary * 1.03
end;
case ... when ... then ... else ... end 구문은 조건에 따라 값을 다르게 지정할 때 쓴다. 한 번의 순회로 모든 튜플을 업데이트하므로 순서 문제가 생기지 않는다.
스칼라 서브쿼리를 쓰는 Update
-- 학생별 총 이수학점 재계산
update student S
set tot_cred = (select sum(credits)
from takes natural join course
where S.ID = takes.ID
and takes.grade <> 'F'
and takes.grade is not null);
수강한 과목이 없는 학생은 sum이 null을 반환하므로 tot_cred가 null이 된다. 이를 0으로 만들고 싶으면 case로 감싼다.
case
when sum(credits) is not null then sum(credits)
else 0
end
정리
SQL의 기본은 결국 세 축이다.
- DDL:
create table,drop table,alter table으로 스키마를 정의한다 - DML - 조회:
select-from-where와 그 확장인 조인, 집계, 중첩 질의 - DML - 수정:
insert,delete,update
관계 대수의 $\sigma$, $\Pi$, $\times$, $\rho$가 각각 where, select, from, as에 대응된다는 점만 이해하면, 나머지 문법은 그 위에 얹힌 편의 기능이다. 특히 중첩 질의와 with 절은 복잡한 논리를 단계적으로 표현하는 핵심 도구이므로, 서브쿼리의 평가 순서를 머릿속으로 따라갈 수 있어야 한다.