AWS CLF — Data Analytics
AWS DMS(Data Migration Service)
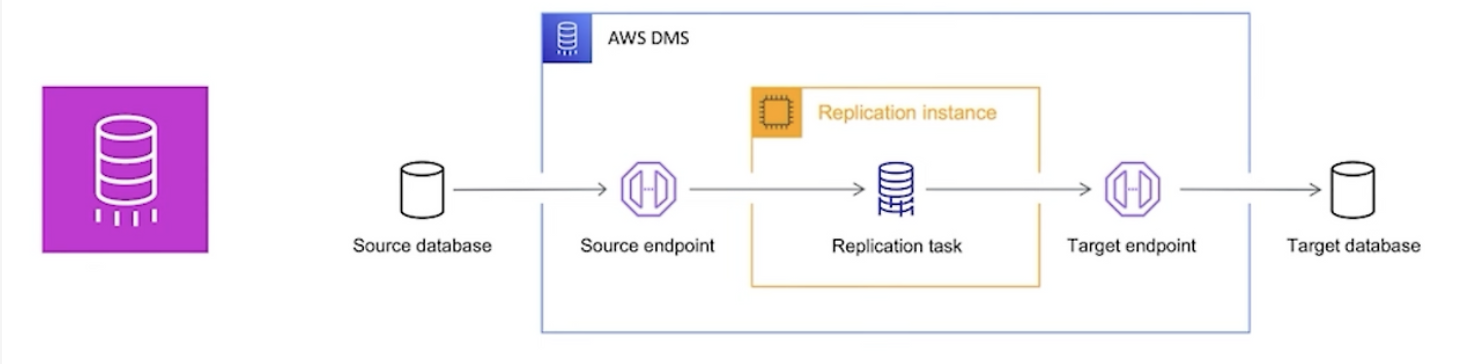
- AWS에서 제공하는 완전관리형 데이터베이스 마이그레이션 서비스
- 관계형 데이터베이스, 데이터 웨어하우스, NoSQL 데이터베이스 및 기타 유형의 데이터 스토어를 마이그레이션할 수 있음
- 온프레미스와 AWS 클라우드 간의 마이그레이션 가능
- MySQL, PostgreSQL, Oracle, SQL Server, MongoDB 등 20개 이상의 데이터베이스 및 분석 엔진 간의 마이그레이션을 지원
- 스키마 변환 및 데이터 변환 기능을 제공하여 소스 데이터베이스와 대상 데이터베이스 간의 데이터 형식이나 구조의 차이를 보완
- 데이터 변경을 추적하고 모니터링할 수 있는 기능을 제공
AWS EMR(Elastic MapReduce)
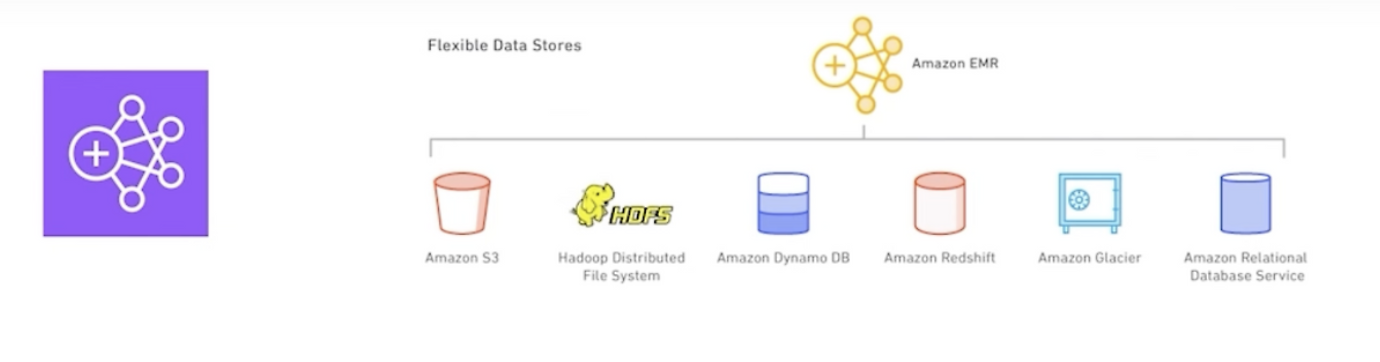
- AWS의 관리형 하둡 클러스터 서비스
- 하둡 클러스터를 손쉽게 생성해주어 Apache Spark와 같은 오픈 소스 프레임워크를 사용한 데이터 분석 및 처리를 용이하게 해줌
- S3, DynamoDB, RDS 등 다양한 데이터 스토어를 활용한 데이터 처리가 가능
- 사용자가 UI에서 몇 번의 클릭만으로 손쉽게 클러스터를 생성 및 관리 가능
- 작업 부하에 따라 자동으로 클러스터의 크기를 조정하여 작업을 더 빠르게 처리할 수 있도록 지원
- 클러스터 구성 서버로 spot이나 예약된 인스턴스를 사용할 수 있어 비용 절감 가능
- 클러스터나 서버를 생성하고 관리하지 않고도 빅데이터 분석 애플리케이션을 실행할 수 있는 EMR Serverless 지원
- 클러스터(Cluster): 여러 대의 컴퓨터를 하나로 묶어, 외부에서는 마치 하나의 거대한 컴퓨터처럼 작동하게 만든 그룹
- 하둡(Hadoop): 한 대의 컴퓨터로 처리할 수 없는 양의 빅데이터를 여러 대의 저렴한 컴퓨터를 묶어 병렬로 처리하는 오픈소스 소프트웨어 기술 생태계
- MapReduce: 구글이 만든 대용량 데이터 처리를 위한 프로그래밍 모델 및 프레임워크
AWS Athena
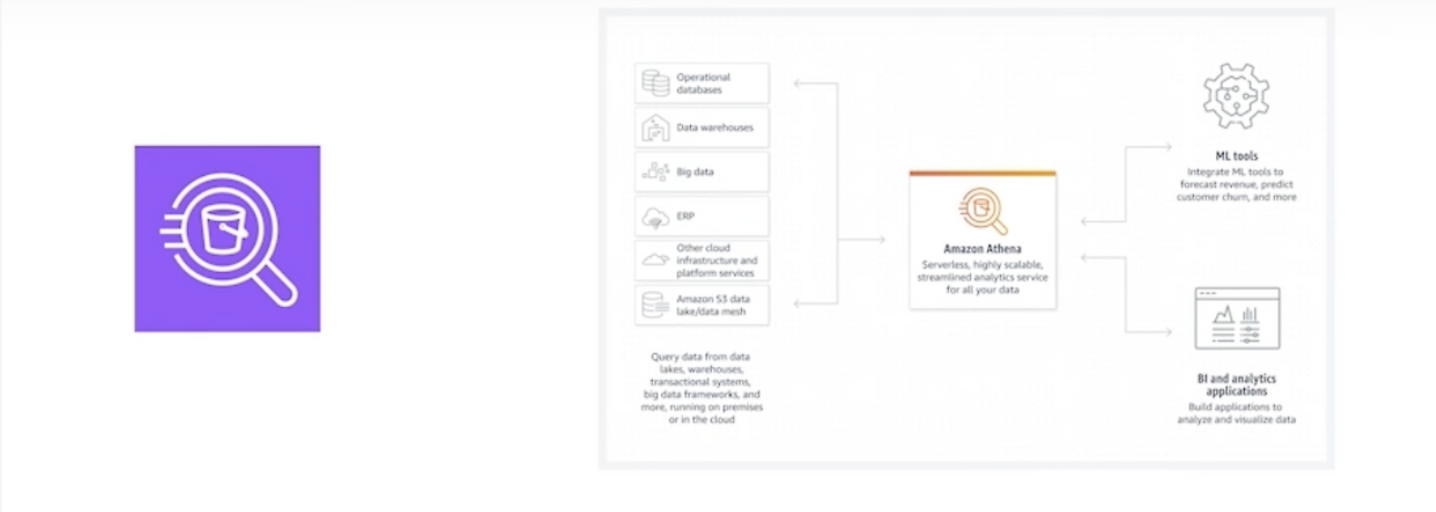
- PrestoSQL엔진을 사용하는 Serverless SQL 쿼리 서비스
- 별도의 데이터 이전/로딩 없이 Amazon S3에 저장된 데이터에 대한 직접적인 쿼리 가능
- 별도의 인프라를 설정하거나 관리할 필요없이 SQL 쿼리를 사용하여 대용량 데이터를 검색하고 분석
- CSV, JSON, ORC, Avro 또는 Parquet와 같은 다양한 종류의 데이터 형식을 지원
- AWS Glue나 QuickSight 등 관련 분석 서비스와 통합하여 효율적인 이용이 가능
- $5.00 per TB of data scaned 이며 사용한 리소스에 대해서만 요금을 지불하는 경제적 비용 모델
- 쿼리 엔진 (Presto): 다양한 데이터 소스에 저장된 데이터를 ‘그 자리에서(In-place)’ 직접 표준 SQL로 분석할 수 있게 해주는 분산 SQL 쿼리 엔진
AWS Glue
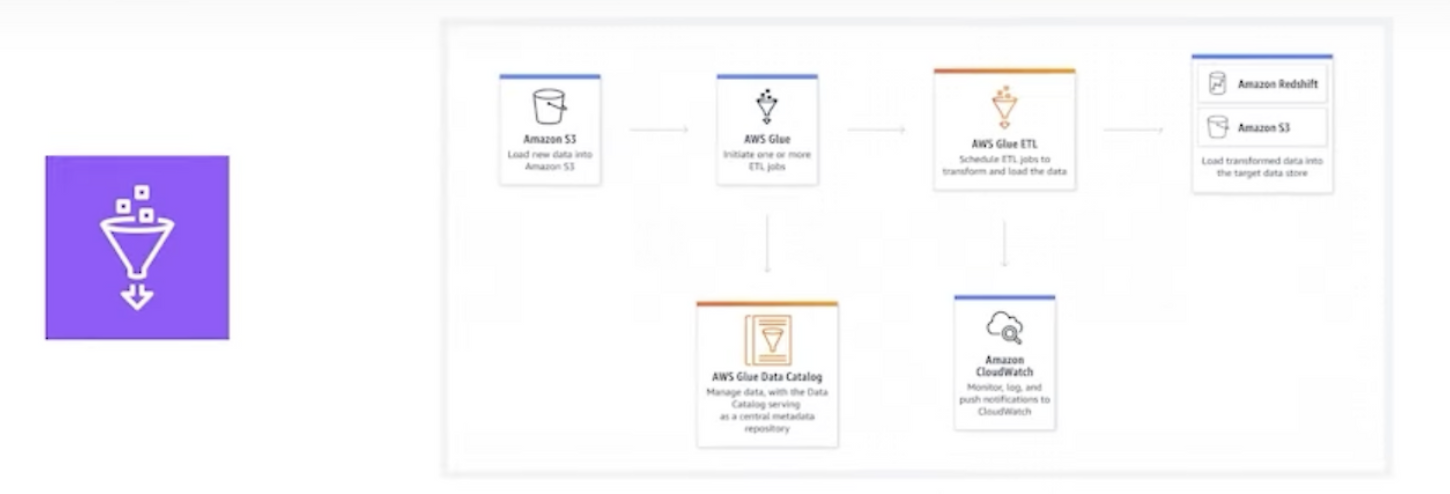
- 분석 사용자가 여러 소스의 데이터를 쉽게 검색, 준비, 이동, 통합할 수 있도록하는 Serverless 데이터 통합 서비스
- 완전 관리형 ETL(Extract, Transform, Load)서비스
- 데이터 워크로드를 간단하게 준비하고 변환하며, 데이터 파이프라인 구축을 손쉽게 할 수 있도록 도와줌
- 스케쥴링 및 모니터링 기능을 통해 데이터 파이프라인을 구축하고 관리
- 별도의 코드 작성 없이도 ETL을 위한 시각적인 인터페이스를 제공
- 데이터 카탈로그를 제공하여 데이터 스키마 및 메타데이터를 관리하고 검색
- AWS 및 온프레미스 데이터 스토어 등 70개 이상의 다양한 데이터 소스를 검색하여 연결하고 관리 가능 | 구분 | AWS Glue | AWS Athena | | — | — | — | | 핵심 역할 | 데이터 준비 (Data Preparation) | 데이터 분석 (Data Analysis) | | 주요 기능 | 데이터 카탈로그 생성ETL (데이터 추출, 변환, 적재) | 서버리스 SQL 쿼리 실행 | | 작동 방식 | 스케줄 또는 이벤트 기반의 배치 작업 | 사용자가 직접 실행하는 대화형 쿼리 | | 결과물 | 정리된 데이터 (예: Parquet 파일), 데이터 카탈로그 | 쿼리 결과 (화면에 표시되거나 파일로 저장) | | 비유 | 사서 (도서관을 정리하고 목록을 만듦) | 분석가 (사서가 만든 목록을 보고 책을 찾아 분석함) | | 관계 | 상호 보완적 파트너. Glue가 만든 카탈로그를 Athena가 사용 | 상호 보완적 파트너. Glue의 카탈로그가 있어야 쿼리 가능 |
AWS Redshift

- 클라우드에서 완전히 관리되는 페타바이트급 데이터 웨어하우스 서비스
- 대규모 데이터셋을 조회하고 분석하는데 사용
- 열 지향 데이터베이스 엔진을 기반으로 하여 데이터 압축
- AI 기반의 완전관리형 대량 병렬 처리(MPP) 아키텍처를 통해 빠르고 높은 성능과 확장성 제공
- 자동으로 용량이 조정되어 까다롭고 예측할 수 없는 워크로드에도 빠른 성능을 제공
- AWS Quicksight나 Tableau와 같은 BI 툴들과 호환
- Redshift Serverless를 지원하여 프로비저닝된 데이터 웨어하우스를 구성하지 않아도 데이터를 액세스하고 분석 가능
- 데이터 웨어하우스(Data Warehouse): 기업의 의사결정을 돕기 위해, 여러 곳에 흩어져 있는 운영 시스템의 데이터를 ‘주제별로 통합’하고 ‘과거부터 현재까지의 시점’으로 정리하여, ‘분석’에 최적화된 형태로 저장하는 데이터베이스
Glue와 Redshift 차이점 정리: | 구분 | AWS Glue | AWS Redshift | | — | — | — | | 핵심 역할 | ETL (데이터 가공 및 이동) | 데이터 웨어하우스 (데이터 저장 및 분석) | | 서비스 종류 | 서버리스 데이터 통합 서비스 | 완전 관리형 데이터 웨어하우스 | | 데이터 처리 | ‘과정’을 담당. 데이터를 변환하고 목적지로 보냄 | ‘결과’를 담당. 변환된 데이터를 저장하고 쿼리 | | 주요 작업 | 데이터 정제, 형식 변환, 스키마 생성(데이터 카탈로그) | 복잡한 SQL 쿼리, BI 대시보드, 대규모 데이터 분석 | | 일반적인 흐름 | S3(원본) → Glue(처리) → Redshift(분석) | |
Athena 와 RedShift 차이점 정리
| 구분 | Amazon Athena | Amazon Redshift |
|---|---|---|
| 아키텍처 | 서버리스 (Serverless) | 프로비저닝된 클러스터 |
| 데이터 위치 | S3에서 바로 쿼리 | 클러스터 내부에 로드 (권장) |
| 비용 모델 | 쿼리당/스캔량 기준 (Pay-per-query) | 클러스터 내부에 로드 (권장) |
| 핵심 사용 사례 | 가끔씩 하는 Ad-hoc 쿼리, S3 데이터 탐색 | 지속적이고 복잡한 비즈니스 인텔리전스(BI) 분석 |
AWS Kinesis

- 다양한 규모의 실시간성 데이터를 효율적으로 처리하고 분석하는 완전관리형 서비스
- 대용량 데이터를 실시간으로 수집, 변환하고 분석하는 데 사용됨
- IoT(Internet of Things), 로그 및 이벤트 데이터, 비디오 및 오디오 스트리밍 등과 같은 실시간 데이터를 처리하는 데 활용
- Data Streams, Data Firehose, Managed Service for Apache Flink, Kinesis Video Streams 4가지 세부 서비스로 구성됨
Kinesis Data Streams
- 데이터 스트림을 통해 대규모의 실시간 데이터를 안정적으로 수집, 처리, 저장할 수 있는 서비스
- 발생하는 데이터를 실시간으로 수집하여 다른 대상을 통해 받아서 작업 가능
Kinesis Data Firehouse
- 데이터 스트림에서 데이터를 수집하여 S3, Redshift, OpenSearch 등의 대상으로 배달하는 서비스
- Lambda 함수와 함께 사용되어 데이터에 대한 변환 작업 수행 후 저장할 수 있음
Amazon Managed Service for Apache Flink
- Apache Flink->대용량의 데이터에 대해 실시간 및 배치 처리를 할 수 있도록 해주는 오픈소스 분산 엔진
- Apache Flink 애플리케이션에 대한 완전 관리형 서비스 제공
- 스트리밍 데이터를 실시간으로 변환 및 분석하고 애플리케이션을 다른 AWS 서비스와 통합
Amazon Kinesis Video Streams
- 라이브 비디오를 스트리밍하며,비디오 데이터에 대한 실시간/배치 분석 등을 위한 서비스
- 스마트폰, 보안 카메라, 웹캠,드론 및 기타 소스를 비롯한 수백만 개의 소스에서 대량의 라이브 비디오 데이터를 캡쳐 가능
AWS OpenSearch
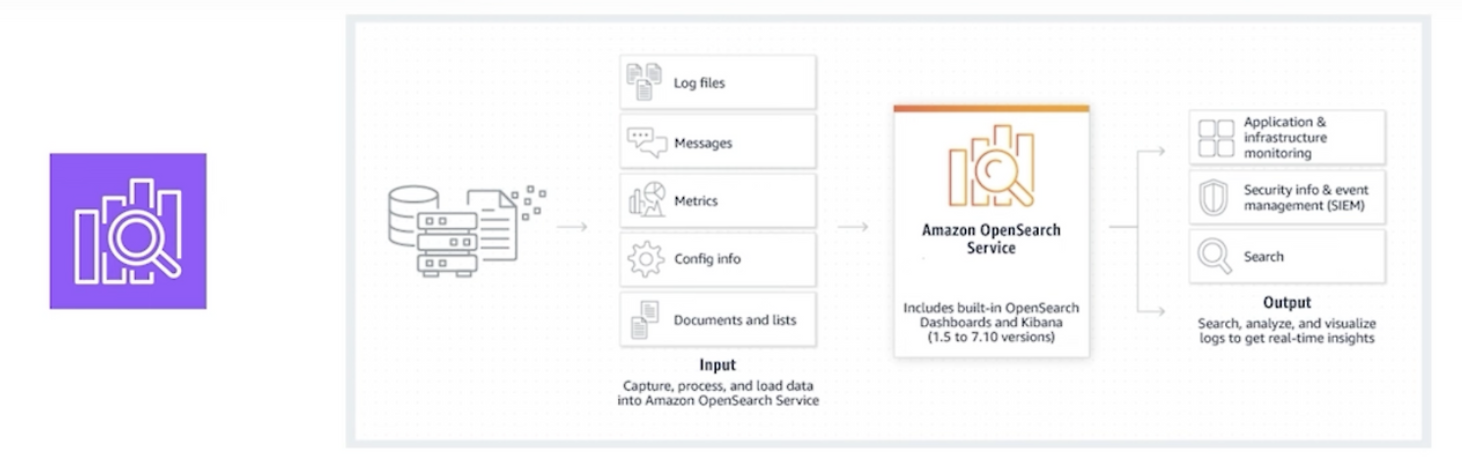
- 클라우드에서 OpenSearch 클러스터를 손쉽게 배포, 운영 및 확장할 수 있도록 해주는 관리형 서비스
- Elasticsearch와 호환되는 서비스로, 대용량 데이터를 색인화하고 검색하며, 실시간으로 데이터 분석이 가능
- 필요에 따라 클러스터의 크기를 조정하고 자동으로 확장하는 아키텍쳐 제공
- 실시간 애플리케이션 모니터링, 로그 분석 및 웹사이트 검색과 같이 다양한 사용 사례에 사용 | 비교 항목 | 일반 데이터베이스 (RDB - 예: MySQL) | OpenSearch (검색 엔진) | | — | — | — | | 핵심 목적 | 데이터의 정확한 저장 및 관리 (무결성) | 데이터의 빠르고 지능적인 검색 및 분석 (검색) | | 검색 원리 | Full Table Scan (전체 스캔) | Inverted Index (역인덱스/색인) | | 비유 | 책을 1페이지부터 끝까지 다 읽어서 단어 찾기 | 책 맨 뒤의 ‘찾아보기(색인)’를 이용해 단어 찾기 | | 검색 속도 | 데이터가 많아질수록 기하급수적으로 느려짐 | 데이터가 수십억 건이 되어도 매우 빠른 속도 유지 | | 검색 품질 | -단순 텍스트 일치만 가능’ -노트북 가방’ 검색 시 ‘노트북 백팩’ 못 찾음 | -관련도 순으로 똑똑하게 정렬 -오타 보정 (‘오픈서치’ -> ‘오픈서치’) -유의어 처리 (‘랩탑’ -> ‘노트북’) -형태소 분석 (‘달리는’ -> ‘달리다’) | | 로그 분석 | -초당 수만 건씩 쏟아지는 로그를 실시간으로 저장하고 검색하기에 부적합 -시스템에 큰 부하를 줌 | 대규모 로그 분석에 최적화 |
AWS QuickSight
- AWS 클라우드 기반의 비즈니스 인텔리전스(BI) 시각화 도구
- 20가지 이상의 차트 형식을 지원하여 데이터의 특성에 맞는 다양한 형식의 시각화 화면 생성 가능
- Athena, S3, RDS, Redshift 등 클라우드 기반 데이터 및 다양한 온프레미스, SaaS 데이터를 연결시켜 시각화 가능
- 실시간 데이터를 분석할 수 있으며,대시보드 및 시각화를 실시간으로 업데이트 가능